 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMammothModa: Multi-Modal Large Language Model
Jun 26, 2024In this report, we introduce MammothModa, yet another multi-modal large language model (MLLM) designed to achieve state-of-the-art performance starting from an elementary baseline. We focus on three key design insights: (i) Integrating Visual Capabilities while Maintaining Complex Language Understanding: In addition to the vision encoder, we incorporated the Visual Attention Experts into the LLM to enhance its visual capabilities. (ii) Extending Context Window for High-Resolution and Long-Duration Visual Feature: We explore the Visual Merger Module to effectively reduce the token number of high-resolution images and incorporated frame position ids to avoid position interpolation. (iii) High-Quality Bilingual Datasets: We meticulously curated and filtered a high-quality bilingual multimodal dataset to reduce visual hallucinations. With above recipe we build MammothModa that consistently outperforms the state-of-the-art models, e.g., LLaVA-series, across main real-world visual language benchmarks without bells and whistles.
PDO-s3DCNNs: Partial Differential Operator Based Steerable 3D CNNs
Aug 07, 2022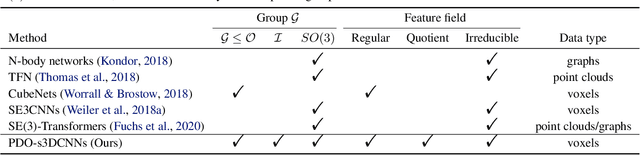
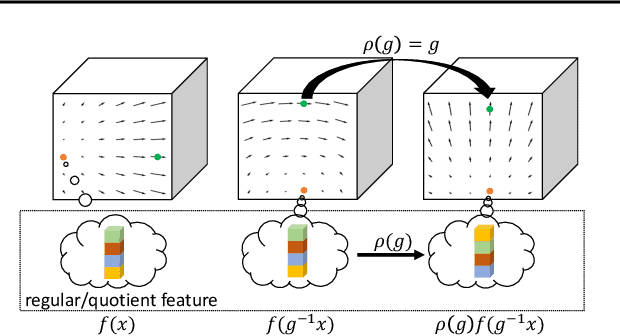

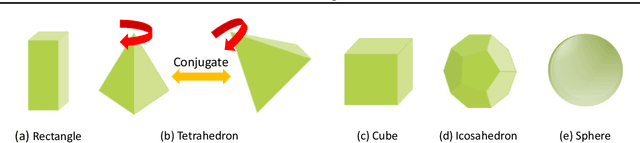
Steerable models can provide very general and flexible equivariance by formulating equivariance requirements in the language of representation theory and feature fields, which has been recognized to be effective for many vision tasks. However, deriving steerable models for 3D rotations is much more difficult than that in the 2D case, due to more complicated mathematics of 3D rotations. In this work, we employ partial differential operators (PDOs) to model 3D filters, and derive general steerable 3D CNNs, which are called PDO-s3DCNNs. We prove that the equivariant filters are subject to linear constraints, which can be solved efficiently under various conditions. As far as we know, PDO-s3DCNNs are the most general steerable CNNs for 3D rotations, in the sense that they cover all common subgroups of $SO(3)$ and their representations, while existing methods can only be applied to specific groups and representations. Extensive experiments show that our models can preserve equivariance well in the discrete domain, and outperform previous works on SHREC'17 retrieval and ISBI 2012 segmentation tasks with a low network complexity.
