 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe KFIoU Loss for Rotated Object Detection
Feb 01, 2022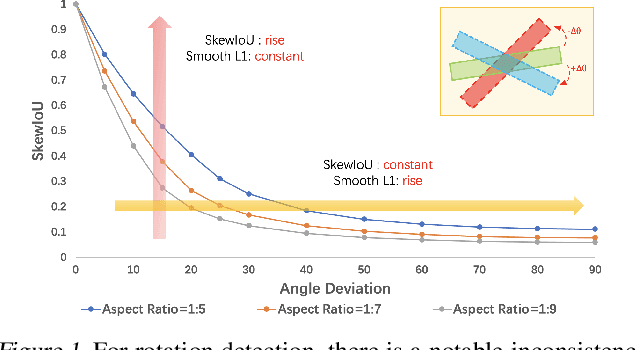
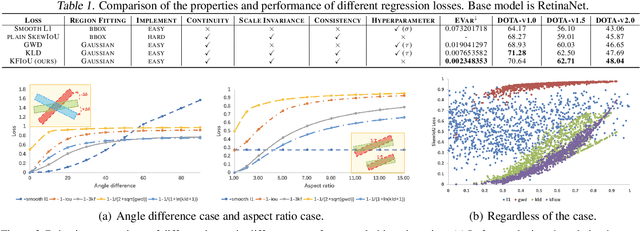
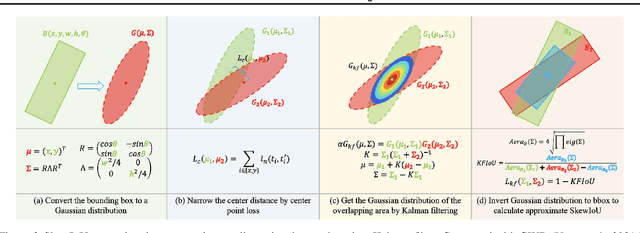

Differing from the well-developed horizontal object detection area whereby the computing-friendly IoU based loss is readily adopted and well fits with the detection metrics. In contrast, rotation detectors often involve a more complicated loss based on SkewIoU which is unfriendly to gradient-based training. In this paper, we argue that one effective alternative is to devise an approximate loss who can achieve trend-level alignment with SkewIoU loss instead of the strict value-level identity. Specifically, we model the objects as Gaussian distribution and adopt Kalman filter to inherently mimic the mechanism of SkewIoU by its definition, and show its alignment with the SkewIoU at trend-level. This is in contrast to recent Gaussian modeling based rotation detectors e.g. GWD, KLD that involves a human-specified distribution distance metric which requires additional hyperparameter tuning. The resulting new loss called KFIoU is easier to implement and works better compared with exact SkewIoU, thanks to its full differentiability and ability to handle the non-overlapping cases. We further extend our technique to the 3-D case which also suffers from the same issues as 2-D detection. Extensive results on various public datasets (2-D/3-D, aerial/text/face images) with different base detectors show the effectiveness of our approach.
