 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Expansion-and-Compression Network for Few-shot Class-Incremental Learning
Apr 06, 2021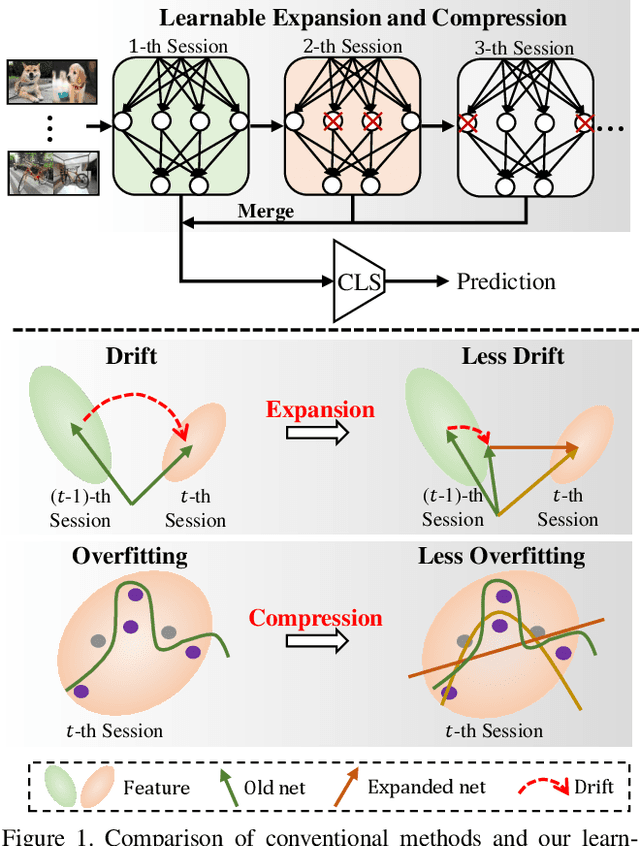
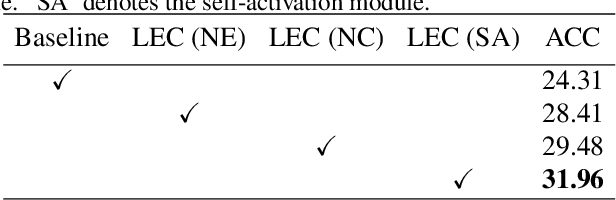
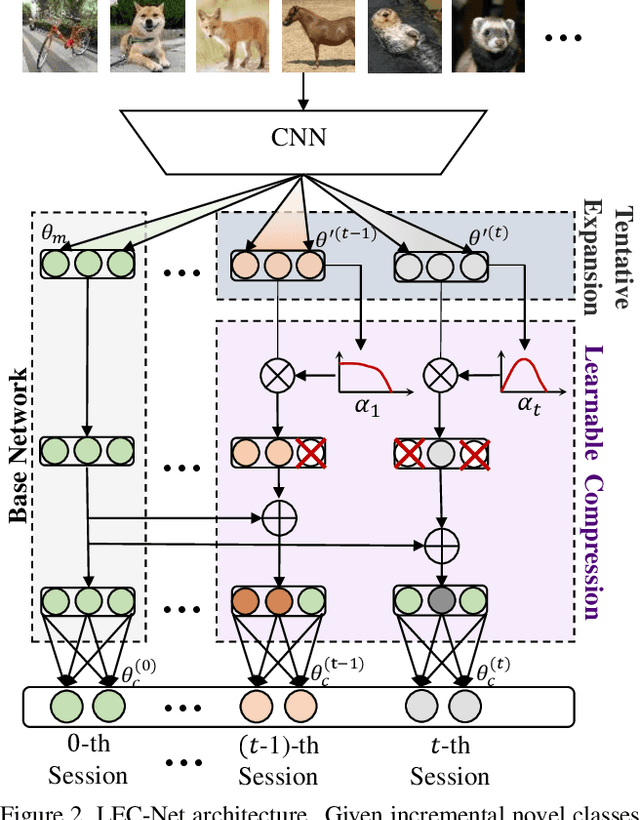
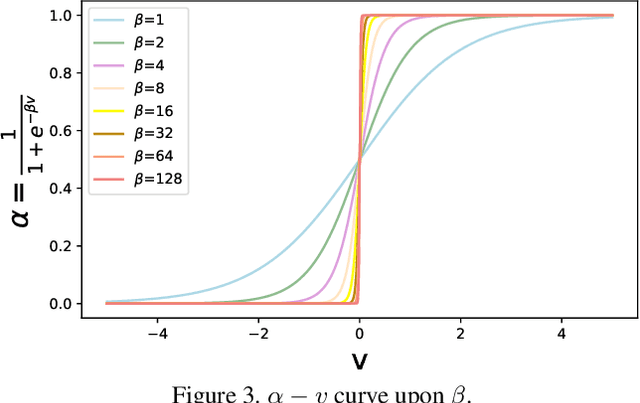
Few-shot class-incremental learning (FSCIL), which targets at continuously expanding model's representation capacity under few supervisions, is an important yet challenging problem. On the one hand, when fitting new tasks (novel classes), features trained on old tasks (old classes) could significantly drift, causing catastrophic forgetting. On the other hand, training the large amount of model parameters with few-shot novel-class examples leads to model over-fitting. In this paper, we propose a learnable expansion-and-compression network (LEC-Net), with the aim to simultaneously solve catastrophic forgetting and model over-fitting problems in a unified framework. By tentatively expanding network nodes, LEC-Net enlarges the representation capacity of features, alleviating feature drift of old network from the perspective of model regularization. By compressing the expanded network nodes, LEC-Net purses minimal increase of model parameters, alleviating over-fitting of the expanded network from a perspective of compact representation. Experiments on the CUB/CIFAR-100 datasets show that LEC-Net improves the baseline by 5~7% while outperforms the state-of-the-art by 5~6%. LEC-Net also demonstrates the potential to be a general incremental learning approach with dynamic model expansion capability.
TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised Object Localization
Mar 27, 2021
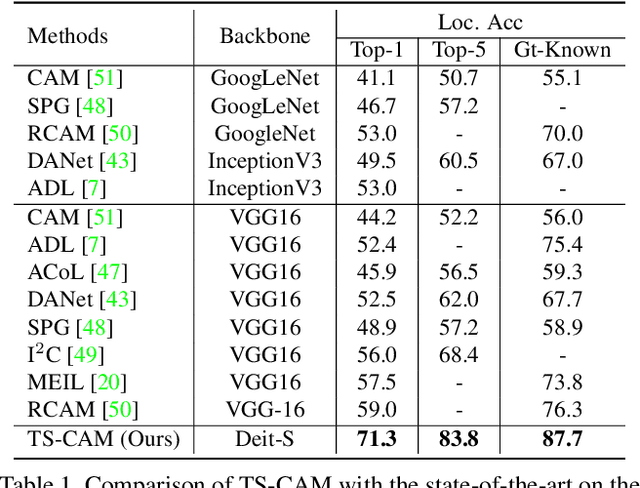
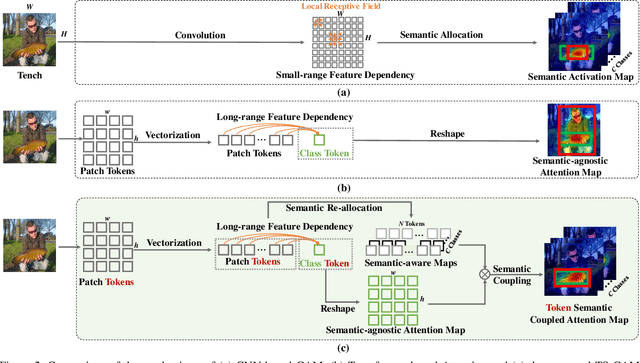
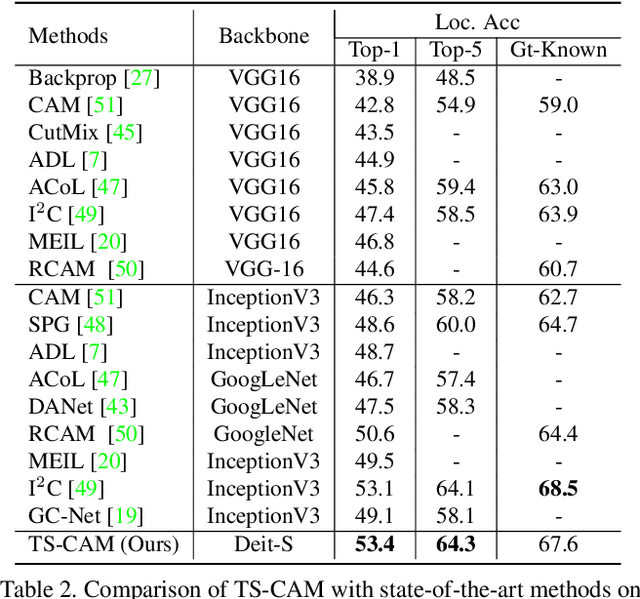
Weakly supervised object localization (WSOL) is a challenging problem when given image category labels but requires to learn object localization models. Optimizing a convolutional neural network (CNN) for classification tends to activate local discriminative regions while ignoring complete object extent, causing the partial activation issue. In this paper, we argue that partial activation is caused by the intrinsic characteristics of CNN, where the convolution operations produce local receptive fields and experience difficulty to capture long-range feature dependency among pixels. We introduce the token semantic coupled attention map (TS-CAM) to take full advantage of the self-attention mechanism in visual transformer for long-range dependency extraction. TS-CAM first splits an image into a sequence of patch tokens for spatial embedding, which produce attention maps of long-range visual dependency to avoid partial activation. TS-CAM then re-allocates category-related semantics for patch tokens, enabling each of them to be aware of object categories. TS-CAM finally couples the patch tokens with the semantic-agnostic attention map to achieve semantic-aware localization. Experiments on the ILSVRC/CUB-200-2011 datasets show that TS-CAM outperforms its CNN-CAM counterparts by 7.1%/27.1% for WSOL, achieving state-of-the-art performance.
Beyond Max-Margin: Class Margin Equilibrium for Few-shot Object Detection
