 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabularMark: Watermarking Tabular Datasets for Machine Learning
Jun 21, 2024



Watermarking is broadly utilized to protect ownership of shared data while preserving data utility. However, existing watermarking methods for tabular datasets fall short on the desired properties (detectability, non-intrusiveness, and robustness) and only preserve data utility from the perspective of data statistics, ignoring the performance of downstream ML models trained on the datasets. Can we watermark tabular datasets without significantly compromising their utility for training ML models while preventing attackers from training usable ML models on attacked datasets? In this paper, we propose a hypothesis testing-based watermarking scheme, TabularMark. Data noise partitioning is utilized for data perturbation during embedding, which is adaptable for numerical and categorical attributes while preserving the data utility. For detection, a custom-threshold one proportion z-test is employed, which can reliably determine the presence of the watermark. Experiments on real-world and synthetic datasets demonstrate the superiority of TabularMark in detectability, non-intrusiveness, and robustness.
Lumos: Heterogeneity-aware Federated Graph Learning over Decentralized Devices
Mar 01, 2023Graph neural networks (GNN) have been widely deployed in real-world networked applications and systems due to their capability to handle graph-structured data. However, the growing awareness of data privacy severely challenges the traditional centralized model training paradigm, where a server holds all the graph information. Federated learning is an emerging collaborative computing paradigm that allows model training without data centralization. Existing federated GNN studies mainly focus on systems where clients hold distinctive graphs or sub-graphs. The practical node-level federated situation, where each client is only aware of its direct neighbors, has yet to be studied. In this paper, we propose the first federated GNN framework called Lumos that supports supervised and unsupervised learning with feature and degree protection on node-level federated graphs. We first design a tree constructor to improve the representation capability given the limited structural information. We further present a Monte Carlo Markov Chain-based algorithm to mitigate the workload imbalance caused by degree heterogeneity with theoretically-guaranteed performance. Based on the constructed tree for each client, a decentralized tree-based GNN trainer is proposed to support versatile training. Extensive experiments demonstrate that Lumos outperforms the baseline with significantly higher accuracy and greatly reduced communication cost and training time.
