 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching AI Through Benchmark Construction: QuestBench as a Course-Based Practice for Accountable Knowledge Work
May 21, 2026As AI becomes part of everyday learning, many courses teach students to use it mainly as a productivity tool: how to prompt, search, summarize, write, code, and use tools more efficiently. We argue that AI education also needs a setting in which students learn to test AI and understand their own role in judging machine-produced knowledge. To this end, we introduce a course-based practice that teaches AI through benchmark construction, using deep research systems as a concrete example of AI-era knowledge work. Students turn disciplinary knowledge into verifiable expert-level questions, review one another's designs for ambiguity and shortcuts, and evaluate AI systems on the resulting tasks. This activity gives students direct exposure to a powerful tool while asking them to specify what a trustworthy answer would require. The produced benchmark, QuestBench, consists of 256 questions across 14 humanities and social-science domains. Evaluation on QuestBench shows that student-designed tasks reveal hidden failures in current deep research systems: across thirteen evaluated systems, the mean question-level pass rate is only 16.85%, and the best-performing system, GPT-5.5, reaches a 57.58% pass rate. The failures are educationally useful because they show how fluent, source-backed answers can still miss the right query, source, term, or evidence standard. Reflections from five student contributors suggest that benchmark construction can help students see professional knowledge not only as content AI may retrieve, but as the basis for judging AI outputs. We present QuestBench as a benchmark artifact and as a reusable classroom setting for a larger educational question: how students can remain responsible knowledge actors as AI enters learning and professional work. The dataset is available at https://huggingface.co/datasets/PKUAIWeb/QuestBench/tree/main.
SGR-Bench: Benchmarking Search Agents on State-Gated Retrieval
May 21, 2026Recent advances in large language models and tool-using agents have expanded the range of benchmarked web tasks. Yet an important class of specialized retrieval tasks remains undercharacterized. On many specialized data-retrieval websites, answer-bearing evidence becomes accessible only after establishing the correct site-specific retrieval state through filters, views, hierarchies, or scopes. We term this capability state-gated retrieval (SGR). We introduce SGR-Bench, a benchmark for this setting containing 100 expert-curated tasks spanning six source families and 12 public data ecosystems. Each task requires discovering the appropriate website and configuring its site-specific retrieval state to produce a structured answer. SGR-Bench pairs constraint-guided and goal-oriented formulations of the same underlying problems, enabling controlled comparisons between explicit and implicit guidance for state-gated retrieval. We evaluate eight CLI-based agentic LLM systems and three commercial search-agent products. On SGR-Bench, the strongest system reaches only 66.18% item-level F1, while row-level F1 remains much lower. A manual audit of 156 analyzable failed CLI trajectories shows why: agents often reach a relevant web source, but establish the wrong site-specific retrieval state. Retrieval-scope drift (37.2%) and criterion mismatch (27.6%) dominate, whereas final answer composition accounts for only 10.3%. The dataset and single-case evaluation instructions are available at https://huggingface.co/datasets/PKUAIWeb/SGR-BENCH.
MindLoom: Composing Thought Modes for Frontier-Level Reasoning Data Synthesis
May 20, 2026Although LLMs have made substantial progress in reasoning, systematically producing frontier-level reasoning data remains difficult. Existing synthesis methods often have limited visibility into the structural factors that govern problem difficulty, which can result in narrow diversity and unstable difficulty control. In this work, we view the difficulty of a reasoning problem as arising from the accumulation of atomic knowledge-reasoning transformations, which we term thought modes. Building on this perspective, we propose MindLoom, a framework for synthesizing frontier-level reasoning data through compositional thought mode engineering. Given a collection of hard problems with verified solutions, MindLoom first decomposes those solutions into thought mode chains that reveal each problem's construction logic. It then trains a retrieval model that matches problem states to compatible thought modes, providing guidance on which reasoning challenges to introduce during synthesis. New problems are composed by iteratively applying retrieved thought modes to seed questions, with distribution-aligned sampling to encourage diverse reasoning coverage. Finally, a rollout-based judging stage labels generated questions by difficulty and supplies judged-correct responses for supervised fine-tuning. We evaluate MindLoom on nine benchmarks covering five STEM disciplines and four mathematical reasoning tasks across multiple model families and sizes. Models fine-tuned on MindLoom-generated data achieves favorable performances over base models, distillation, and external-data baselines across the reported benchmarks. Ablation studies indicate the contribution of each component, and further analysis suggests that MindLoom covers a broad range of reasoning patterns while maintaining useful difficulty control. We have open-sourced our implementation at https://github.com/EachSheep/MindLoom.