Mar 10, 2021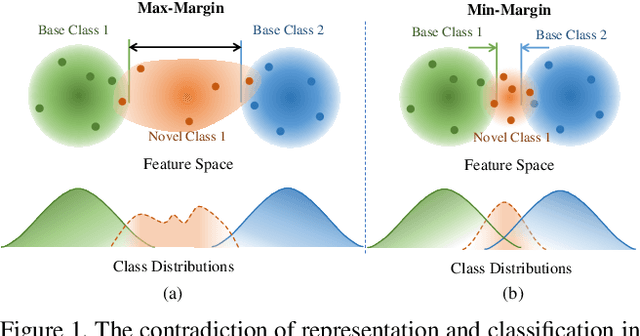
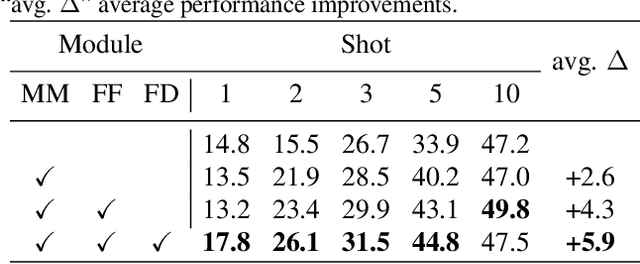
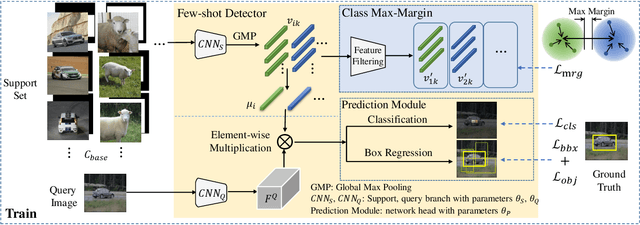
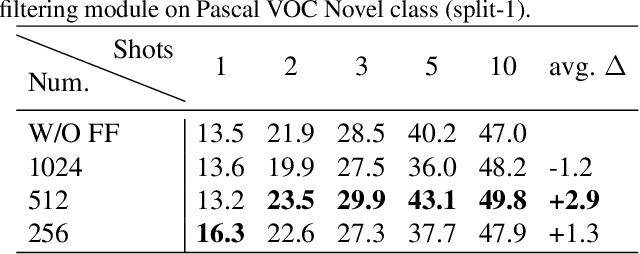
Few-shot object detection has made substantial progressby representing novel class objects using the feature representation learned upon a set of base class objects. However,an implicit contradiction between novel class classification and representation is unfortunately ignored. On the one hand, to achieve accurate novel class classification, the distributions of either two base classes must be far away fromeach other (max-margin). On the other hand, to precisely represent novel classes, the distributions of base classes should be close to each other to reduce the intra-class distance of novel classes (min-margin). In this paper, we propose a class margin equilibrium (CME) approach, with the aim to optimize both feature space partition and novel class reconstruction in a systematic way. CME first converts the few-shot detection problem to the few-shot classification problem by using a fully connected layer to decouple localization features. CME then reserves adequate margin space for novel classes by introducing simple-yet-effective class margin loss during feature learning. Finally, CME pursues margin equilibrium by disturbing the features of novel class instances in an adversarial min-max fashion. Experiments on Pascal VOC and MS-COCO datasets show that CME significantly improves upon two baseline detectors (up to 3 ∼ 5% in average), achieving state-of-the-art performance. Code is available at https://github.com/Bohao-Lee/CME .