Revealing Unfair Models by Mining Interpretable Evidence
Jul 12, 2022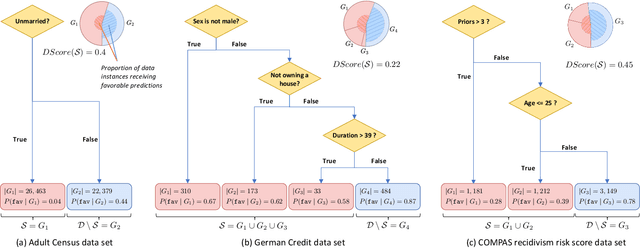
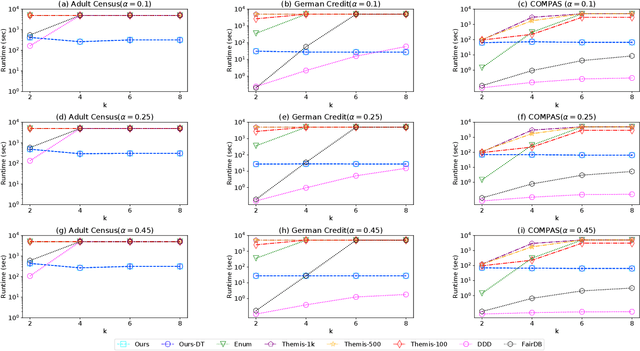
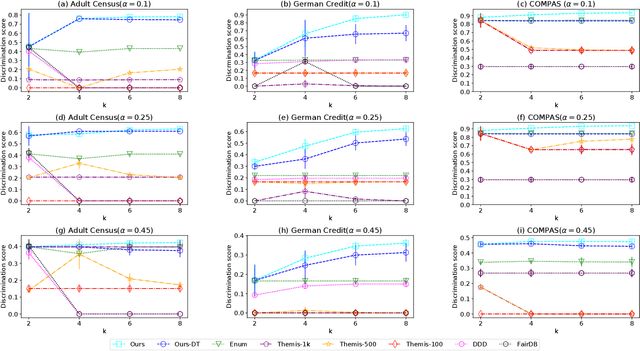
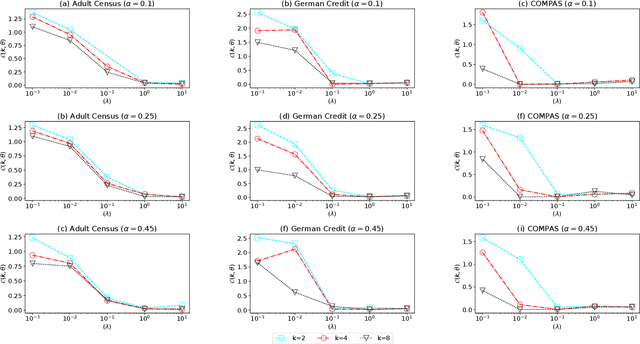
The popularity of machine learning has increased the risk of unfair models getting deployed in high-stake applications, such as justice system, drug/vaccination design, and medical diagnosis. Although there are effective methods to train fair models from scratch, how to automatically reveal and explain the unfairness of a trained model remains a challenging task. Revealing unfairness of machine learning models in interpretable fashion is a critical step towards fair and trustworthy AI. In this paper, we systematically tackle the novel task of revealing unfair models by mining interpretable evidence (RUMIE). The key idea is to find solid evidence in the form of a group of data instances discriminated most by the model. To make the evidence interpretable, we also find a set of human-understandable key attributes and decision rules that characterize the discriminated data instances and distinguish them from the other non-discriminated data. As demonstrated by extensive experiments on many real-world data sets, our method finds highly interpretable and solid evidence to effectively reveal the unfairness of trained models. Moreover, it is much more scalable than all of the baseline methods.
Mining Minority-class Examples With Uncertainty Estimates
Dec 15, 2021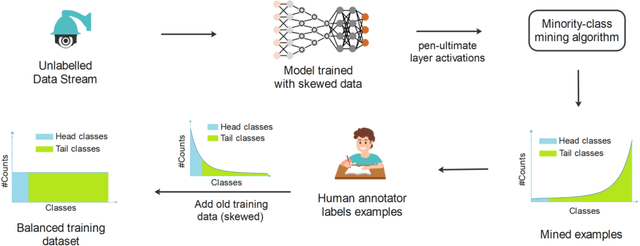

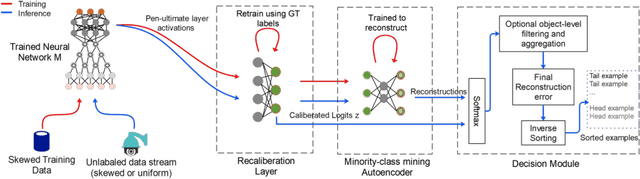
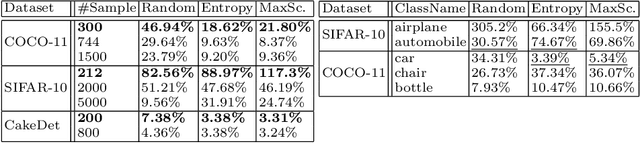
In the real world, the frequency of occurrence of objects is naturally skewed forming long-tail class distributions, which results in poor performance on the statistically rare classes. A promising solution is to mine tail-class examples to balance the training dataset. However, mining tail-class examples is a very challenging task. For instance, most of the otherwise successful uncertainty-based mining approaches struggle due to distortion of class probabilities resulting from skewness in data. In this work, we propose an effective, yet simple, approach to overcome these challenges. Our framework enhances the subdued tail-class activations and, thereafter, uses a one-class data-centric approach to effectively identify tail-class examples. We carry out an exhaustive evaluation of our framework on three datasets spanning over two computer vision tasks. Substantial improvements in the minority-class mining and fine-tuned model's performance strongly corroborate the value of our proposed solution.
