 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating Intrinsic Ambiguity from Estimation Uncertainty in Deep Generative Models for Linear Inverse Problems
May 14, 2026Recently, deep generative models have been used for posterior inference in inverse problems, including high-stakes applications in medical imaging and scientific discovery, where the uncertainty of a prediction can matter as much as the prediction itself. However, posterior uncertainty is difficult to interpret because it can mix ambiguity inherent to the forward operator with uncertainty propagated through inference. We introduce a structural decomposition of posterior uncertainty that isolates intrinsic ambiguity. A cascade formulation makes this ambiguity accessible for calibration analysis, enabling qualitative diagnostics and simulation-based calibration tests that reveal failure modes that remain hidden when models are selected by reconstruction quality alone. We first validate the approach on a Gaussian example with analytical posterior structure, then illustrate the decomposition on accelerated magnetic resonance imaging (MRI), and finally apply the calibration diagnostics to electroencephalography (EEG) source imaging.
Enjoy Your Layer Normalization with the Computational Efficiency of RMSNorm
May 14, 2026Layer normalization (LN) is a fundamental component in modern deep learning, but its per-sample centering and scaling introduce non-negligible inference overhead. RMSNorm improves efficiency by removing the centering operation, yet this may discard benefits associated with centering. This paper propose a framework to determine whether an LN in an arbitrary DNN can be replaced by RMSNorm without changing the model function. The key idea is to fold LN's centering operation into upstream general linear layers by enforcing zero-mean outputs through the column-centered constraint (CCC) and column-based weight centering (CBWC). We extend the analysis to arbitrary DNNs, define such LNs as foldable LNs, and develop a graph-based detection algorithm. Our analysis shows that many LNs in widely used architectures are foldable, enabling exact inference-time conversion and end-to-end acceleration of 2% to 12% without changing model predictions. Experiments across multiple task families further show that, when exact equivalence is partially broken in practical training settings, our method remains competitive with vanilla LN while improving efficiency.
UniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions
Apr 24, 2026Generative audio modeling has largely been fragmented into specialized tasks, text-to-speech (TTS), text-to-music (TTM), and text-to-audio (TTA), each operating under heterogeneous control paradigms. Unifying these modalities remains a fundamental challenge due to the intrinsic dissonance between structured semantic representations (speech/music) and unstructured acoustic textures (sound effects). In this paper, we introduce UniSonate, a unified flow-matching framework capable of synthesizing speech, music, and sound effects through a standardized, reference-free natural language instruction interface. To reconcile structural disparities, we propose a novel dynamic token injection mechanism that projects unstructured environmental sounds into a structured temporal latent space, enabling precise duration control within a phoneme-driven Multimodal Diffusion Transformer (MM-DiT). Coupled with a multi-stage curriculum learning strategy, this approach effectively mitigates cross-modal optimization conflicts. Extensive experiments demonstrate that UniSonate achieves state-of-the-art performance in instruction-based TTS (WER 1.47%) and TTM (SongEval Coherence 3.18), while maintaining competitive fidelity in TTA. Crucially, we observe positive transfer, where joint training on diverse audio data significantly enhances structural coherence and prosodic expressiveness compared to single-task baselines. Audio samples are available at https://qiangchunyu.github.io/UniSonate/.
GraphWalker: Graph-Guided In-Context Learning for Clinical Reasoning on Electronic Health Records
Apr 08, 2026Clinical Reasoning on Electronic Health Records (EHRs) is a fundamental yet challenging task in modern healthcare. While in-context learning (ICL) offers a promising inference-time adaptation paradigm for large language models (LLMs) in EHR reasoning, existing methods face three fundamental challenges: (1) Perspective Limitation, where data-driven similarity fails to align with LLM reasoning needs and model-driven signals are constrained by limited clinical competence; (2) Cohort Awareness, as demonstrations are selected independently without modeling population-level structure; and (3) Information Aggregation, where redundancy and interaction effects among demonstrations are ignored, leading to diminishing marginal gains. To address these challenges, we propose GraphWalker, a principled demonstration selection framework for EHR-oriented ICL. GraphWalker (i) jointly models patient clinical information and LLM-estimated information gain by integrating data-driven and model-driven perspectives, (ii) incorporates Cohort Discovery to avoid noisy local optima, and (iii) employs a Lazy Greedy Search with Frontier Expansion algorithm to mitigate diminishing marginal returns in information aggregation. Extensive experiments on multiple real-world EHR benchmarks demonstrate that GraphWalker consistently outperforms state-of-the-art ICL baselines, yielding substantial improvements in clinical reasoning performance. Our code is open-sourced at https://github.com/PuppyKnightUniversity/GraphWalker
From Single Scan to Sequential Consistency: A New Paradigm for LIDAR Relocalization
Feb 03, 2026LiDAR relocalization aims to estimate the global 6-DoF pose of a sensor in the environment. However, existing regression-based approaches are prone to dynamic or ambiguous scenarios, as they either solely rely on single-frame inference or neglect the spatio-temporal consistency across scans. In this paper, we propose TempLoc, a new LiDAR relocalization framework that enhances the robustness of localization by effectively modeling sequential consistency. Specifically, a Global Coordinate Estimation module is first introduced to predict point-wise global coordinates and associated uncertainties for each LiDAR scan. A Prior Coordinate Generation module is then presented to estimate inter-frame point correspondences by the attention mechanism. Lastly, an Uncertainty-Guided Coordinate Fusion module is deployed to integrate both predictions of point correspondence in an end-to-end fashion, yielding a more temporally consistent and accurate global 6-DoF pose. Experimental results on the NCLT and Oxford Robot-Car benchmarks show that our TempLoc outperforms stateof-the-art methods by a large margin, demonstrating the effectiveness of temporal-aware correspondence modeling in LiDAR relocalization. Our code will be released soon.