Non-Parametric Adaptive Network Pruning
Jan 25, 2021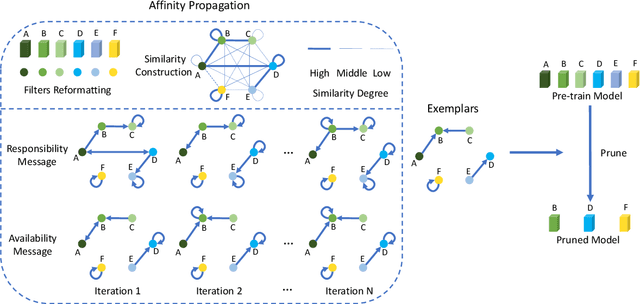
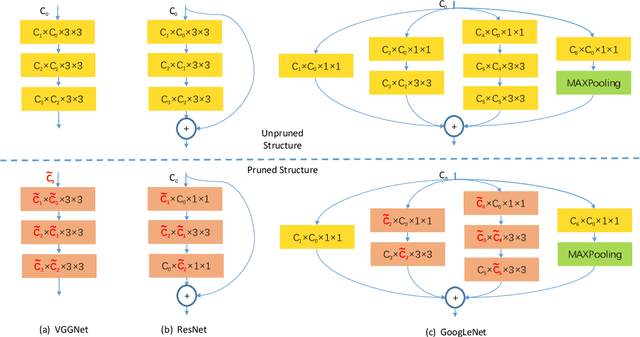
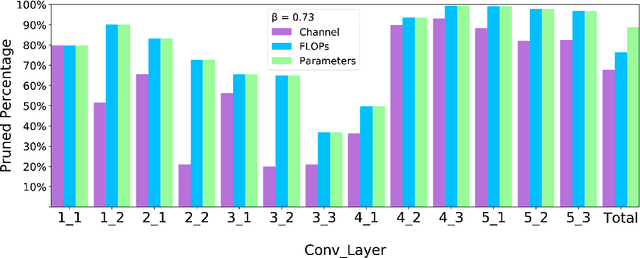
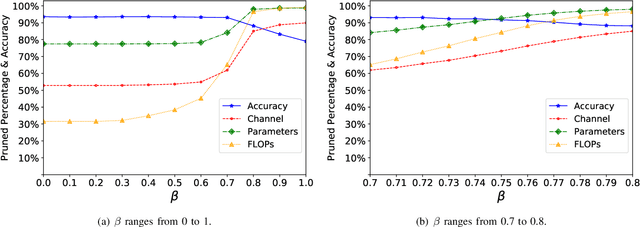
Popular network pruning algorithms reduce redundant information by optimizing hand-crafted parametric models, and may cause suboptimal performance and long time in selecting filters. We innovatively introduce non-parametric modeling to simplify the algorithm design, resulting in an automatic and efficient pruning approach called EPruner. Inspired by the face recognition community, we use a message passing algorithm Affinity Propagation on the weight matrices to obtain an adaptive number of exemplars, which then act as the preserved filters. EPruner breaks the dependency on the training data in determining the "important" filters and allows the CPU implementation in seconds, an order of magnitude faster than GPU based SOTAs. Moreover, we show that the weights of exemplars provide a better initialization for the fine-tuning. On VGGNet-16, EPruner achieves a 76.34%-FLOPs reduction by removing 88.80% parameters, with 0.06% accuracy improvement on CIFAR-10. In ResNet-152, EPruner achieves a 65.12%-FLOPs reduction by removing 64.18% parameters, with only 0.71% top-5 accuracy loss on ILSVRC-2012. Code can be available at https://github.com/lmbxmu/EPruner.