GhostNets on Heterogeneous Devices via Cheap Operations
Jan 10, 2022
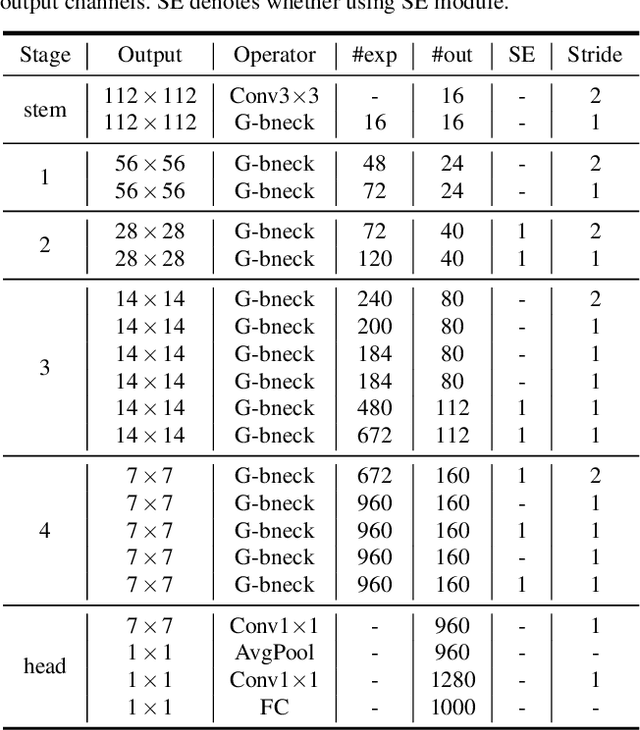
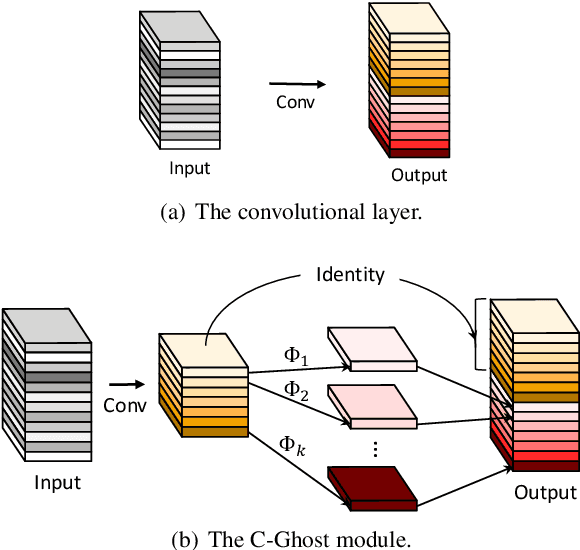
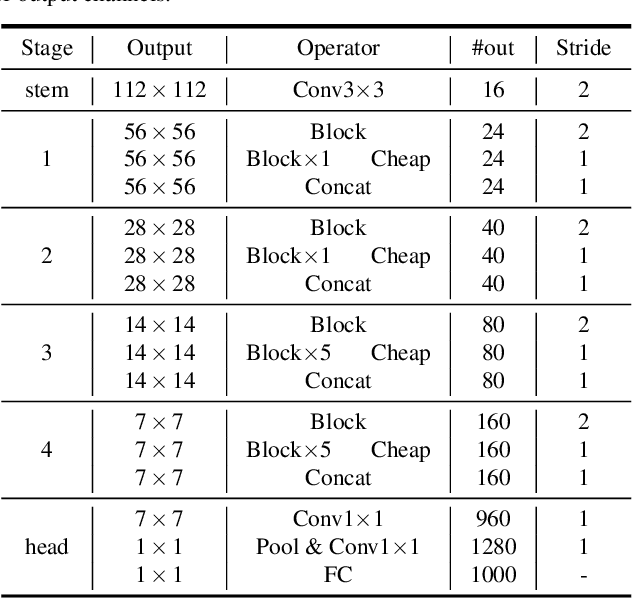
Deploying convolutional neural networks (CNNs) on mobile devices is difficult due to the limited memory and computation resources. We aim to design efficient neural networks for heterogeneous devices including CPU and GPU, by exploiting the redundancy in feature maps, which has rarely been investigated in neural architecture design. For CPU-like devices, we propose a novel CPU-efficient Ghost (C-Ghost) module to generate more feature maps from cheap operations. Based on a set of intrinsic feature maps, we apply a series of linear transformations with cheap cost to generate many ghost feature maps that could fully reveal information underlying intrinsic features. The proposed C-Ghost module can be taken as a plug-and-play component to upgrade existing convolutional neural networks. C-Ghost bottlenecks are designed to stack C-Ghost modules, and then the lightweight C-GhostNet can be easily established. We further consider the efficient networks for GPU devices. Without involving too many GPU-inefficient operations (e.g.,, depth-wise convolution) in a building stage, we propose to utilize the stage-wise feature redundancy to formulate GPU-efficient Ghost (G-Ghost) stage structure. The features in a stage are split into two parts where the first part is processed using the original block with fewer output channels for generating intrinsic features, and the other are generated using cheap operations by exploiting stage-wise redundancy. Experiments conducted on benchmarks demonstrate the effectiveness of the proposed C-Ghost module and the G-Ghost stage. C-GhostNet and G-GhostNet can achieve the optimal trade-off of accuracy and latency for CPU and GPU, respectively. Code is available at https://github.com/huawei-noah/CV-Backbones.
