 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSRNav: Reasoning Spatial Relationship for Image-Goal Navigation
Apr 25, 2025



Recent image-goal navigation (ImageNav) methods learn a perception-action policy by separately capturing semantic features of the goal and egocentric images, then passing them to a policy network. However, challenges remain: (1) Semantic features often fail to provide accurate directional information, leading to superfluous actions, and (2) performance drops significantly when viewpoint inconsistencies arise between training and application. To address these challenges, we propose RSRNav, a simple yet effective method that reasons spatial relationships between the goal and current observations as navigation guidance. Specifically, we model the spatial relationship by constructing correlations between the goal and current observations, which are then passed to the policy network for action prediction. These correlations are progressively refined using fine-grained cross-correlation and direction-aware correlation for more precise navigation. Extensive evaluation of RSRNav on three benchmark datasets demonstrates superior navigation performance, particularly in the "user-matched goal" setting, highlighting its potential for real-world applications.
From Mapping to Composing: A Two-Stage Framework for Zero-shot Composed Image Retrieval
Apr 25, 2025Composed Image Retrieval (CIR) is a challenging multimodal task that retrieves a target image based on a reference image and accompanying modification text. Due to the high cost of annotating CIR triplet datasets, zero-shot (ZS) CIR has gained traction as a promising alternative. Existing studies mainly focus on projection-based methods, which map an image to a single pseudo-word token. However, these methods face three critical challenges: (1) insufficient pseudo-word token representation capacity, (2) discrepancies between training and inference phases, and (3) reliance on large-scale synthetic data. To address these issues, we propose a two-stage framework where the training is accomplished from mapping to composing. In the first stage, we enhance image-to-pseudo-word token learning by introducing a visual semantic injection module and a soft text alignment objective, enabling the token to capture richer and fine-grained image information. In the second stage, we optimize the text encoder using a small amount of synthetic triplet data, enabling it to effectively extract compositional semantics by combining pseudo-word tokens with modification text for accurate target image retrieval. The strong visual-to-pseudo mapping established in the first stage provides a solid foundation for the second stage, making our approach compatible with both high- and low-quality synthetic data, and capable of achieving significant performance gains with only a small amount of synthetic data. Extensive experiments were conducted on three public datasets, achieving superior performance compared to existing approaches.
Moment Quantization for Video Temporal Grounding
Apr 03, 2025



Video temporal grounding is a critical video understanding task, which aims to localize moments relevant to a language description. The challenge of this task lies in distinguishing relevant and irrelevant moments. Previous methods focused on learning continuous features exhibit weak differentiation between foreground and background features. In this paper, we propose a novel Moment-Quantization based Video Temporal Grounding method (MQVTG), which quantizes the input video into various discrete vectors to enhance the discrimination between relevant and irrelevant moments. Specifically, MQVTG maintains a learnable moment codebook, where each video moment matches a codeword. Considering the visual diversity, i.e., various visual expressions for the same moment, MQVTG treats moment-codeword matching as a clustering process without using discrete vectors, avoiding the loss of useful information from direct hard quantization. Additionally, we employ effective prior-initialization and joint-projection strategies to enhance the maintained moment codebook. With its simple implementation, the proposed method can be integrated into existing temporal grounding models as a plug-and-play component. Extensive experiments on six popular benchmarks demonstrate the effectiveness and generalizability of MQVTG, significantly outperforming state-of-the-art methods. Further qualitative analysis shows that our method effectively groups relevant features and separates irrelevant ones, aligning with our goal of enhancing discrimination.
Referencing Where to Focus: Improving VisualGrounding with Referential Query
Dec 26, 2024



Visual Grounding aims to localize the referring object in an image given a natural language expression. Recent advancements in DETR-based visual grounding methods have attracted considerable attention, as they directly predict the coordinates of the target object without relying on additional efforts, such as pre-generated proposal candidates or pre-defined anchor boxes. However, existing research primarily focuses on designing stronger multi-modal decoder, which typically generates learnable queries by random initialization or by using linguistic embeddings. This vanilla query generation approach inevitably increases the learning difficulty for the model, as it does not involve any target-related information at the beginning of decoding. Furthermore, they only use the deepest image feature during the query learning process, overlooking the importance of features from other levels. To address these issues, we propose a novel approach, called RefFormer. It consists of the query adaption module that can be seamlessly integrated into CLIP and generate the referential query to provide the prior context for decoder, along with a task-specific decoder. By incorporating the referential query into the decoder, we can effectively mitigate the learning difficulty of the decoder, and accurately concentrate on the target object. Additionally, our proposed query adaption module can also act as an adapter, preserving the rich knowledge within CLIP without the need to tune the parameters of the backbone network. Extensive experiments demonstrate the effectiveness and efficiency of our proposed method, outperforming state-of-the-art approaches on five visual grounding benchmarks.