Towards Spatio-Temporal Video Scene Text Detection via Temporal Clustering
Nov 19, 2020
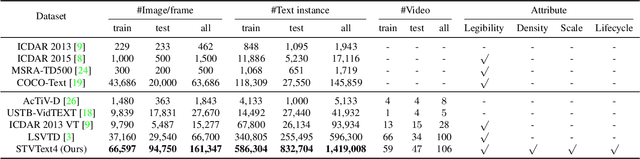
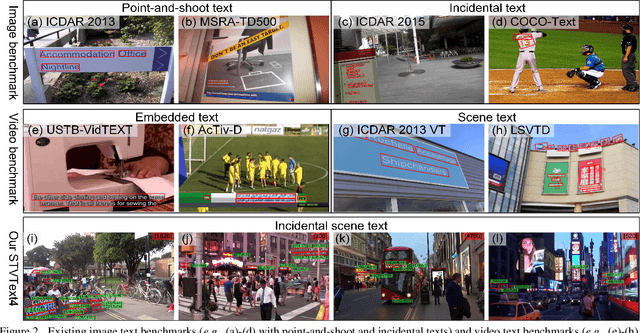
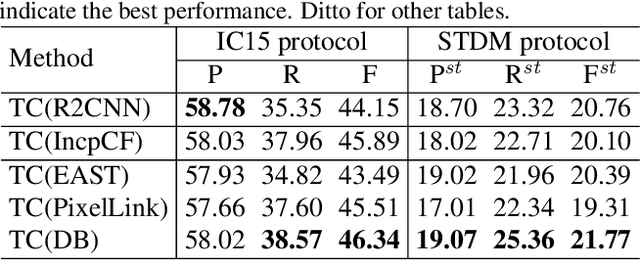
With only bounding-box annotations in the spatial domain, existing video scene text detection (VSTD) benchmarks lack temporal relation of text instances among video frames, which hinders the development of video text-related applications. In this paper, we systematically introduce a new large-scale benchmark, named as STVText4, a well-designed spatial-temporal detection metric (STDM), and a novel clustering-based baseline method, referred to as Temporal Clustering (TC). STVText4 opens a challenging yet promising direction of VSTD, termed as ST-VSTD, which targets at simultaneously detecting video scene texts in both spatial and temporal domains. STVText4 contains more than 1.4 million text instances from 161,347 video frames of 106 videos, where each instance is annotated with not only spatial bounding box and temporal range but also four intrinsic attributes, including legibility, density, scale, and lifecycle, to facilitate the community. With continuous propagation of identical texts in the video sequence, TC can accurately output the spatial quadrilateral and temporal range of the texts, which sets a strong baseline for ST-VSTD. Experiments demonstrate the efficacy of our method and the great academic and practical value of the STVText4. The dataset and code will be available soon.
Adaptive Linear Span Network for Object Skeleton Detection
Nov 08, 2020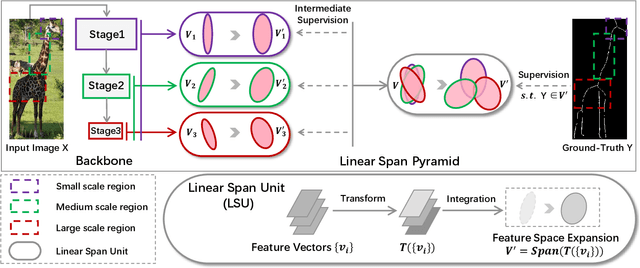
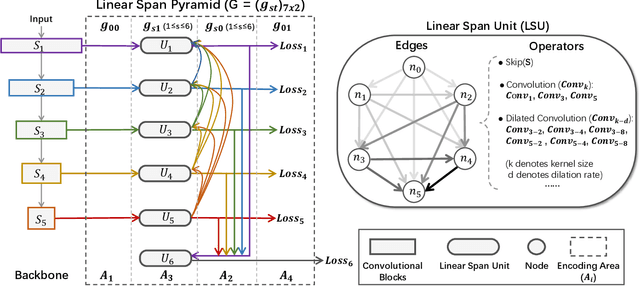
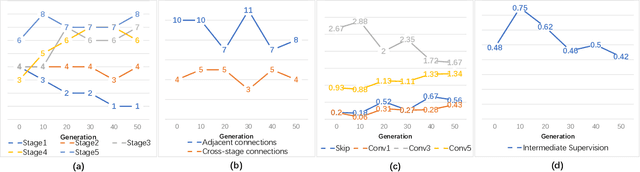