On Learning Contrastive Representations for Learning with Noisy Labels
Mar 25, 2022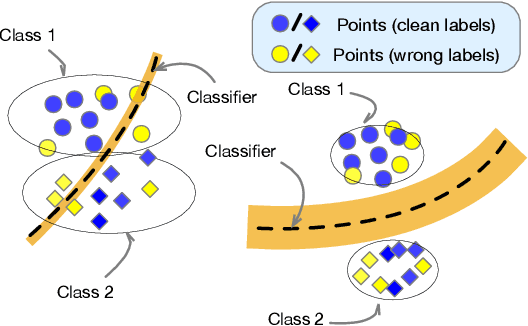
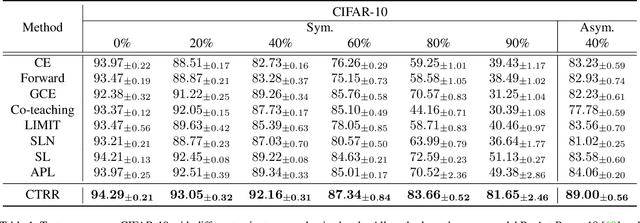
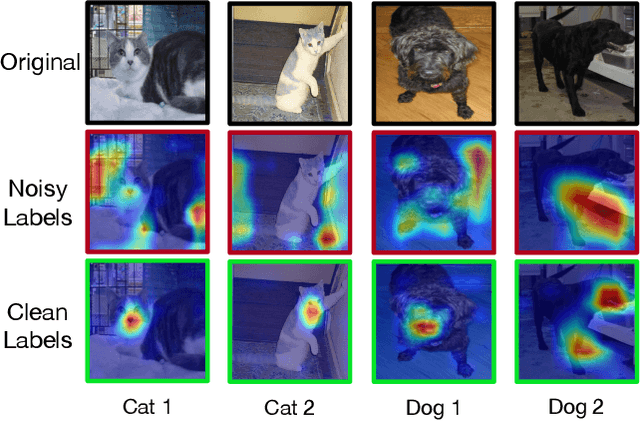
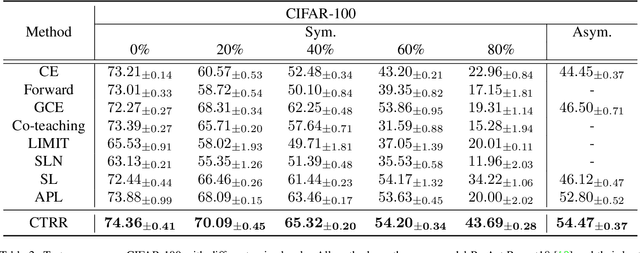
Deep neural networks are able to memorize noisy labels easily with a softmax cross-entropy (CE) loss. Previous studies attempted to address this issue focus on incorporating a noise-robust loss function to the CE loss. However, the memorization issue is alleviated but still remains due to the non-robust CE loss. To address this issue, we focus on learning robust contrastive representations of data on which the classifier is hard to memorize the label noise under the CE loss. We propose a novel contrastive regularization function to learn such representations over noisy data where label noise does not dominate the representation learning. By theoretically investigating the representations induced by the proposed regularization function, we reveal that the learned representations keep information related to true labels and discard information related to corrupted labels. Moreover, our theoretical results also indicate that the learned representations are robust to the label noise. The effectiveness of this method is demonstrated with experiments on benchmark datasets.