Multi-agent Communication with Graph Information Bottleneck under Limited Bandwidth
Dec 29, 2021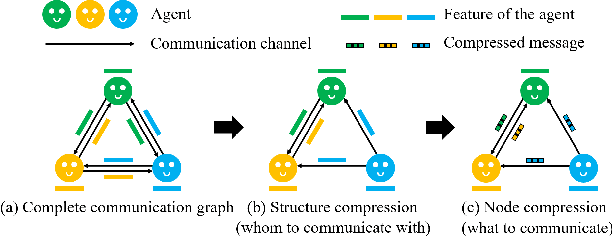
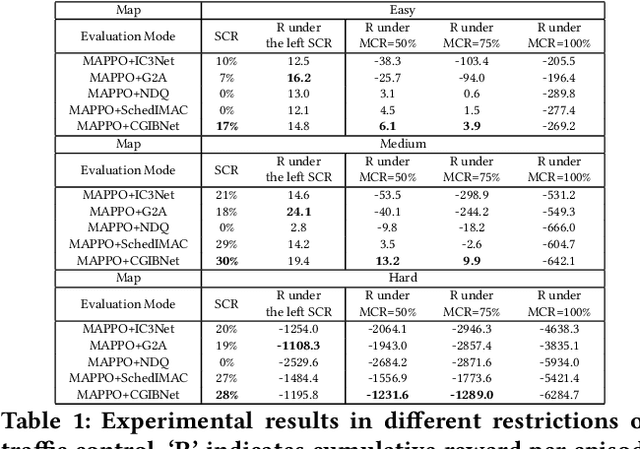
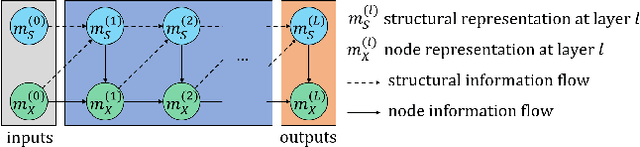
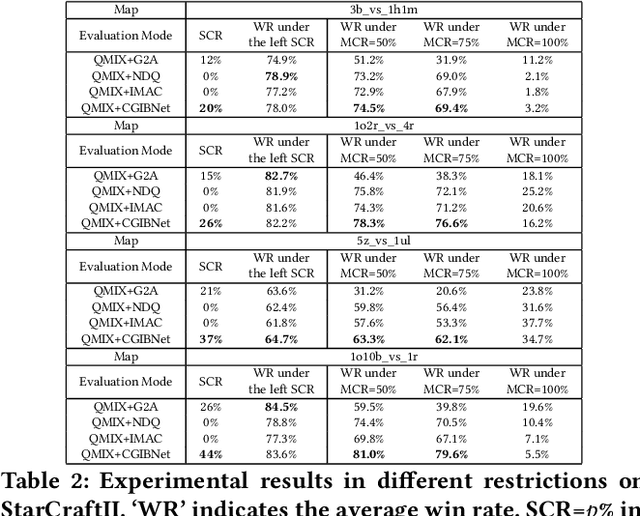
Recent studies have shown that introducing communication between agents can significantly improve overall performance in cooperative Multi-agent reinforcement learning (MARL). In many real-world scenarios, communication can be expensive and the bandwidth of the multi-agent system is subject to certain constraints. Redundant messages who occupy the communication resources can block the transmission of informative messages and thus jeopardize the performance. In this paper, we aim to learn the minimal sufficient communication messages. First, we initiate the communication between agents by a complete graph. Then we introduce the graph information bottleneck (GIB) principle into this complete graph and derive the optimization over graph structures. Based on the optimization, a novel multi-agent communication module, called CommGIB, is proposed, which effectively compresses the structure information and node information in the communication graph to deal with bandwidth-constrained settings. Extensive experiments in Traffic Control and StanCraft II are conducted. The results indicate that the proposed methods can achieve better performance in bandwidth-restricted settings compared with state-of-the-art algorithms, with especially large margins in large-scale multi-agent tasks.
