 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Learned Knowledge in LoRA Adapters Through Efficient Contrastive Decoding on Ascend NPUs
May 20, 2025Huawei Cloud users leverage LoRA (Low-Rank Adaptation) as an efficient and scalable method to fine-tune and customize large language models (LLMs) for application-specific needs. However, tasks that require complex reasoning or deep contextual understanding are often hindered by biases or interference from the base model when using typical decoding methods like greedy or beam search. These biases can lead to generic or task-agnostic responses from the base model instead of leveraging the LoRA-specific adaptations. In this paper, we introduce Contrastive LoRA Decoding (CoLD), a novel decoding framework designed to maximize the use of task-specific knowledge in LoRA-adapted models, resulting in better downstream performance. CoLD uses contrastive decoding by scoring candidate tokens based on the divergence between the probability distributions of a LoRA-adapted expert model and the corresponding base model. This approach prioritizes tokens that better align with the LoRA's learned representations, enhancing performance for specialized tasks. While effective, a naive implementation of CoLD is computationally expensive because each decoding step requires evaluating multiple token candidates across both models. To address this, we developed an optimized kernel for Huawei's Ascend NPU. CoLD achieves up to a 5.54% increase in task accuracy while reducing end-to-end latency by 28% compared to greedy decoding. This work provides practical and efficient decoding strategies for fine-tuned LLMs in resource-constrained environments and has broad implications for applied data science in both cloud and on-premises settings.
DivPrune: Diversity-based Visual Token Pruning for Large Multimodal Models
Mar 04, 2025



Large Multimodal Models (LMMs) have emerged as powerful models capable of understanding various data modalities, including text, images, and videos. LMMs encode both text and visual data into tokens that are then combined and processed by an integrated Large Language Model (LLM). Including visual tokens substantially increases the total token count, often by thousands. The increased input length for LLM significantly raises the complexity of inference, resulting in high latency in LMMs. To address this issue, token pruning methods, which remove part of the visual tokens, are proposed. The existing token pruning methods either require extensive calibration and fine-tuning or rely on suboptimal importance metrics which results in increased redundancy among the retained tokens. In this paper, we first formulate token pruning as Max-Min Diversity Problem (MMDP) where the goal is to select a subset such that the diversity among the selected {tokens} is maximized. Then, we solve the MMDP to obtain the selected subset and prune the rest. The proposed method, DivPrune, reduces redundancy and achieves the highest diversity of the selected tokens. By ensuring high diversity, the selected tokens better represent the original tokens, enabling effective performance even at high pruning ratios without requiring fine-tuning. Extensive experiments with various LMMs show that DivPrune achieves state-of-the-art accuracy over 16 image- and video-language datasets. Additionally, DivPrune reduces both the end-to-end latency and GPU memory usage for the tested models. The code is available $\href{https://github.com/vbdi/divprune}{\text{here}}$.
Towards Secure and Usable 3D Assets: A Novel Framework for Automatic Visible Watermarking
Aug 31, 2024



3D models, particularly AI-generated ones, have witnessed a recent surge across various industries such as entertainment. Hence, there is an alarming need to protect the intellectual property and avoid the misuse of these valuable assets. As a viable solution to address these concerns, we rigorously define the novel task of automated 3D visible watermarking in terms of two competing aspects: watermark quality and asset utility. Moreover, we propose a method of embedding visible watermarks that automatically determines the right location, orientation, and number of watermarks to be placed on arbitrary 3D assets for high watermark quality and asset utility. Our method is based on a novel rigid-body optimization that uses back-propagation to automatically learn transforms for ideal watermark placement. In addition, we propose a novel curvature-matching method for fusing the watermark into the 3D model that further improves readability and security. Finally, we provide a detailed experimental analysis on two benchmark 3D datasets validating the superior performance of our approach in comparison to baselines. Code and demo are available.
IPProtect: protecting the intellectual property of visual datasets during data valuation
Dec 22, 2022