Conventional networks for object skeleton detection are usually hand-crafted. Although effective, they require intensive priori knowledge to configure representative features for objects in different scale granularity.In this paper, we propose adaptive linear span network (AdaLSN), driven by neural architecture search (NAS), to automatically configure and integrate scale-aware features for object skeleton detection. AdaLSN is formulated with the theory of linear span, which provides one of the earliest explanations for multi-scale deep feature fusion. AdaLSN is materialized by defining a mixed unit-pyramid search space, which goes beyond many existing search spaces using unit-level or pyramid-level features.Within the mixed space, we apply genetic architecture search to jointly optimize unit-level operations and pyramid-level connections for adaptive feature space expansion. AdaLSN substantiates its versatility by achieving significantly higher accuracy and latency trade-off compared with state-of-the-arts. It also demonstrates general applicability to image-to-mask tasks such as edge detection and road extraction. Code is available at \href{https://github.com/sunsmarterjie/SDL-Skeleton}{\color{magenta}github.com/sunsmarterjie/SDL-Skeleton}.
The 1st Tiny Object Detection Challenge:Methods and Results
Oct 06, 2020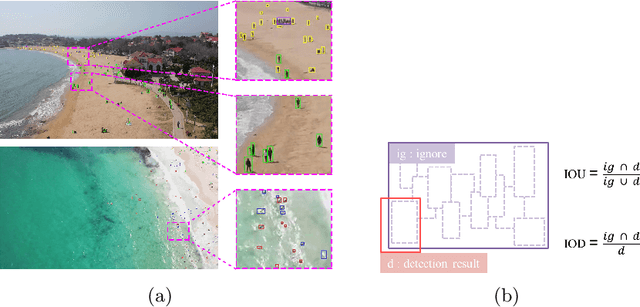
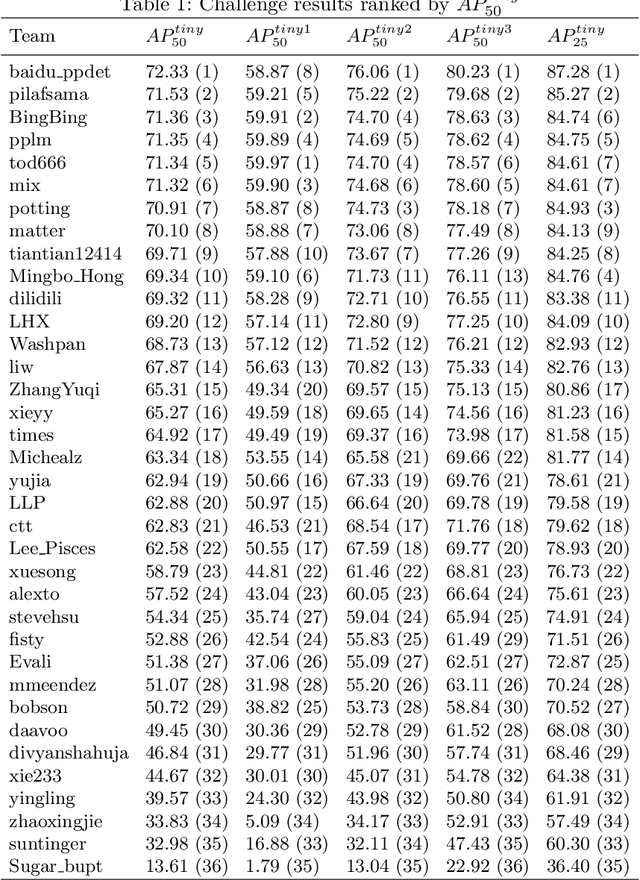
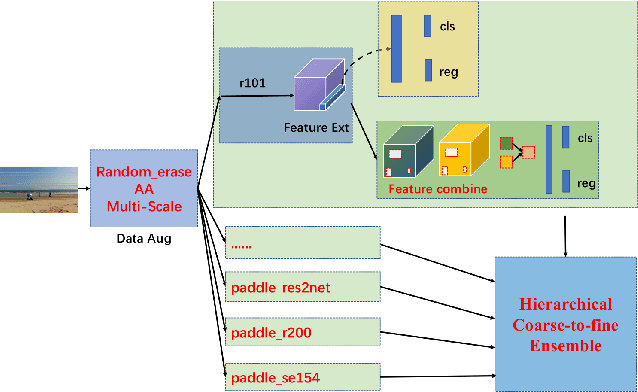

The 1st Tiny Object Detection (TOD) Challenge aims to encourage research in developing novel and accurate methods for tiny object detection in images which have wide views, with a current focus on tiny person detection. The TinyPerson dataset was used for the TOD Challenge and is publicly released. It has 1610 images and 72651 box-levelannotations. Around 36 participating teams from the globe competed inthe 1st TOD Challenge. In this paper, we provide a brief summary of the1st TOD Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that areinterested in the TOD challenge. The benchmark dataset and other information can be found at: https://github.com/ucas-vg/TinyBenchmark.