Multimodal LLM Enhanced Cross-lingual Cross-modal Retrieval
Sep 30, 2024



Cross-lingual cross-modal retrieval (CCR) aims to retrieve visually relevant content based on non-English queries, without relying on human-labeled cross-modal data pairs during training. One popular approach involves utilizing machine translation (MT) to create pseudo-parallel data pairs, establishing correspondence between visual and non-English textual data. However, aligning their representations poses challenges due to the significant semantic gap between vision and text, as well as the lower quality of non-English representations caused by pre-trained encoders and data noise. To overcome these challenges, we propose LECCR, a novel solution that incorporates the multi-modal large language model (MLLM) to improve the alignment between visual and non-English representations. Specifically, we first employ MLLM to generate detailed visual content descriptions and aggregate them into multi-view semantic slots that encapsulate different semantics. Then, we take these semantic slots as internal features and leverage them to interact with the visual features. By doing so, we enhance the semantic information within the visual features, narrowing the semantic gap between modalities and generating local visual semantics for subsequent multi-level matching. Additionally, to further enhance the alignment between visual and non-English features, we introduce softened matching under English guidance. This approach provides more comprehensive and reliable inter-modal correspondences between visual and non-English features. Extensive experiments on four CCR benchmarks, \ie Multi30K, MSCOCO, VATEX, and MSR-VTT-CN, demonstrate the effectiveness of our proposed method. Code: \url{https://github.com/LiJiaBei-7/leccr}.
Diversifying Query: Region-Guided Transformer for Temporal Sentence Grounding
May 31, 2024



Temporal sentence grounding is a challenging task that aims to localize the moment spans relevant to a language description. Although recent DETR-based models have achieved notable progress by leveraging multiple learnable moment queries, they suffer from overlapped and redundant proposals, leading to inaccurate predictions. We attribute this limitation to the lack of task-related guidance for the learnable queries to serve a specific mode. Furthermore, the complex solution space generated by variable and open-vocabulary language descriptions exacerbates the optimization difficulty, making it harder for learnable queries to distinguish each other adaptively. To tackle this limitation, we present a Region-Guided TRansformer (RGTR) for temporal sentence grounding, which diversifies moment queries to eliminate overlapped and redundant predictions. Instead of using learnable queries, RGTR adopts a set of anchor pairs as moment queries to introduce explicit regional guidance. Each anchor pair takes charge of moment prediction for a specific temporal region, which reduces the optimization difficulty and ensures the diversity of the final predictions. In addition, we design an IoU-aware scoring head to improve proposal quality. Extensive experiments demonstrate the effectiveness of RGTR, outperforming state-of-the-art methods on QVHighlights, Charades-STA and TACoS datasets.
CL2CM: Improving Cross-Lingual Cross-Modal Retrieval via Cross-Lingual Knowledge Transfer
Dec 14, 2023



Cross-lingual cross-modal retrieval has garnered increasing attention recently, which aims to achieve the alignment between vision and target language (V-T) without using any annotated V-T data pairs. Current methods employ machine translation (MT) to construct pseudo-parallel data pairs, which are then used to learn a multi-lingual and multi-modal embedding space that aligns visual and target-language representations. However, the large heterogeneous gap between vision and text, along with the noise present in target language translations, poses significant challenges in effectively aligning their representations. To address these challenges, we propose a general framework, Cross-Lingual to Cross-Modal (CL2CM), which improves the alignment between vision and target language using cross-lingual transfer. This approach allows us to fully leverage the merits of multi-lingual pre-trained models (e.g., mBERT) and the benefits of the same modality structure, i.e., smaller gap, to provide reliable and comprehensive semantic correspondence (knowledge) for the cross-modal network. We evaluate our proposed approach on two multilingual image-text datasets, Multi30K and MSCOCO, and one video-text dataset, VATEX. The results clearly demonstrate the effectiveness of our proposed method and its high potential for large-scale retrieval.
Dual-view Curricular Optimal Transport for Cross-lingual Cross-modal Retrieval
Sep 11, 2023Current research on cross-modal retrieval is mostly English-oriented, as the availability of a large number of English-oriented human-labeled vision-language corpora. In order to break the limit of non-English labeled data, cross-lingual cross-modal retrieval (CCR) has attracted increasing attention. Most CCR methods construct pseudo-parallel vision-language corpora via Machine Translation (MT) to achieve cross-lingual transfer. However, the translated sentences from MT are generally imperfect in describing the corresponding visual contents. Improperly assuming the pseudo-parallel data are correctly correlated will make the networks overfit to the noisy correspondence. Therefore, we propose Dual-view Curricular Optimal Transport (DCOT) to learn with noisy correspondence in CCR. In particular, we quantify the confidence of the sample pair correlation with optimal transport theory from both the cross-lingual and cross-modal views, and design dual-view curriculum learning to dynamically model the transportation costs according to the learning stage of the two views. Extensive experiments are conducted on two multilingual image-text datasets and one video-text dataset, and the results demonstrate the effectiveness and robustness of the proposed method. Besides, our proposed method also shows a good expansibility to cross-lingual image-text baselines and a decent generalization on out-of-domain data.