Achieving Model Fairness in Vertical Federated Learning
Sep 25, 2021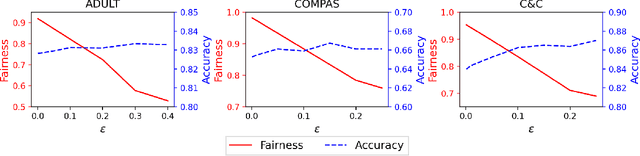
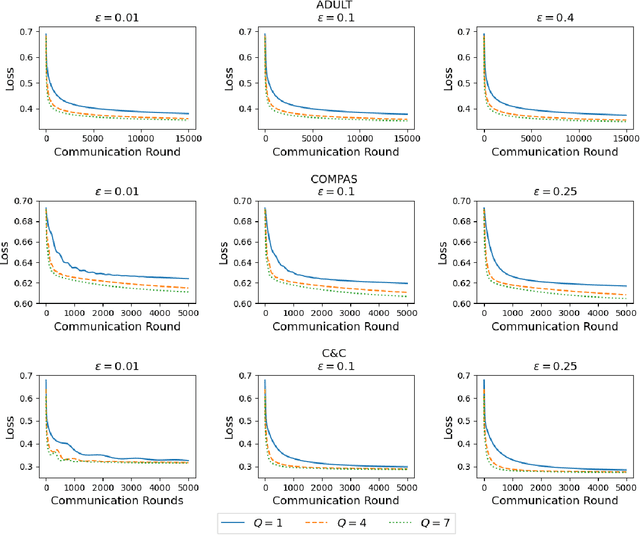

Vertical federated learning (VFL), which enables multiple enterprises possessing non-overlapped features to strengthen their machine learning models without disclosing their private data and model parameters, has received increasing attention lately. Similar to other machine learning algorithms, VFL suffers from fairness issues, i.e., the learned model may be unfairly discriminatory over the group with sensitive attributes. To tackle this problem, we propose a fair VFL framework in this work. First, we systematically formulate the problem of training fair models in VFL, where the learning task is modeled as a constrained optimization problem. To solve it in a federated manner, we consider its equivalent dual form and develop an asynchronous gradient coordinate-descent ascent algorithm, where each data party performs multiple parallelized local updates per communication round to effectively reduce the number of communication rounds. We prove that the algorithm finds a $\delta$-stationary point of the dual objective in $\mathcal{O}(\delta^{-4})$ communication rounds under mild conditions. Finally, extensive experiments on three benchmark datasets demonstrate the superior performance of our method in training fair models.