Weakly Supervised Object Localization as Domain Adaption
Mar 25, 2022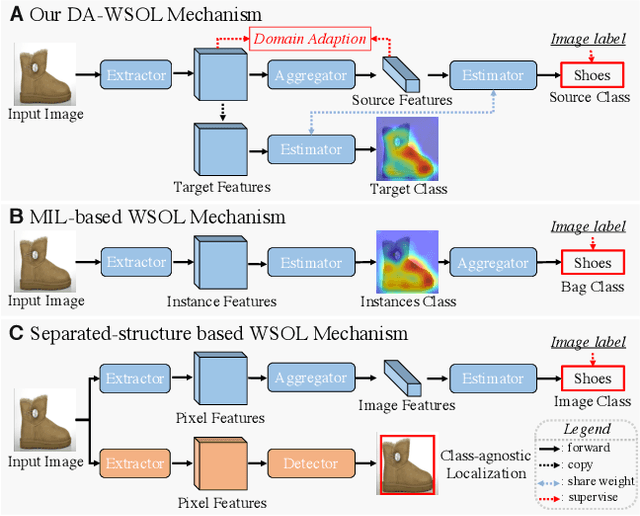
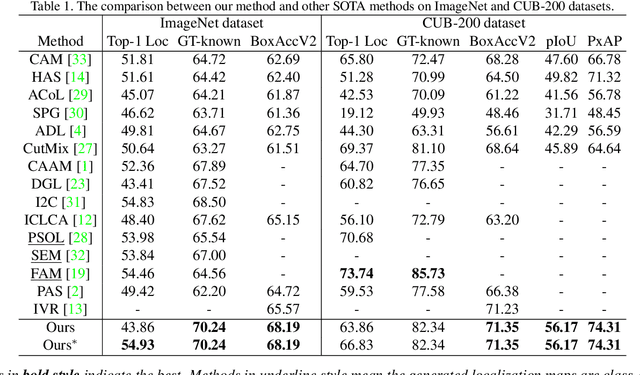
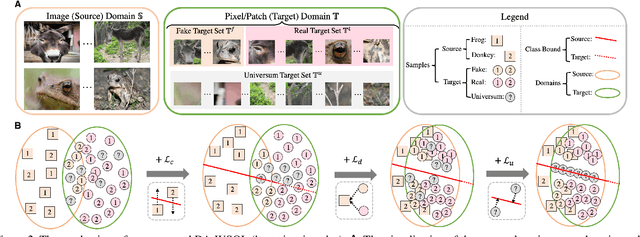
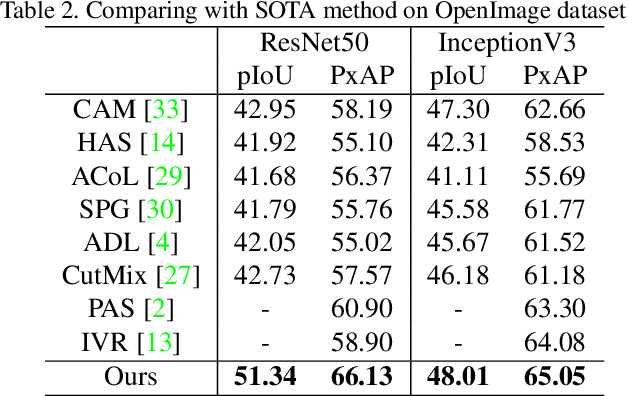
Weakly supervised object localization (WSOL) focuses on localizing objects only with the supervision of image-level classification masks. Most previous WSOL methods follow the classification activation map (CAM) that localizes objects based on the classification structure with the multi-instance learning (MIL) mechanism. However, the MIL mechanism makes CAM only activate discriminative object parts rather than the whole object, weakening its performance for localizing objects. To avoid this problem, this work provides a novel perspective that models WSOL as a domain adaption (DA) task, where the score estimator trained on the source/image domain is tested on the target/pixel domain to locate objects. Under this perspective, a DA-WSOL pipeline is designed to better engage DA approaches into WSOL to enhance localization performance. It utilizes a proposed target sampling strategy to select different types of target samples. Based on these types of target samples, domain adaption localization (DAL) loss is elaborated. It aligns the feature distribution between the two domains by DA and makes the estimator perceive target domain cues by Universum regularization. Experiments show that our pipeline outperforms SOTA methods on multi benchmarks. Code are released at \url{https://github.com/zh460045050/DA-WSOL_CVPR2022}.