General Greedy De-bias Learning
Dec 21, 2021
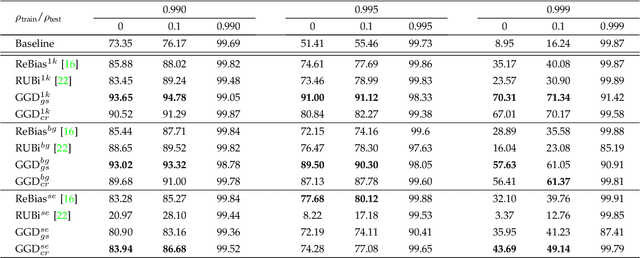
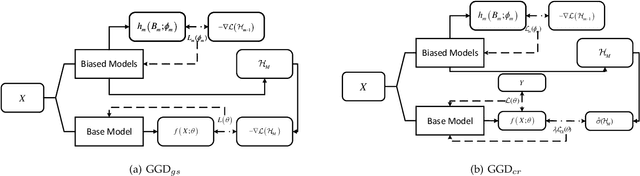
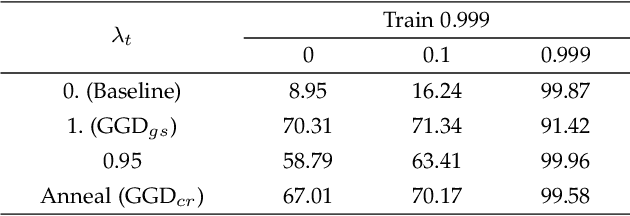
Neural networks often make predictions relying on the spurious correlations from the datasets rather than the intrinsic properties of the task of interest, facing sharp degradation on out-of-distribution (OOD) test data. Existing de-bias learning frameworks try to capture specific dataset bias by bias annotations, they fail to handle complicated OOD scenarios. Others implicitly identify the dataset bias by the special design on the low capability biased model or the loss, but they degrade when the training and testing data are from the same distribution. In this paper, we propose a General Greedy De-bias learning framework (GGD), which greedily trains the biased models and the base model like gradient descent in functional space. It encourages the base model to focus on examples that are hard to solve with biased models, thus remaining robust against spurious correlations in the test stage. GGD largely improves models' OOD generalization ability on various tasks, but sometimes over-estimates the bias level and degrades on the in-distribution test. We further re-analyze the ensemble process of GGD and introduce the Curriculum Regularization into GGD inspired by curriculum learning, which achieves a good trade-off between in-distribution and out-of-distribution performance. Extensive experiments on image classification, adversarial question answering, and visual question answering demonstrate the effectiveness of our method. GGD can learn a more robust base model under the settings of both task-specific biased models with prior knowledge and self-ensemble biased model without prior knowledge.