Cross-Lingual Cross-Modal Retrieval with Noise-Robust Learning
Aug 26, 2022
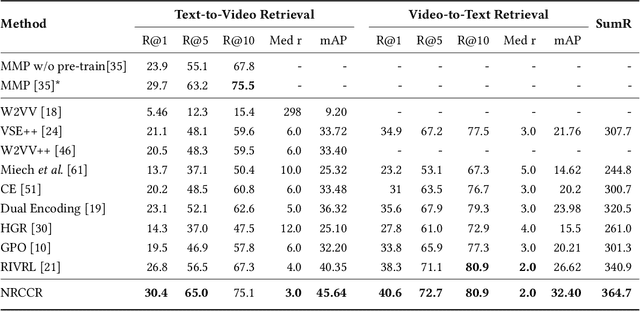
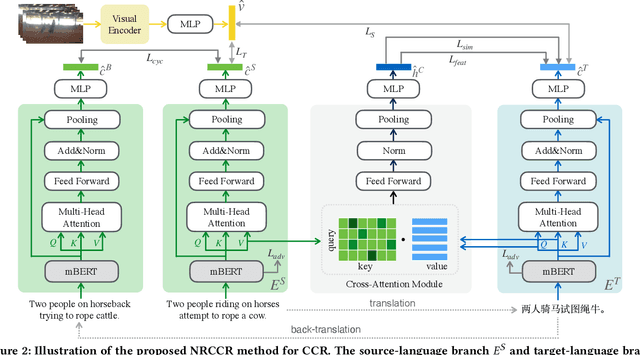
Despite the recent developments in the field of cross-modal retrieval, there has been less research focusing on low-resource languages due to the lack of manually annotated datasets. In this paper, we propose a noise-robust cross-lingual cross-modal retrieval method for low-resource languages. To this end, we use Machine Translation (MT) to construct pseudo-parallel sentence pairs for low-resource languages. However, as MT is not perfect, it tends to introduce noise during translation, rendering textual embeddings corrupted and thereby compromising the retrieval performance. To alleviate this, we introduce a multi-view self-distillation method to learn noise-robust target-language representations, which employs a cross-attention module to generate soft pseudo-targets to provide direct supervision from the similarity-based view and feature-based view. Besides, inspired by the back-translation in unsupervised MT, we minimize the semantic discrepancies between origin sentences and back-translated sentences to further improve the noise robustness of the textual encoder. Extensive experiments are conducted on three video-text and image-text cross-modal retrieval benchmarks across different languages, and the results demonstrate that our method significantly improves the overall performance without using extra human-labeled data. In addition, equipped with a pre-trained visual encoder from a recent vision-and-language pre-training framework, i.e., CLIP, our model achieves a significant performance gain, showing that our method is compatible with popular pre-training models. Code and data are available at https://github.com/HuiGuanLab/nrccr.