Prototype Mixture Models for Few-shot Semantic Segmentation
Sep 01, 2020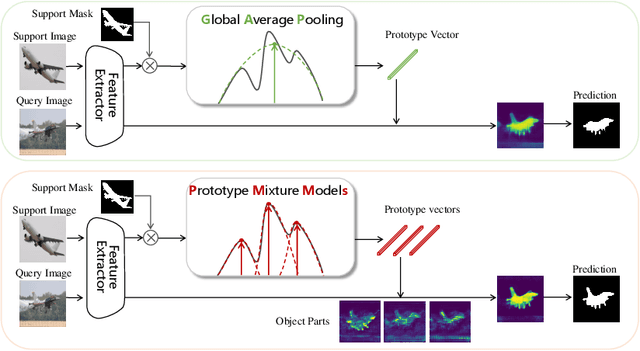

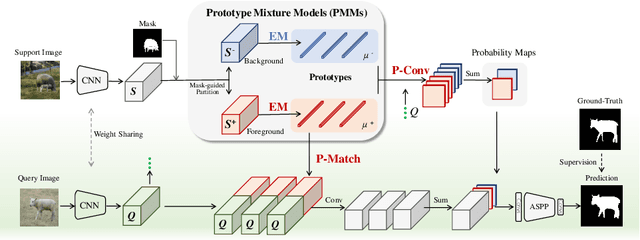
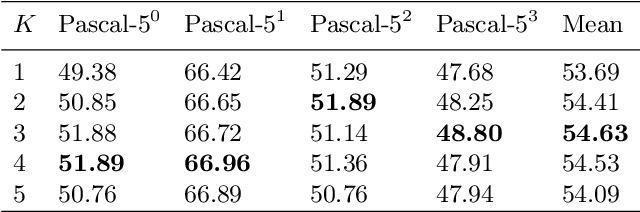
Few-shot segmentation is challenging because objects within the support and query images could significantly differ in appearance and pose. Using a single prototype acquired directly from the support image to segment the query image causes semantic ambiguity. In this paper, we propose prototype mixture models (PMMs), which correlate diverse image regions with multiple prototypes to enforce the prototype-based semantic representation. Estimated by an Expectation-Maximization algorithm, PMMs incorporate rich channel-wised and spatial semantics from limited support images. Utilized as representations as well as classifiers, PMMs fully leverage the semantics to activate objects in the query image while depressing background regions in a duplex manner. Extensive experiments on Pascal VOC and MS-COCO datasets show that PMMs significantly improve upon state-of-the-arts. Particularly, PMMs improve 5-shot segmentation performance on MS-COCO by up to 5.82\% with only a moderate cost for model size and inference speed.