MM-Sonate: Multimodal Controllable Audio-Video Generation with Zero-Shot Voice Cloning
Jan 08, 2026Joint audio-video generation aims to synthesize synchronized multisensory content, yet current unified models struggle with fine-grained acoustic control, particularly for identity-preserving speech. Existing approaches either suffer from temporal misalignment due to cascaded generation or lack the capability to perform zero-shot voice cloning within a joint synthesis framework. In this work, we present MM-Sonate, a multimodal flow-matching framework that unifies controllable audio-video joint generation with zero-shot voice cloning capabilities. Unlike prior works that rely on coarse semantic descriptions, MM-Sonate utilizes a unified instruction-phoneme input to enforce strict linguistic and temporal alignment. To enable zero-shot voice cloning, we introduce a timbre injection mechanism that effectively decouples speaker identity from linguistic content. Furthermore, addressing the limitations of standard classifier-free guidance in multimodal settings, we propose a noise-based negative conditioning strategy that utilizes natural noise priors to significantly enhance acoustic fidelity. Empirical evaluations demonstrate that MM-Sonate establishes new state-of-the-art performance in joint generation benchmarks, significantly outperforming baselines in lip synchronization and speech intelligibility, while achieving voice cloning fidelity comparable to specialized Text-to-Speech systems.
Klear: Unified Multi-Task Audio-Video Joint Generation
Jan 07, 2026Audio-video joint generation has progressed rapidly, yet substantial challenges still remain. Non-commercial approaches still suffer audio-visual asynchrony, poor lip-speech alignment, and unimodal degradation, which can be stemmed from weak audio-visual correspondence modeling, limited generalization, and scarce high-quality dense-caption data. To address these issues, we introduce Klear and delve into three axes--model architecture, training strategy, and data curation. Architecturally, we adopt a single-tower design with unified DiT blocks and an Omni-Full Attention mechanism, achieving tight audio-visual alignment and strong scalability. Training-wise, we adopt a progressive multitask regime--random modality masking to joint optimization across tasks, and a multistage curriculum, yielding robust representations, strengthening A-V aligned world knowledge, and preventing unimodal collapse. For datasets, we present the first large-scale audio-video dataset with dense captions, and introduce a novel automated data-construction pipeline which annotates and filters millions of diverse, high-quality, strictly aligned audio-video-caption triplets. Building on this, Klear scales to large datasets, delivering high-fidelity, semantically and temporally aligned, instruction-following generation in both joint and unimodal settings while generalizing robustly to out-of-distribution scenarios. Across tasks, it substantially outperforms prior methods by a large margin and achieves performance comparable to Veo 3, offering a unified, scalable path toward next-generation audio-video synthesis.
CVD-STORM: Cross-View Video Diffusion with Spatial-Temporal Reconstruction Model for Autonomous Driving
Oct 09, 2025Generative models have been widely applied to world modeling for environment simulation and future state prediction. With advancements in autonomous driving, there is a growing demand not only for high-fidelity video generation under various controls, but also for producing diverse and meaningful information such as depth estimation. To address this, we propose CVD-STORM, a cross-view video diffusion model utilizing a spatial-temporal reconstruction Variational Autoencoder (VAE) that generates long-term, multi-view videos with 4D reconstruction capabilities under various control inputs. Our approach first fine-tunes the VAE with an auxiliary 4D reconstruction task, enhancing its ability to encode 3D structures and temporal dynamics. Subsequently, we integrate this VAE into the video diffusion process to significantly improve generation quality. Experimental results demonstrate that our model achieves substantial improvements in both FID and FVD metrics. Additionally, the jointly-trained Gaussian Splatting Decoder effectively reconstructs dynamic scenes, providing valuable geometric information for comprehensive scene understanding.