Visual Enhanced Depth Scaling for Multimodal Latent Reasoning
Apr 12, 2026Multimodal latent reasoning has emerged as a promising paradigm that replaces explicit Chain-of-Thought (CoT) decoding with implicit feature propagation, simultaneously enhancing representation informativeness and reducing inference latency. By analyzing token-level gradient dynamics during latent training, we reveal two critical observations: (1) visual tokens exhibit significantly higher and more volatile gradient norms than their textual counterparts due to inherent language bias, resulting in systematic visual under-optimization; and (2) semantically simple tokens converge rapidly, whereas complex tokens exhibit persistent gradient instability constrained by fixed architectural depths. To address these limitations, we propose a visual replay module and routing depth scaling to collaboratively enhance visual perception and refine complicated latents for deeper contextual reasoning. The former module leverages causal self-attention to estimate token saliency, reinforcing fine-grained grounding through spatially-coherent constraints. Complementarily, the latter mechanism adaptively allocates additional reasoning steps to complex tokens, enabling deeper contextual refinement. Guided by a curriculum strategy that progressively internalizes explicit CoT into compact latent representations, our framework achieves state-of-the-art performance across diverse benchmarks while delivering substantial inference speedups over explicit CoT baselines.
Stateful Cross-layer Vision Modulation
Feb 28, 2026Recent multimodal large language models (MLLMs) widely adopt multi-layer visual feature fusion to enhance visual representation. However, existing approaches typically perform static concatenation or weighted aggregation after visual encoding, without intervening in the representation formation process itself. As a result, fine-grained details from early layers may be progressively suppressed during hierarchical abstraction. Moreover, directly introducing shallow-layer features into the language model often leads to semantic distribution mismatch with the visual feature space that the LLM's cross-attention layers were pretrained on, which typically requires additional adaptation or fine-tuning of the LLM. To address these limitations, we revisit visual representation learning from the perspective of representation evolution control and propose a cross-layer memory-modulated vision framework(SCVM). Specifically, we introduce a recursively updated cross-layer memory state inside the vision encoder to model long-range inter-layer dependencies. We further design a layer-wise feedback modulation mechanism that refreshes token representations at each layer based on the accumulated memory, thereby structurally regulating the representation evolution trajectory. In addition, we incorporate an auxiliary semantic alignment objective that explicitly supervises the final memory state, encouraging progressive compression and reinforcement of task-relevant information. Experimental results on multiple visual question answering and hallucination evaluation benchmarks demonstrate that SCVM achieves consistent performance improvements without expanding visual tokens, introducing additional vision encoders, or modifying or fine-tuning the language model.
WebSplatter: Enabling Cross-Device Efficient Gaussian Splatting in Web Browsers via WebGPU
Feb 03, 2026We present WebSplatter, an end-to-end GPU rendering pipeline for the heterogeneous web ecosystem. Unlike naive ports, WebSplatter introduces a wait-free hierarchical radix sort that circumvents the lack of global atomics in WebGPU, ensuring deterministic execution across diverse hardware. Furthermore, we propose an opacity-aware geometry culling stage that dynamically prunes splats before rasterization, significantly reducing overdraw and peak memory footprint. Evaluation demonstrates that WebSplatter consistently achieves 1.2$\times$ to 4.5$\times$ speedups over state-of-the-art web viewers.
Content-aware Balanced Spectrum Encoding in Masked Modeling for Time Series Classification
Dec 17, 2024



Due to the superior ability of global dependency, transformer and its variants have become the primary choice in Masked Time-series Modeling (MTM) towards time-series classification task. In this paper, we experimentally analyze that existing transformer-based MTM methods encounter with two under-explored issues when dealing with time series data: (1) they encode features by performing long-dependency ensemble averaging, which easily results in rank collapse and feature homogenization as the layer goes deeper; (2) they exhibit distinct priorities in fitting different frequency components contained in the time-series, inevitably leading to spectrum energy imbalance of encoded feature. To tackle these issues, we propose an auxiliary content-aware balanced decoder (CBD) to optimize the encoding quality in the spectrum space within masked modeling scheme. Specifically, the CBD iterates on a series of fundamental blocks, and thanks to two tailored units, each block could progressively refine the masked representation via adjusting the interaction pattern based on local content variations of time-series and learning to recalibrate the energy distribution across different frequency components. Moreover, a dual-constraint loss is devised to enhance the mutual optimization of vanilla decoder and our CBD. Extensive experimental results on ten time-series classification datasets show that our method nearly surpasses a bunch of baselines. Meanwhile, a series of explanatory results are showcased to sufficiently demystify the behaviors of our method.
DynFocus: Dynamic Cooperative Network Empowers LLMs with Video Understanding
Nov 19, 2024The challenge in LLM-based video understanding lies in preserving visual and semantic information in long videos while maintaining a memory-affordable token count. However, redundancy and correspondence in videos have hindered the performance potential of existing methods. Through statistical learning on current datasets, we observe that redundancy occurs in both repeated and answer-irrelevant frames, and the corresponding frames vary with different questions. This suggests the possibility of adopting dynamic encoding to balance detailed video information preservation with token budget reduction. To this end, we propose a dynamic cooperative network, DynFocus, for memory-efficient video encoding in this paper. Specifically, i) a Dynamic Event Prototype Estimation (DPE) module to dynamically select meaningful frames for question answering; (ii) a Compact Cooperative Encoding (CCE) module that encodes meaningful frames with detailed visual appearance and the remaining frames with sketchy perception separately. We evaluate our method on five publicly available benchmarks, and experimental results consistently demonstrate that our method achieves competitive performance.