Data trading is essential to accelerate the development of data-driven machine learning pipelines. The central problem in data trading is to estimate the utility of a seller's dataset with respect to a given buyer's machine learning task, also known as data valuation. Typically, data valuation requires one or more participants to share their raw dataset with others, leading to potential risks of intellectual property (IP) violations. In this paper, we tackle the novel task of preemptively protecting the IP of datasets that need to be shared during data valuation. First, we identify and formalize two kinds of novel IP risks in visual datasets: data-item (image) IP and statistical (dataset) IP. Then, we propose a novel algorithm to convert the raw dataset into a sanitized version, that provides resistance to IP violations, while at the same time allowing accurate data valuation. The key idea is to limit the transfer of information from the raw dataset to the sanitized dataset, thereby protecting against potential intellectual property violations. Next, we analyze our method for the likely existence of a solution and immunity against reconstruction attacks. Finally, we conduct extensive experiments on three computer vision datasets demonstrating the advantages of our method in comparison to other baselines.
Revealing Unfair Models by Mining Interpretable Evidence
Jul 12, 2022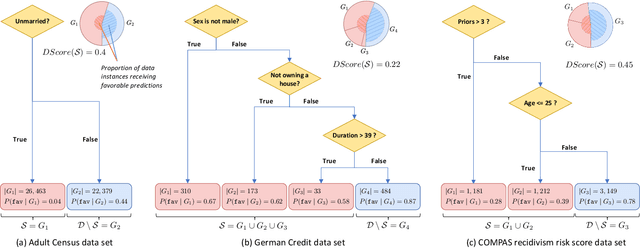
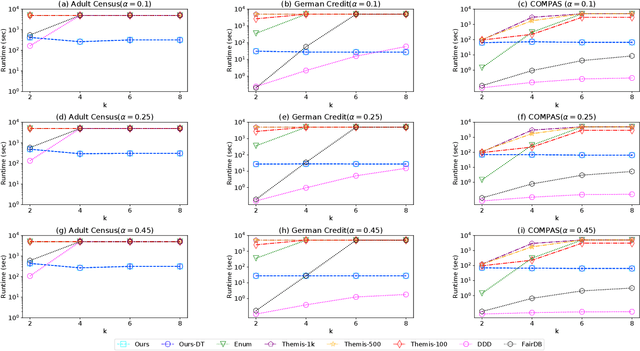
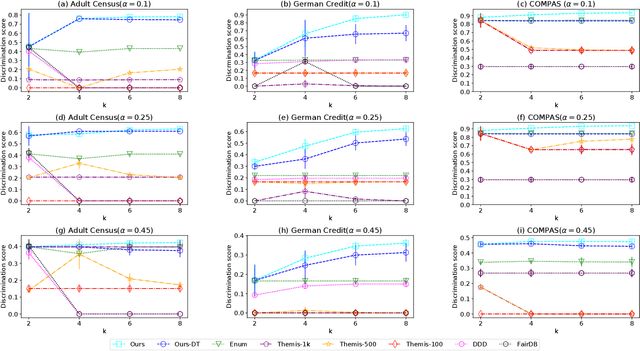
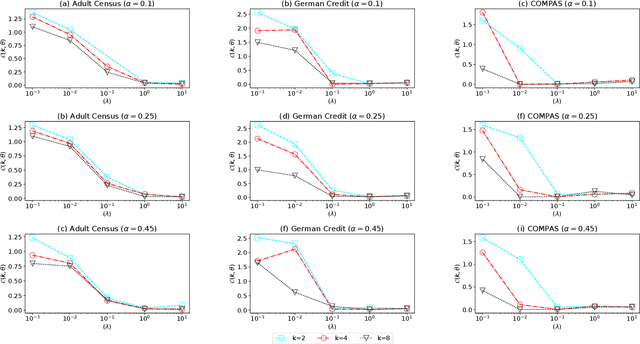
The popularity of machine learning has increased the risk of unfair models getting deployed in high-stake applications, such as justice system, drug/vaccination design, and medical diagnosis. Although there are effective methods to train fair models from scratch, how to automatically reveal and explain the unfairness of a trained model remains a challenging task. Revealing unfairness of machine learning models in interpretable fashion is a critical step towards fair and trustworthy AI. In this paper, we systematically tackle the novel task of revealing unfair models by mining interpretable evidence (RUMIE). The key idea is to find solid evidence in the form of a group of data instances discriminated most by the model. To make the evidence interpretable, we also find a set of human-understandable key attributes and decision rules that characterize the discriminated data instances and distinguish them from the other non-discriminated data. As demonstrated by extensive experiments on many real-world data sets, our method finds highly interpretable and solid evidence to effectively reveal the unfairness of trained models. Moreover, it is much more scalable than all of the baseline methods.
Mining Minority-class Examples With Uncertainty Estimates
Dec 15, 2021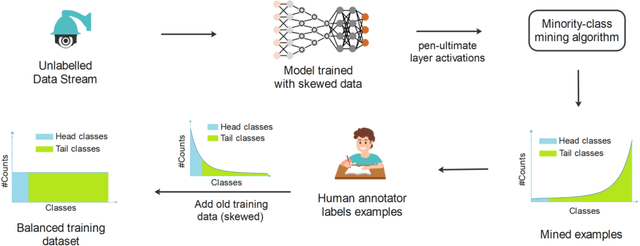

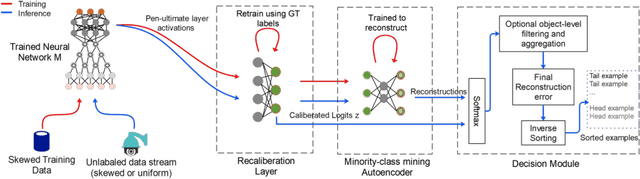
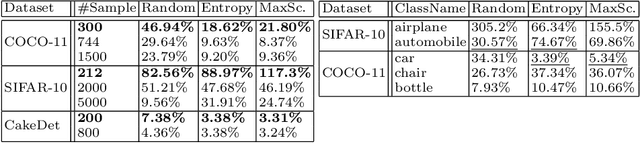
In the real world, the frequency of occurrence of objects is naturally skewed forming long-tail class distributions, which results in poor performance on the statistically rare classes. A promising solution is to mine tail-class examples to balance the training dataset. However, mining tail-class examples is a very challenging task. For instance, most of the otherwise successful uncertainty-based mining approaches struggle due to distortion of class probabilities resulting from skewness in data. In this work, we propose an effective, yet simple, approach to overcome these challenges. Our framework enhances the subdued tail-class activations and, thereafter, uses a one-class data-centric approach to effectively identify tail-class examples. We carry out an exhaustive evaluation of our framework on three datasets spanning over two computer vision tasks. Substantial improvements in the minority-class mining and fine-tuned model's performance strongly corroborate the value of our proposed solution.