SiamTrans: Zero-Shot Multi-Frame Image Restoration with Pre-Trained Siamese Transformers
Dec 17, 2021
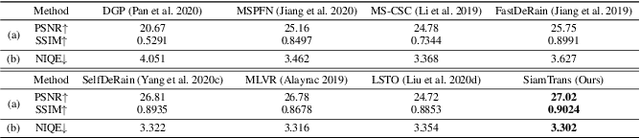
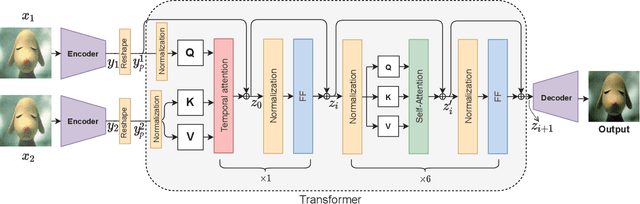
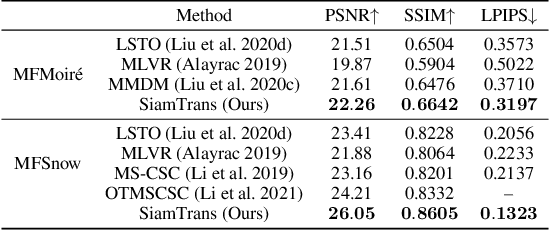
We propose a novel zero-shot multi-frame image restoration method for removing unwanted obstruction elements (such as rains, snow, and moire patterns) that vary in successive frames. It has three stages: transformer pre-training, zero-shot restoration, and hard patch refinement. Using the pre-trained transformers, our model is able to tell the motion difference between the true image information and the obstructing elements. For zero-shot image restoration, we design a novel model, termed SiamTrans, which is constructed by Siamese transformers, encoders, and decoders. Each transformer has a temporal attention layer and several self-attention layers, to capture both temporal and spatial information of multiple frames. Only pre-trained (self-supervised) on the denoising task, SiamTrans is tested on three different low-level vision tasks (deraining, demoireing, and desnowing). Compared with related methods, ours achieves the best performances, even outperforming those with supervised learning.
Frequency Spectrum Augmentation Consistency for Domain Adaptive Object Detection
Dec 16, 2021
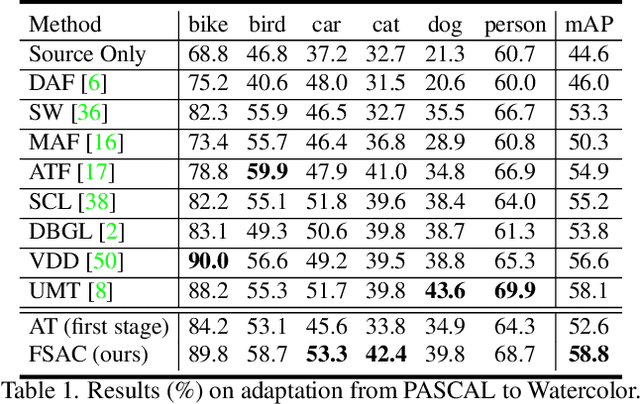

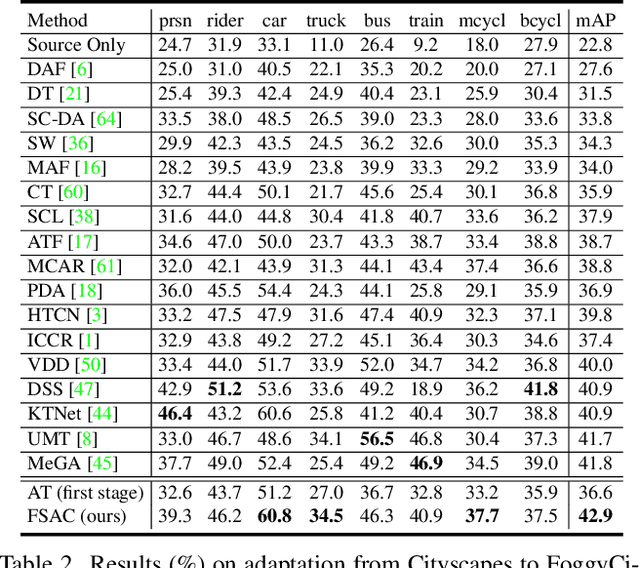
Domain adaptive object detection (DAOD) aims to improve the generalization ability of detectors when the training and test data are from different domains. Considering the significant domain gap, some typical methods, e.g., CycleGAN-based methods, adopt the intermediate domain to bridge the source and target domains progressively. However, the CycleGAN-based intermediate domain lacks the pix- or instance-level supervision for object detection, which leads to semantic differences. To address this problem, in this paper, we introduce a Frequency Spectrum Augmentation Consistency (FSAC) framework with four different low-frequency filter operations. In this way, we can obtain a series of augmented data as the intermediate domain. Concretely, we propose a two-stage optimization framework. In the first stage, we utilize all the original and augmented source data to train an object detector. In the second stage, augmented source and target data with pseudo labels are adopted to perform the self-training for prediction consistency. And a teacher model optimized using Mean Teacher is used to further revise the pseudo labels. In the experiment, we evaluate our method on the single- and compound- target DAOD separately, which demonstrate the effectiveness of our method.