Background-aware Classification Activation Map for Weakly Supervised Object Localization
Dec 29, 2021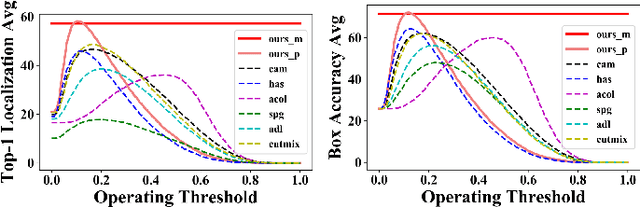
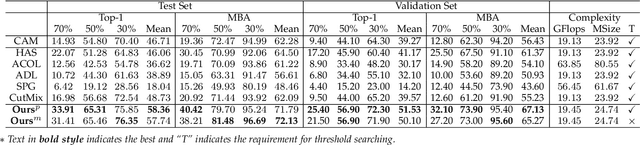

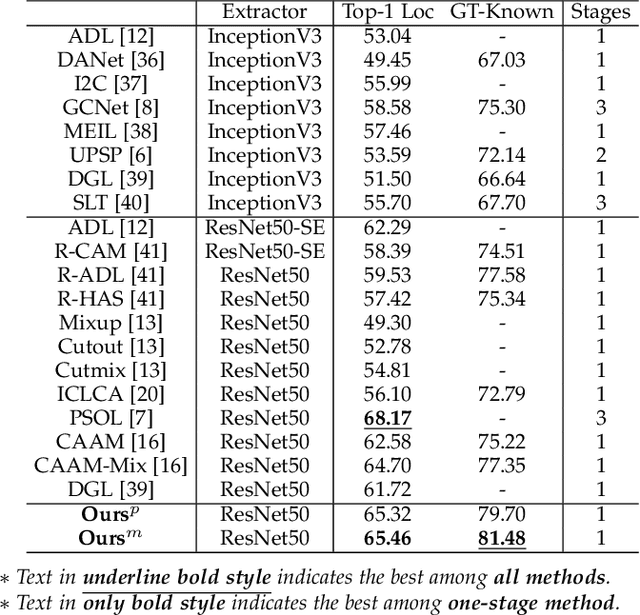
Weakly supervised object localization (WSOL) relaxes the requirement of dense annotations for object localization by using image-level classification masks to supervise its learning process. However, current WSOL methods suffer from excessive activation of background locations and need post-processing to obtain the localization mask. This paper attributes these issues to the unawareness of background cues, and propose the background-aware classification activation map (B-CAM) to simultaneously learn localization scores of both object and background with only image-level labels. In our B-CAM, two image-level features, aggregated by pixel-level features of potential background and object locations, are used to purify the object feature from the object-related background and to represent the feature of the pure-background sample, respectively. Then based on these two features, both the object classifier and the background classifier are learned to determine the binary object localization mask. Our B-CAM can be trained in end-to-end manner based on a proposed stagger classification loss, which not only improves the objects localization but also suppresses the background activation. Experiments show that our B-CAM outperforms one-stage WSOL methods on the CUB-200, OpenImages and VOC2012 datasets.
Learning from Temporal Gradient for Semi-supervised Action Recognition
Dec 06, 2021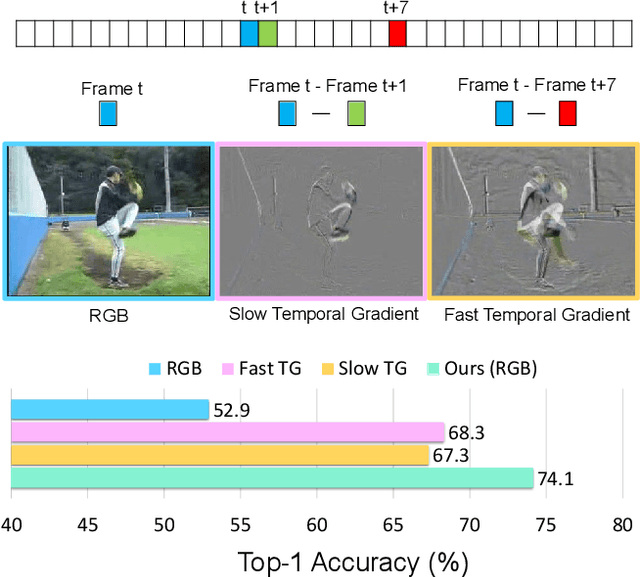
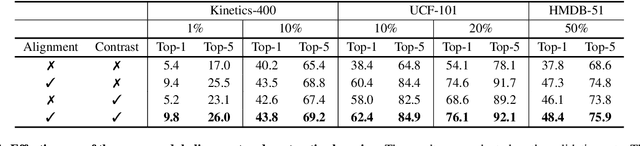
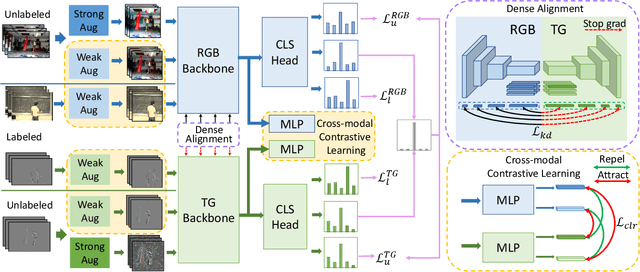
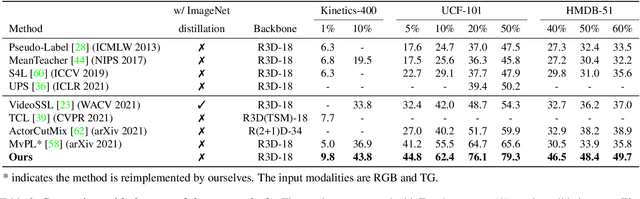