FedFair: Training Fair Models In Cross-Silo Federated Learning
Sep 13, 2021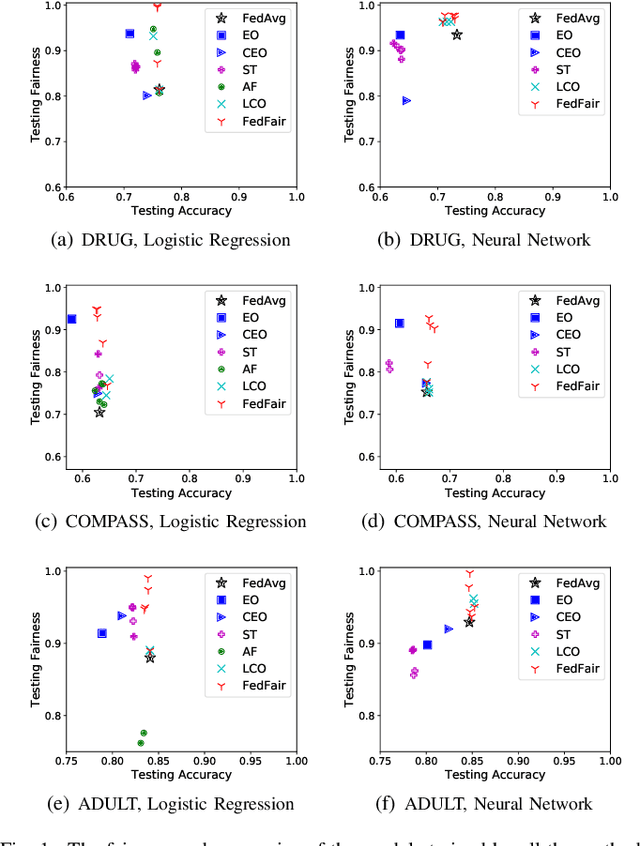
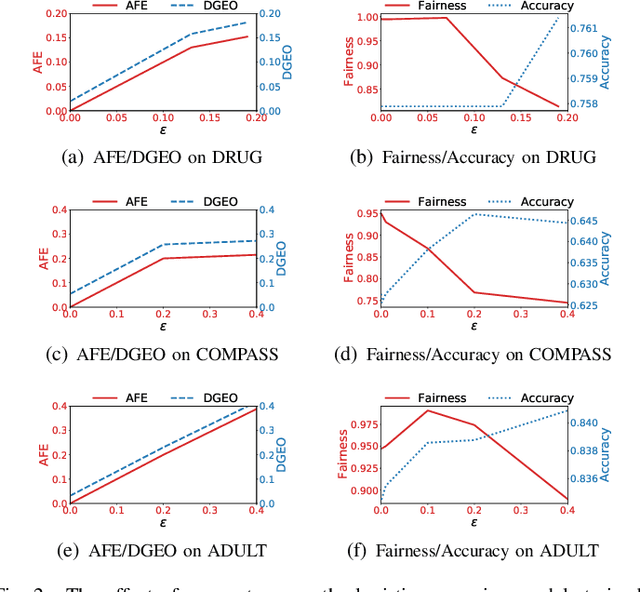
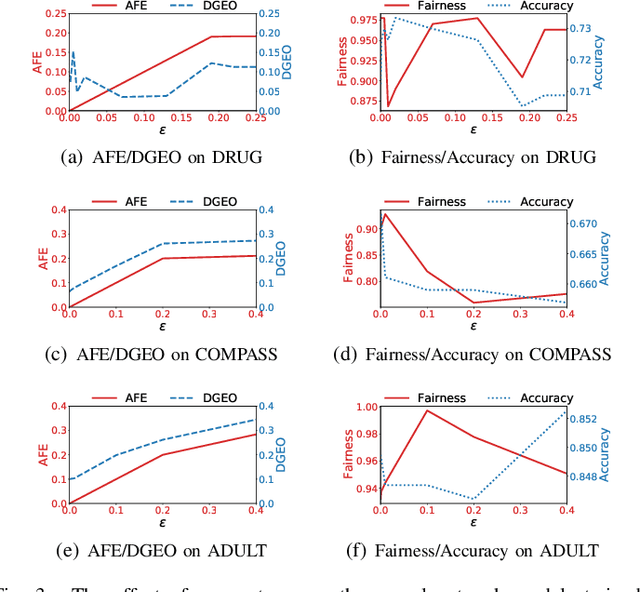
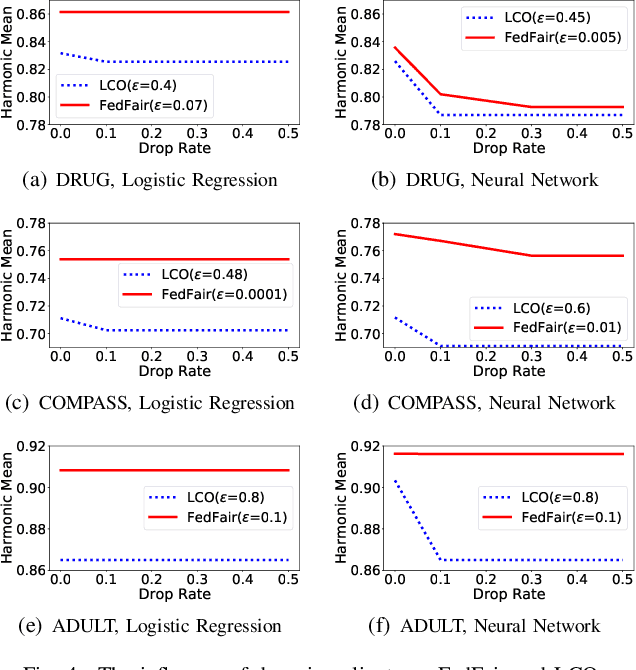
Building fair machine learning models becomes more and more important. As many powerful models are built by collaboration among multiple parties, each holding some sensitive data, it is natural to explore the feasibility of training fair models in cross-silo federated learning so that fairness, privacy and collaboration can be fully respected simultaneously. However, it is a very challenging task, since it is far from trivial to accurately estimate the fairness of a model without knowing the private data of the participating parties. In this paper, we first propose a federated estimation method to accurately estimate the fairness of a model without infringing the data privacy of any party. Then, we use the fairness estimation to formulate a novel problem of training fair models in cross-silo federated learning. We develop FedFair, a well-designed federated learning framework, which can successfully train a fair model with high performance without any data privacy infringement. Our extensive experiments on three real-world data sets demonstrate the excellent fair model training performance of our method.