Mining Minority-class Examples With Uncertainty Estimates
Dec 15, 2021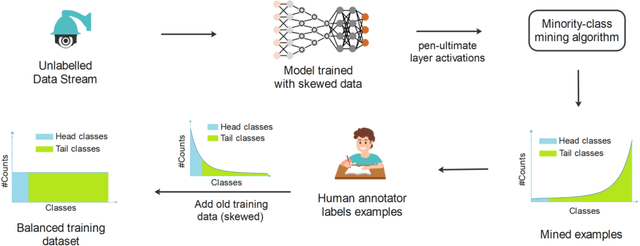

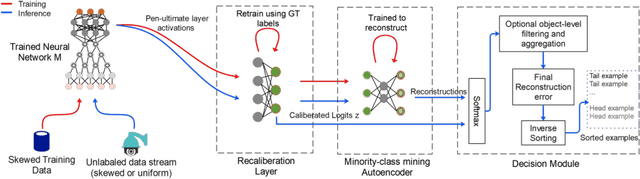
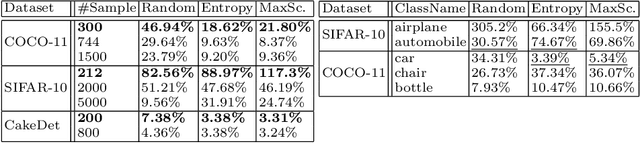
In the real world, the frequency of occurrence of objects is naturally skewed forming long-tail class distributions, which results in poor performance on the statistically rare classes. A promising solution is to mine tail-class examples to balance the training dataset. However, mining tail-class examples is a very challenging task. For instance, most of the otherwise successful uncertainty-based mining approaches struggle due to distortion of class probabilities resulting from skewness in data. In this work, we propose an effective, yet simple, approach to overcome these challenges. Our framework enhances the subdued tail-class activations and, thereafter, uses a one-class data-centric approach to effectively identify tail-class examples. We carry out an exhaustive evaluation of our framework on three datasets spanning over two computer vision tasks. Substantial improvements in the minority-class mining and fine-tuned model's performance strongly corroborate the value of our proposed solution.
Exploring Complicated Search Spaces with Interleaving-Free Sampling
Dec 05, 2021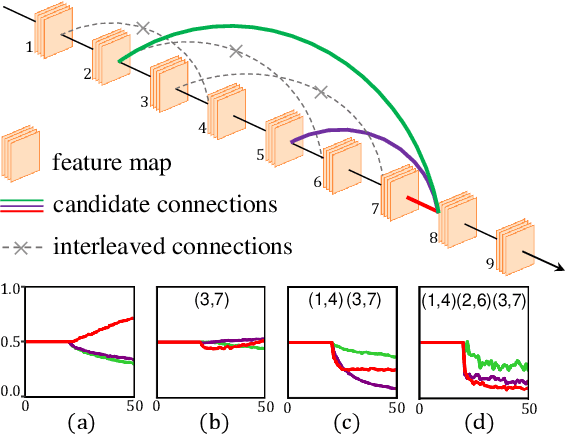


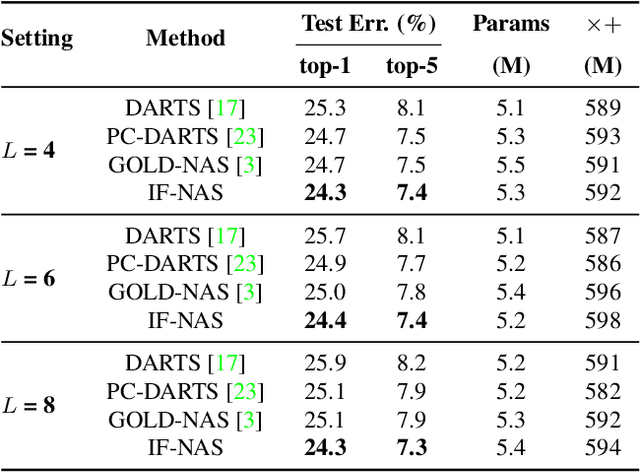
The existing neural architecture search algorithms are mostly working on search spaces with short-distance connections. We argue that such designs, though safe and stable, obstacles the search algorithms from exploring more complicated scenarios. In this paper, we build the search algorithm upon a complicated search space with long-distance connections, and show that existing weight-sharing search algorithms mostly fail due to the existence of \textbf{interleaved