AudioStory: Generating Long-Form Narrative Audio with Large Language Models
Aug 27, 2025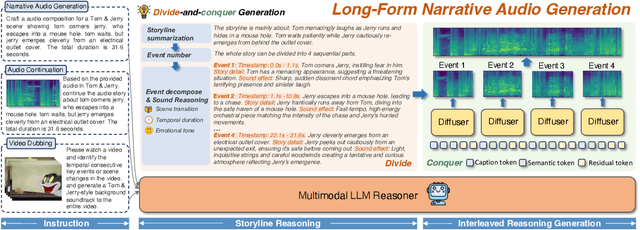
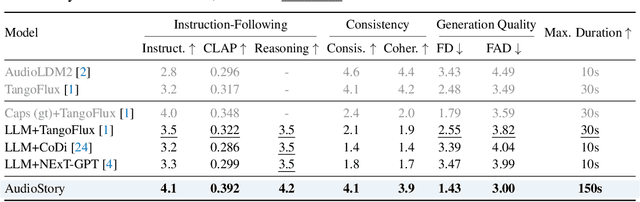
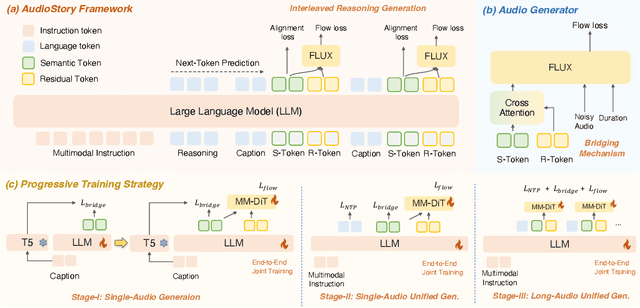

Recent advances in text-to-audio (TTA) generation excel at synthesizing short audio clips but struggle with long-form narrative audio, which requires temporal coherence and compositional reasoning. To address this gap, we propose AudioStory, a unified framework that integrates large language models (LLMs) with TTA systems to generate structured, long-form audio narratives. AudioStory possesses strong instruction-following reasoning generation capabilities. It employs LLMs to decompose complex narrative queries into temporally ordered sub-tasks with contextual cues, enabling coherent scene transitions and emotional tone consistency. AudioStory has two appealing features: (1) Decoupled bridging mechanism: AudioStory disentangles LLM-diffuser collaboration into two specialized components, i.e., a bridging query for intra-event semantic alignment and a residual query for cross-event coherence preservation. (2) End-to-end training: By unifying instruction comprehension and audio generation within a single end-to-end framework, AudioStory eliminates the need for modular training pipelines while enhancing synergy between components. Furthermore, we establish a benchmark AudioStory-10K, encompassing diverse domains such as animated soundscapes and natural sound narratives. Extensive experiments show the superiority of AudioStory on both single-audio generation and narrative audio generation, surpassing prior TTA baselines in both instruction-following ability and audio fidelity. Our code is available at https://github.com/TencentARC/AudioStory
ReasonPlan: Unified Scene Prediction and Decision Reasoning for Closed-loop Autonomous Driving
May 26, 2025Due to the powerful vision-language reasoning and generalization abilities, multimodal large language models (MLLMs) have garnered significant attention in the field of end-to-end (E2E) autonomous driving. However, their application to closed-loop systems remains underexplored, and current MLLM-based methods have not shown clear superiority to mainstream E2E imitation learning approaches. In this work, we propose ReasonPlan, a novel MLLM fine-tuning framework designed for closed-loop driving through holistic reasoning with a self-supervised Next Scene Prediction task and supervised Decision Chain-of-Thought process. This dual mechanism encourages the model to align visual representations with actionable driving context, while promoting interpretable and causally grounded decision making. We curate a planning-oriented decision reasoning dataset, namely PDR, comprising 210k diverse and high-quality samples. Our method outperforms the mainstream E2E imitation learning method by a large margin of 19% L2 and 16.1 driving score on Bench2Drive benchmark. Furthermore, ReasonPlan demonstrates strong zero-shot generalization on unseen DOS benchmark, highlighting its adaptability in handling zero-shot corner cases. Code and dataset will be found in https://github.com/Liuxueyi/ReasonPlan.