Component Divide-and-Conquer for Real-World Image Super-Resolution
Aug 05, 2020In this paper, we present a large-scale Diverse Real-world image Super-Resolution dataset, i.e., DRealSR, as well as a divide-and-conquer Super-Resolution (SR) network, exploring the utility of guiding SR model with low-level image components. DRealSR establishes a new SR benchmark with diverse real-world degradation processes, mitigating the limitations of conventional simulated image degradation. In general, the targets of SR vary with image regions with different low-level image components, e.g., smoothness preserving for flat regions, sharpening for edges, and detail enhancing for textures. Learning an SR model with conventional pixel-wise loss usually is easily dominated by flat regions and edges, and fails to infer realistic details of complex textures. We propose a Component Divide-and-Conquer (CDC) model and a Gradient-Weighted (GW) loss for SR. Our CDC parses an image with three components, employs three Component-Attentive Blocks (CABs) to learn attentive masks and intermediate SR predictions with an intermediate supervision learning strategy, and trains an SR model following a divide-and-conquer learning principle. Our GW loss also provides a feasible way to balance the difficulties of image components for SR. Extensive experiments validate the superior performance of our CDC and the challenging aspects of our DRealSR dataset related to diverse real-world scenarios. Our dataset and codes are publicly available at https://github.com/xiezw5/Component-Divide-and-Conquer-for-Real-World-Image-Super-Resolution
Learning Task-oriented Disentangled Representations for Unsupervised Domain Adaptation
Jul 27, 2020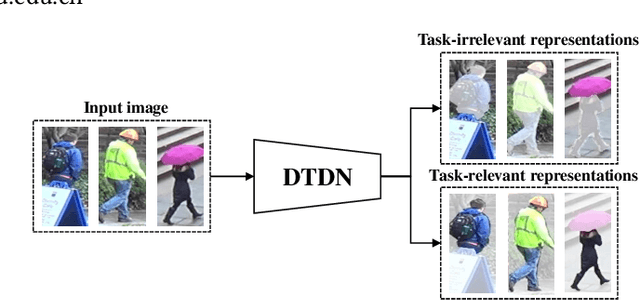
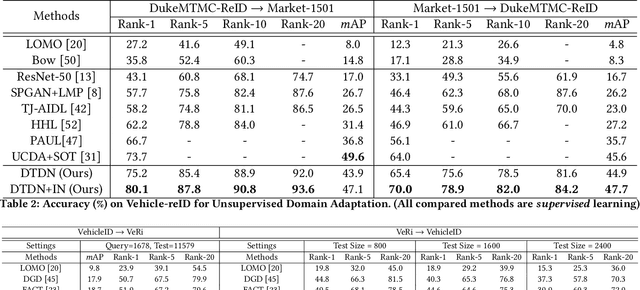
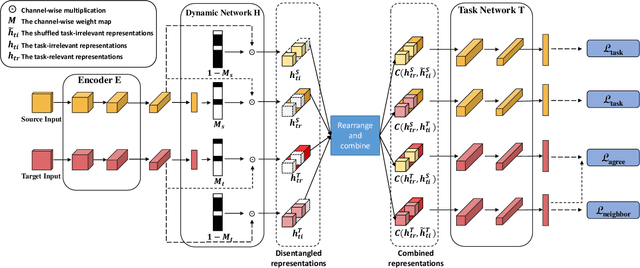
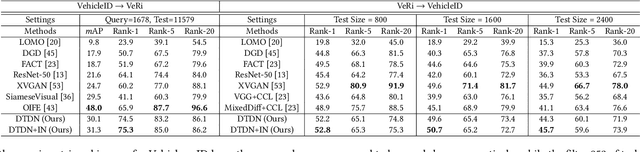
Unsupervised domain adaptation (UDA) aims to address the domain-shift problem between a labeled source domain and an unlabeled target domain. Many efforts have been made to address the mismatch between the distributions of training and testing data, but unfortunately, they ignore the task-oriented information across domains and are inflexible to perform well in complicated open-set scenarios. Many efforts have been made to eliminate the mismatch between the distributions of training and testing data by learning domain-invariant representations. However, the learned representations are usually not task-oriented, i.e., being class-discriminative and domain-transferable simultaneously. This drawback limits the flexibility of UDA in complicated open-set tasks where no labels are shared between domains. In this paper, we break the concept of task-orientation into task-relevance and task-irrelevance, and propose a dynamic task-oriented disentangling network (DTDN) to learn disentangled representations in an end-to-end fashion for UDA. The dynamic disentangling network effectively disentangles data representations into two components: the task-relevant ones embedding critical information associated with the task across domains, and the task-irrelevant ones with the remaining non-transferable or disturbing information. These two components are regularized by a group of task-specific objective functions across domains. Such regularization explicitly encourages disentangling and avoids the use of generative models or decoders. Experiments in complicated, open-set scenarios (retrieval tasks) and empirical benchmarks (classification tasks) demonstrate that the proposed method captures rich disentangled information and achieves superior performance.