LLM-Powered Test Case Generation for Detecting Tricky Bugs
Apr 16, 2024



Conventional automated test generation tools struggle to generate test oracles and tricky bug-revealing test inputs. Large Language Models (LLMs) can be prompted to produce test inputs and oracles for a program directly, but the precision of the tests can be very low for complex scenarios (only 6.3% based on our experiments). To fill this gap, this paper proposes AID, which combines LLMs with differential testing to generate fault-revealing test inputs and oracles targeting plausibly correct programs (i.e., programs that have passed all the existing tests). In particular, AID selects test inputs that yield diverse outputs on a set of program variants generated by LLMs, then constructs the test oracle based on the outputs. We evaluate AID on two large-scale datasets with tricky bugs: TrickyBugs and EvalPlus, and compare it with three state-of-the-art baselines. The evaluation results show that the recall, precision, and F1 score of AID outperform the state-of-the-art by up to 1.80x, 2.65x, and 1.66x, respectively.
DeFL: Decentralized Weight Aggregation for Cross-silo Federated Learning
Aug 01, 2022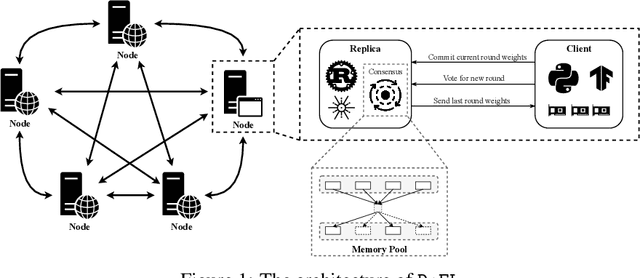
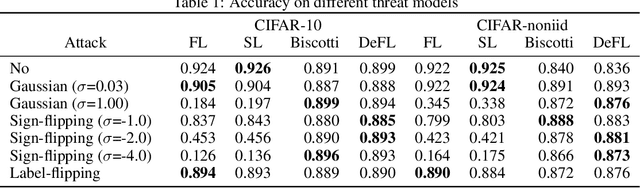
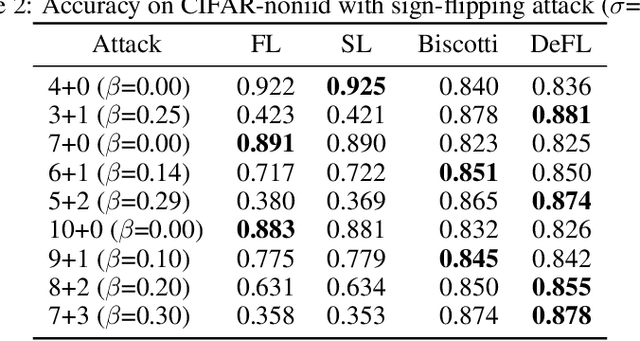
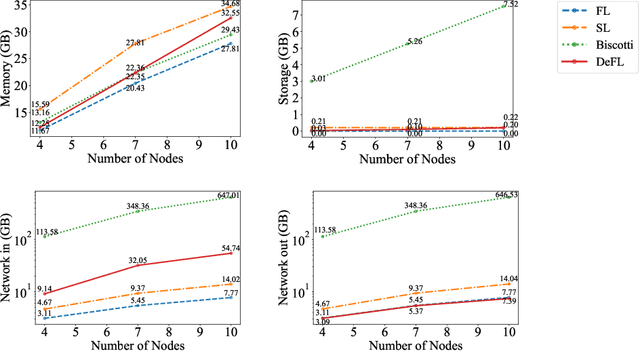
Federated learning (FL) is an emerging promising paradigm of privacy-preserving machine learning (ML). An important type of FL is cross-silo FL, which enables a small scale of organizations to cooperatively train a shared model by keeping confidential data locally and aggregating weights on a central parameter server. However, the central server may be vulnerable to malicious attacks or software failures in practice. To address this issue, in this paper, we propose DeFL, a novel decentralized weight aggregation framework for cross-silo FL. DeFL eliminates the central server by aggregating weights on each participating node and weights of only the current training round are maintained and synchronized among all nodes. We use Multi-Krum to enable aggregating correct weights from honest nodes and use HotStuff to ensure the consistency of the training round number and weights among all nodes. Besides, we theoretically analyze the Byzantine fault tolerance, convergence, and complexity of DeFL. We conduct extensive experiments over two widely-adopted public datasets, i.e. CIFAR-10 and Sentiment140, to evaluate the performance of DeFL. Results show that DeFL defends against common threat models with minimal accuracy loss, and achieves up to 100x reduction in storage overhead and up to 12x reduction in network overhead, compared to state-of-the-art decentralized FL approaches.