Semi-supervised video action recognition tends to enable deep neural networks to achieve remarkable performance even with very limited labeled data. However, existing methods are mainly transferred from current image-based methods (e.g., FixMatch). Without specifically utilizing the temporal dynamics and inherent multimodal attributes, their results could be suboptimal. To better leverage the encoded temporal information in videos, we introduce temporal gradient as an additional modality for more attentive feature extraction in this paper. To be specific, our method explicitly distills the fine-grained motion representations from temporal gradient (TG) and imposes consistency across different modalities (i.e., RGB and TG). The performance of semi-supervised action recognition is significantly improved without additional computation or parameters during inference. Our method achieves the state-of-the-art performance on three video action recognition benchmarks (i.e., Kinetics-400, UCF-101, and HMDB-51) under several typical semi-supervised settings (i.e., different ratios of labeled data).
TEAM-Net: Multi-modal Learning for Video Action Recognition with Partial Decoding
Oct 17, 2021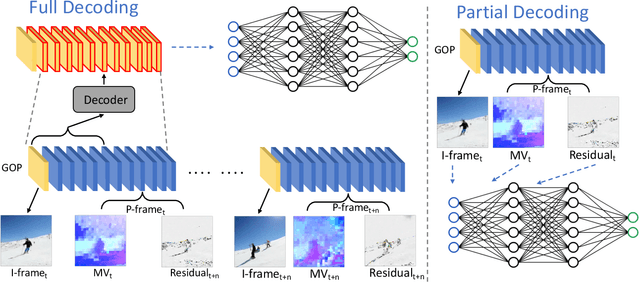


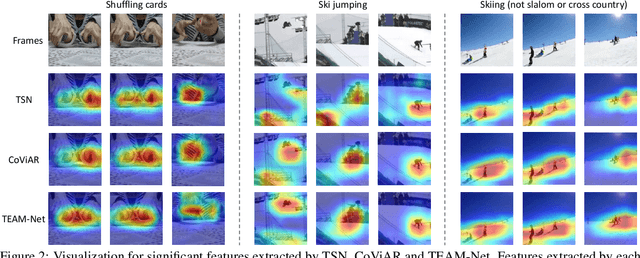
Most of existing video action recognition models ingest raw RGB frames. However, the raw video stream requires enormous storage and contains significant temporal redundancy. Video compression (e.g., H.264, MPEG-4) reduces superfluous information by representing the raw video stream using the concept of Group of Pictures (GOP). Each GOP is composed of the first I-frame (aka RGB image) followed by a number of P-frames, represented by motion vectors and residuals, which can be regarded and used as pre-extracted features. In this work, we 1) introduce sampling the input for the network from partially decoded videos based on the GOP-level, and 2) propose a plug-and-play mulTi-modal lEArning Module (TEAM) for training the network using information from I-frames and P-frames in an end-to-end manner. We demonstrate the superior performance of TEAM-Net compared to the baseline using RGB only. TEAM-Net also achieves the state-of-the-art performance in the area of video action recognition with partial decoding. Code is provided at https://github.com/villawang/TEAM-Net.