Finding Representative Interpretations on Convolutional Neural Networks
Aug 20, 2021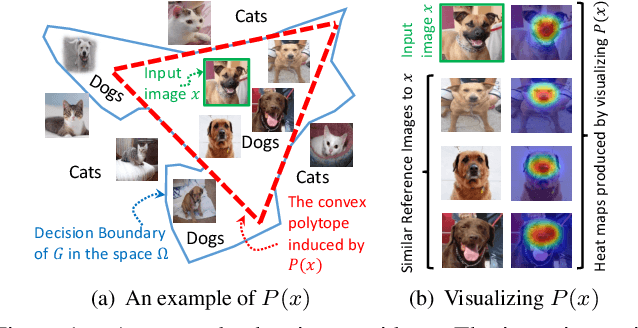
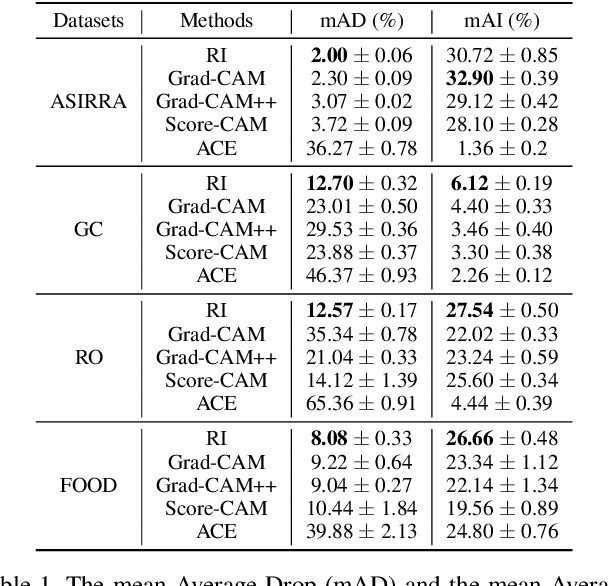
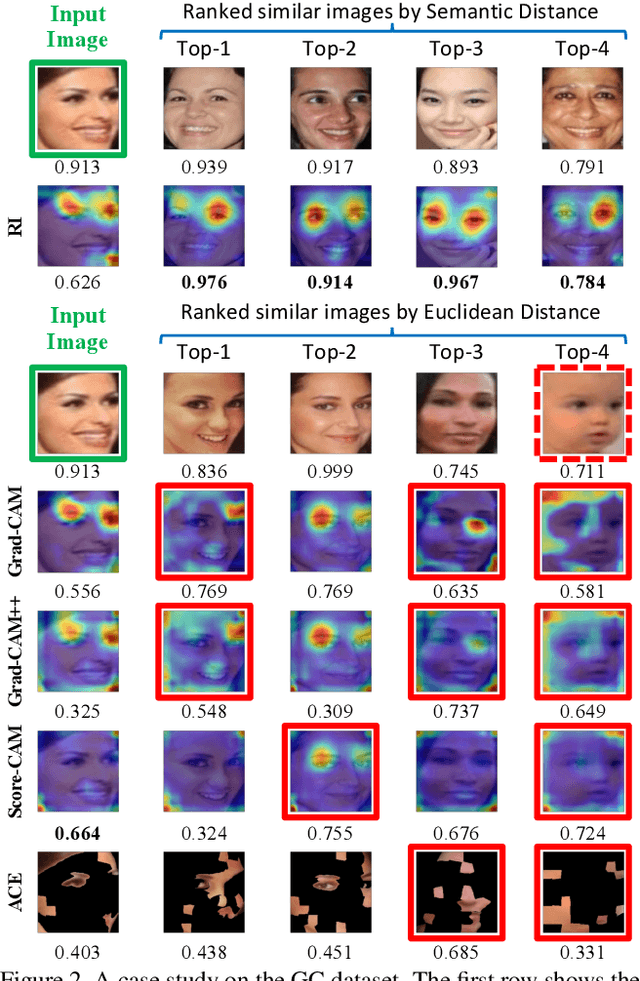
Interpreting the decision logic behind effective deep convolutional neural networks (CNN) on images complements the success of deep learning models. However, the existing methods can only interpret some specific decision logic on individual or a small number of images. To facilitate human understandability and generalization ability, it is important to develop representative interpretations that interpret common decision logics of a CNN on a large group of similar images, which reveal the common semantics data contributes to many closely related predictions. In this paper, we develop a novel unsupervised approach to produce a highly representative interpretation for a large number of similar images. We formulate the problem of finding representative interpretations as a co-clustering problem, and convert it into a submodular cost submodular cover problem based on a sample of the linear decision boundaries of a CNN. We also present a visualization and similarity ranking method. Our extensive experiments demonstrate the excellent performance of our method.