connections}. Based on the observation, we present a simple yet effective algorithm named \textbf{IF-NAS}, where we perform a periodic sampling strategy to construct different sub-networks during the search procedure, avoiding the interleaved connections to emerge in any of them. In the proposed search space, IF-NAS outperform both random sampling and previous weight-sharing search algorithms by a significant margin. IF-NAS also generalizes to the micro cell-based spaces which are much easier. Our research emphasizes the importance of macro structure and we look forward to further efforts along this direction.
NeuSample: Neural Sample Field for Efficient View Synthesis
Nov 30, 2021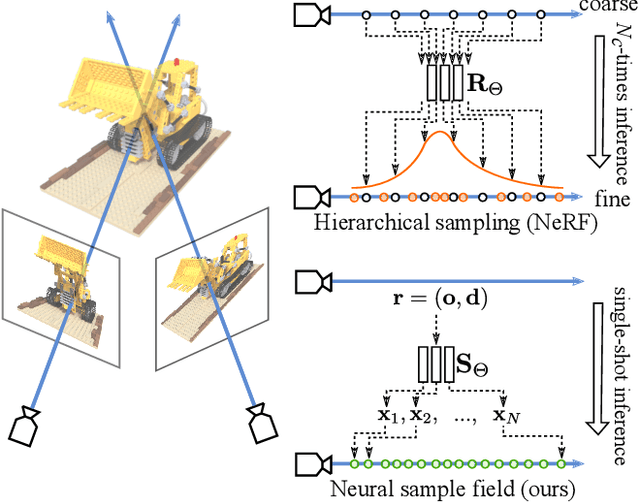
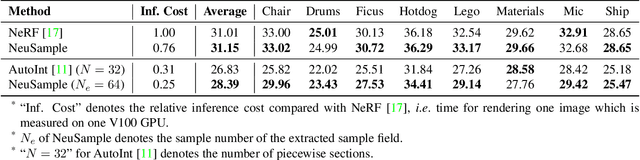
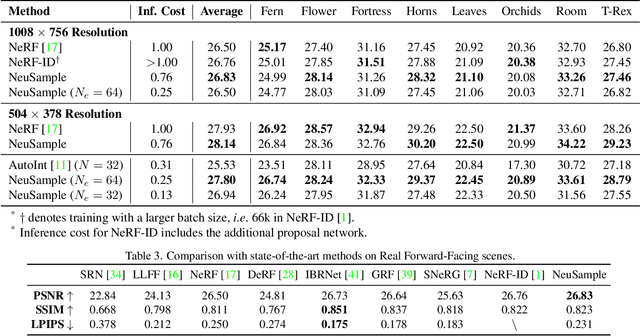
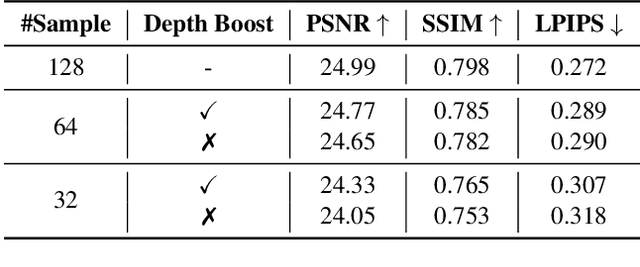
Neural radiance fields (NeRF) have shown great potentials in representing 3D scenes and synthesizing novel views, but the computational overhead of NeRF at the inference stage is still heavy. To alleviate the burden, we delve into the coarse-to-fine, hierarchical sampling procedure of NeRF and point out that the coarse stage can be replaced by a lightweight module which we name a neural sample field. The proposed sample field maps rays into sample distributions, which can be transformed into point coordinates and fed into radiance fields for volume rendering. The overall framework is named as NeuSample. We perform experiments on Realistic Synthetic 360$^{\circ}$ and Real Forward-Facing, two popular 3D scene sets, and show that NeuSample achieves better rendering quality than NeRF while enjoying a faster inference speed. NeuSample is further compressed with a proposed sample field extraction method towards a better trade-off between quality and speed.