3rd Place Solution to Google Landmark Recognition Competition 2021
Oct 07, 2021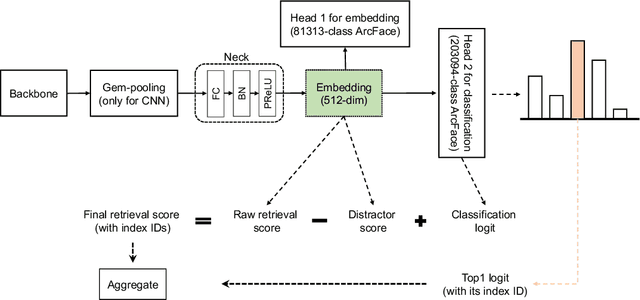
In this paper, we show our solution to the Google Landmark Recognition 2021 Competition. Firstly, embeddings of images are extracted via various architectures (i.e. CNN-, Transformer- and hybrid-based), which are optimized by ArcFace loss. Then we apply an efficient pipeline to re-rank predictions by adjusting the retrieval score with classification logits and non-landmark distractors. Finally, the ensembled model scores 0.489 on the private leaderboard, achieving the 3rd place in the 2021 edition of the Google Landmark Recognition Competition.
MT-ORL: Multi-Task Occlusion Relationship Learning
Aug 18, 2021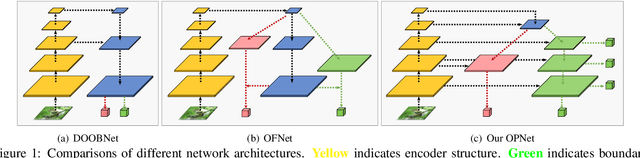
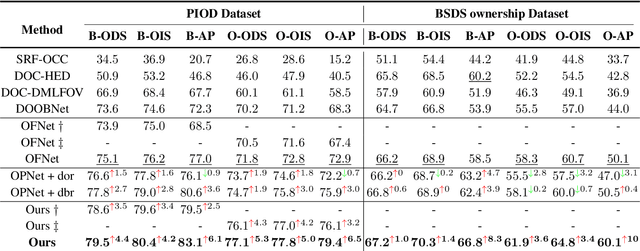
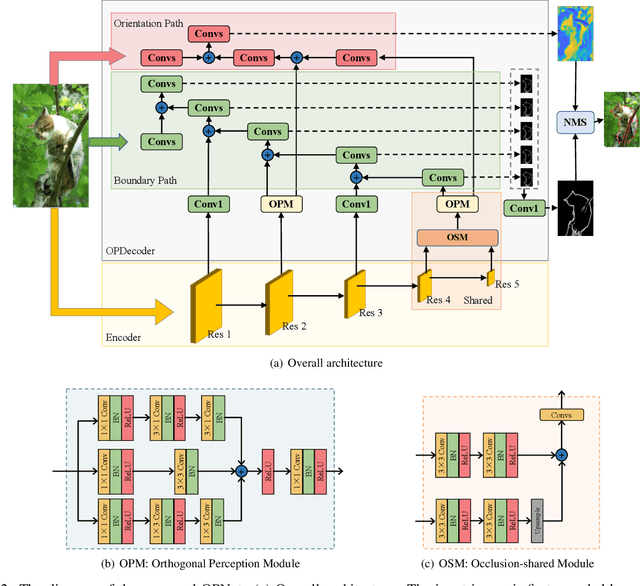
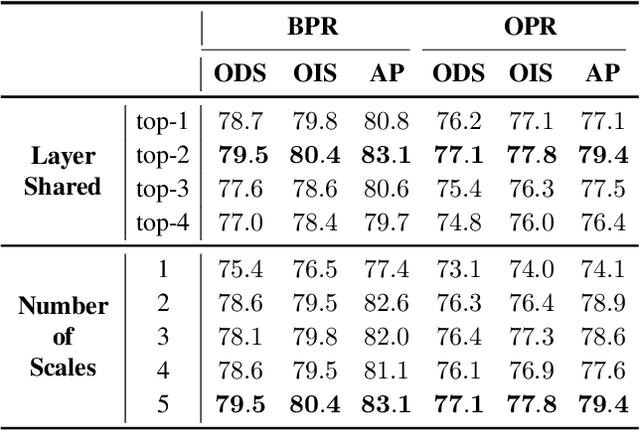
Retrieving occlusion relation among objects in a single image is challenging due to sparsity of boundaries in image. We observe two key issues in existing works: firstly, lack of an architecture which can exploit the limited amount of coupling in the decoder stage between the two subtasks, namely occlusion boundary extraction and occlusion orientation prediction, and secondly, improper representation of occlusion orientation. In this paper, we propose a novel architecture called Occlusion-shared and Path-separated Network (OPNet), which solves the first issue by exploiting rich occlusion cues in shared high-level features and structured spatial information in task-specific low-level features. We then design a simple but effective