Robust Counterfactual Explanations on Graph Neural Networks
Jul 16, 2021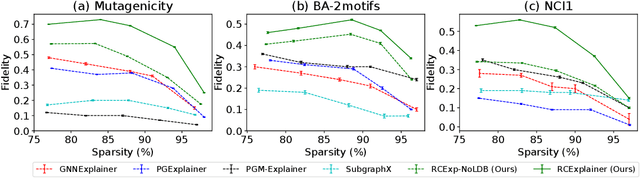

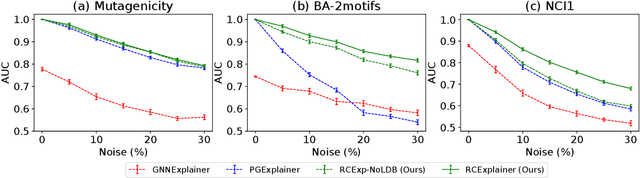
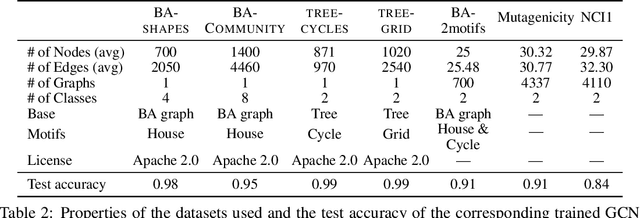
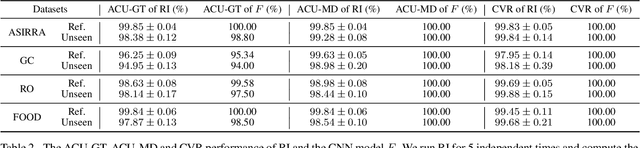
Massive deployment of Graph Neural Networks (GNNs) in high-stake applications generates a strong demand for explanations that are robust to noise and align well with human intuition. Most existing methods generate explanations by identifying a subgraph of an input graph that has a strong correlation with the prediction. These explanations are not robust to noise because independently optimizing the correlation for a single input can easily overfit noise. Moreover, they do not align well with human intuition because removing an identified subgraph from an input graph does not necessarily change the prediction result. In this paper, we propose a novel method to generate robust counterfactual explanations on GNNs by explicitly modelling the common decision logic of GNNs on similar input graphs. Our explanations are naturally robust to noise because they are produced from the common decision boundaries of a GNN that govern the predictions of many similar input graphs. The explanations also align well with human intuition because removing the set of edges identified by an explanation from the input graph changes the prediction significantly. Exhaustive experiments on many public datasets demonstrate the superior performance of our method.
Model Complexity of Deep Learning: A Survey
Mar 08, 2021
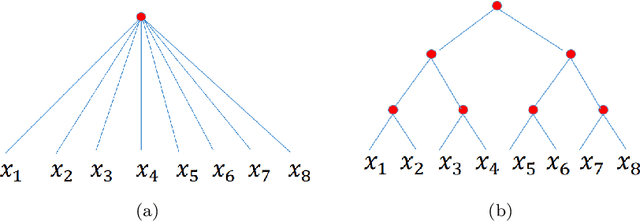
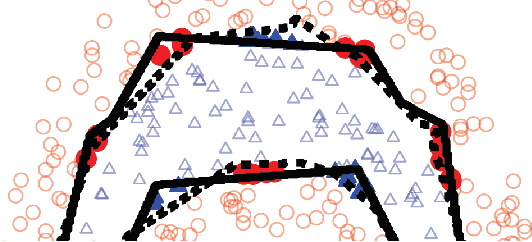
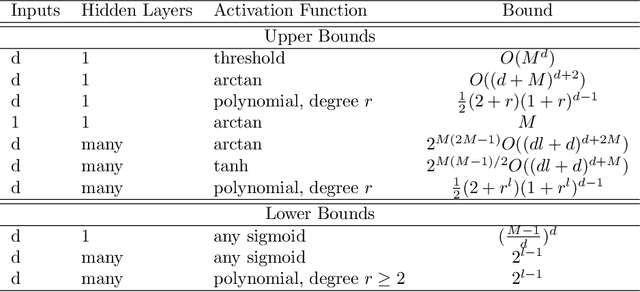
Model complexity is a fundamental problem in deep learning. In this paper we conduct a systematic overview of the latest studies on model complexity in deep learning. Model complexity of deep learning can be categorized into expressive capacity and effective model complexity. We review the existing studies on those two categories along four important factors, including model framework, model size, optimization process and data complexity. We also discuss the applications of deep learning model complexity including understanding model generalization capability, model optimization, and model selection and design. We conclude by proposing several interesting future directions.