Semantic-Aware Generation for Self-Supervised Visual Representation Learning
Nov 25, 2021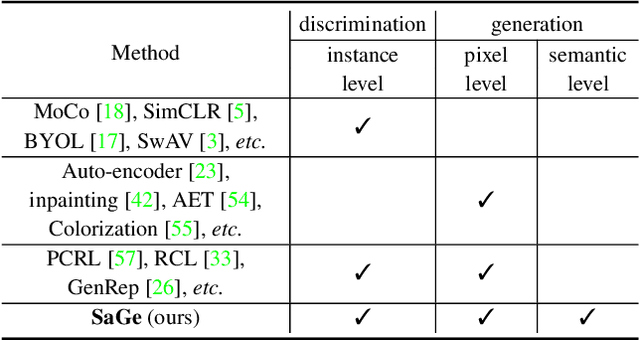
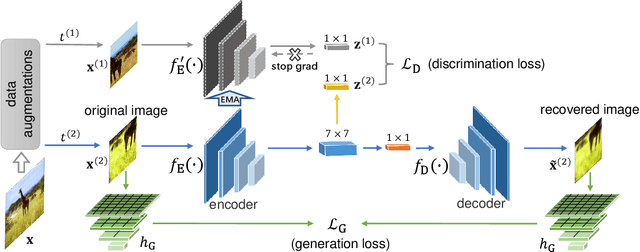

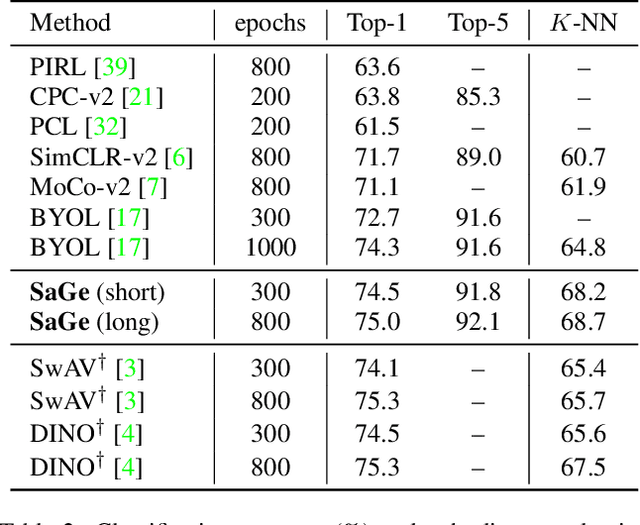
In this paper, we propose a self-supervised visual representation learning approach which involves both generative and discriminative proxies, where we focus on the former part by requiring the target network to recover the original image based on the mid-level features. Different from prior work that mostly focuses on pixel-level similarity between the original and generated images, we advocate for Semantic-aware Generation (SaGe) to facilitate richer semantics rather than details to be preserved in the generated image. The core idea of implementing SaGe is to use an evaluator, a deep network that is pre-trained without labels, for extracting semantic-aware features. SaGe complements the target network with view-specific features and thus alleviates the semantic degradation brought by intensive data augmentations. We execute SaGe on ImageNet-1K and evaluate the pre-trained models on five downstream tasks including nearest neighbor test, linear classification, and fine-scaled image recognition, demonstrating its ability to learn stronger visual representations.