Reading-strategy Inspired Visual Representation Learning for Text-to-Video Retrieval
Jan 23, 2022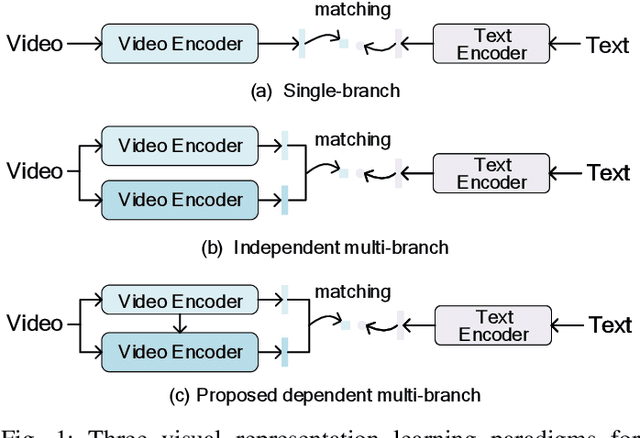
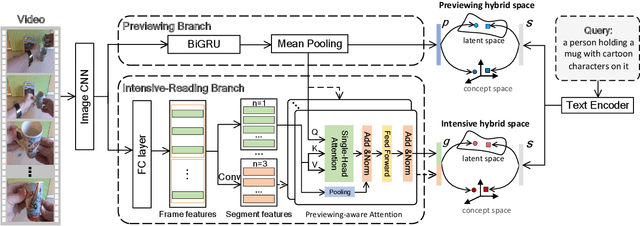
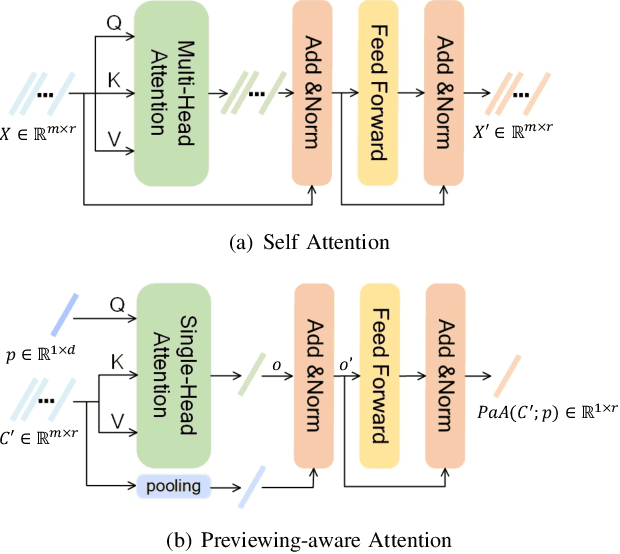
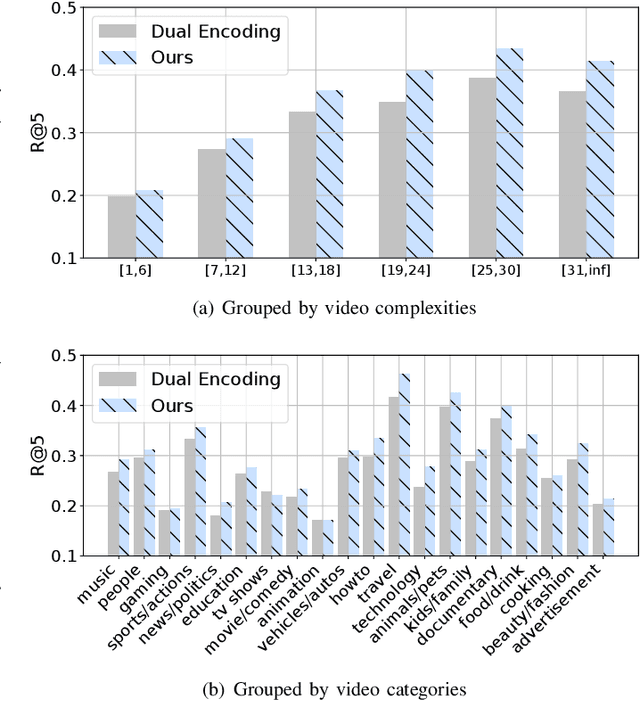
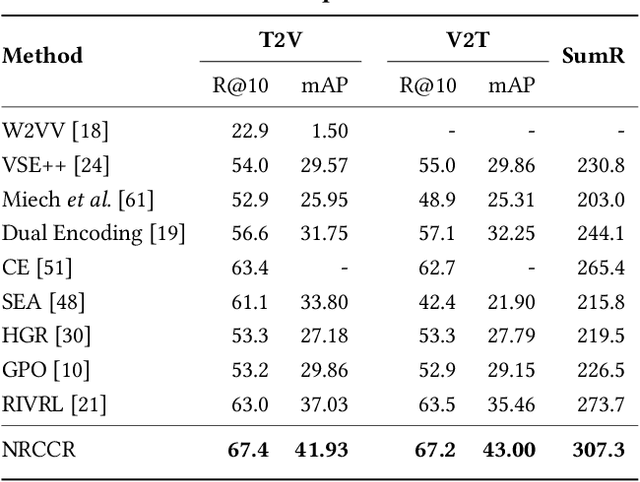
This paper aims for the task of text-to-video retrieval, where given a query in the form of a natural-language sentence, it is asked to retrieve videos which are semantically relevant to the given query, from a great number of unlabeled videos. The success of this task depends on cross-modal representation learning that projects both videos and sentences into common spaces for semantic similarity computation. In this work, we concentrate on video representation learning, an essential component for text-to-video retrieval. Inspired by the reading strategy of humans, we propose a Reading-strategy Inspired Visual Representation Learning (RIVRL) to represent videos, which consists of two branches: a previewing branch and an intensive-reading branch. The previewing branch is designed to briefly capture the overview information of videos, while the intensive-reading branch is designed to obtain more in-depth information. Moreover, the intensive-reading branch is aware of the video overview captured by the previewing branch. Such holistic information is found to be useful for the intensive-reading branch to extract more fine-grained features. Extensive experiments on three datasets are conducted, where our model RIVRL achieves a new state-of-the-art on TGIF and VATEX. Moreover, on MSR-VTT, our model using two video features shows comparable performance to the state-of-the-art using seven video features and even outperforms models pre-trained on the large-scale HowTo100M dataset.