Comprehensible Counterfactual Interpretation on Kolmogorov-Smirnov Test
Nov 01, 2020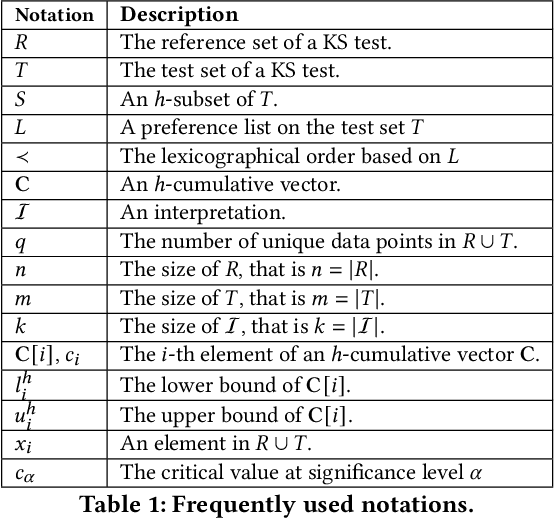
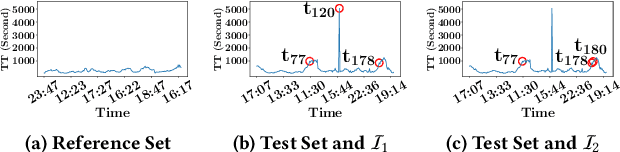
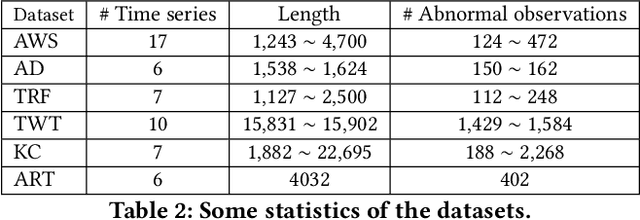
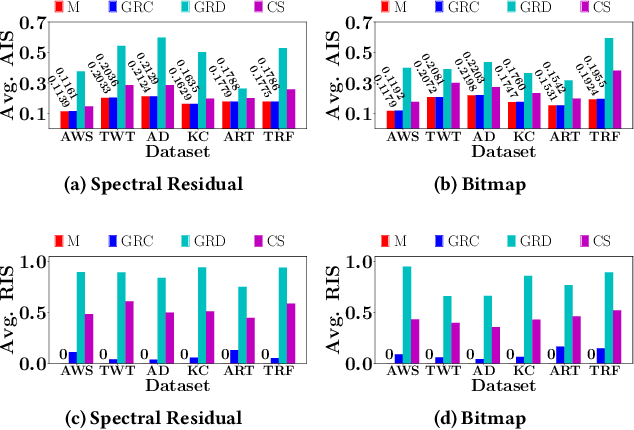
The Kolmogorov-Smirnov (KS) test is popularly used in many applications, such as anomaly detection, astronomy, database security and AI systems. One challenge remained untouched is how we can obtain an interpretation on why a test set fails the KS test. In this paper, we tackle the problem of producing counterfactual interpretations for test data failing the KS test. Concept-wise, we propose the notion of most comprehensible counterfactual interpretations, which accommodates both the KS test data and the user domain knowledge in producing interpretations. Computation-wise, we develop an efficient algorithm MOCHI that avoids enumerating and checking an exponential number of subsets of the test set failing the KS test. MOCHI not only guarantees to produce the most comprehensible counterfactual interpretations, but also is orders of magnitudes faster than the baselines. Experiment-wise, we present a systematic empirical study on a series of benchmark real datasets to verify the effectiveness, efficiency and scalability of most comprehensible counterfactual interpretations and MOCHI.