orthogonal occlusion representation (OOR) to tackle the second issue. Our method surpasses the state-of-the-art methods by 6.1%/8.3% Boundary-AP and 6.5%/10% Orientation-AP on standard PIOD/BSDS ownership datasets. Code is available at https://github.com/fengpanhe/MT-ORL.
Unifying Nonlocal Blocks for Neural Networks
Aug 17, 2021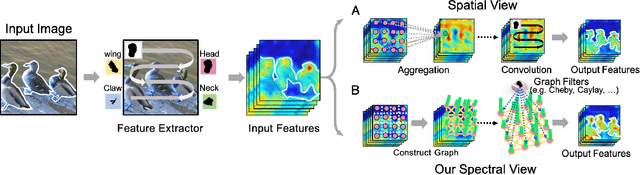

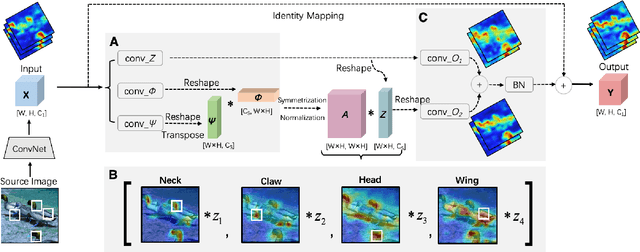
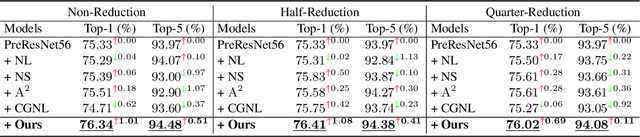
The nonlocal-based blocks are designed for capturing long-range spatial-temporal dependencies in computer vision tasks. Although having shown excellent performance, they still lack the mechanism to encode the rich, structured information among elements in an image or video. In this paper, to theoretically analyze the property of these nonlocal-based blocks, we provide a new perspective to interpret them, where we view them as a set of graph filters generated on a fully-connected graph. Specifically, when choosing the Chebyshev graph filter, a unified formulation can be derived for explaining and analyzing the existing nonlocal-based blocks (e.g., nonlocal block, nonlocal stage, double attention block). Furthermore, by concerning the property of spectral, we propose an efficient and robust spectral nonlocal block, which can be more robust and flexible to catch long-range dependencies when inserted into deep neural networks than the existing nonlocal blocks. Experimental results demonstrate the clear-cut improvements and practical applicabilities of our method on image classification, action recognition, semantic segmentation, and person re-identification tasks.