 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStylePrompter: All Styles Need Is Attention
Jul 30, 2023



GAN inversion aims at inverting given images into corresponding latent codes for Generative Adversarial Networks (GANs), especially StyleGAN where exists a disentangled latent space that allows attribute-based image manipulation at latent level. As most inversion methods build upon Convolutional Neural Networks (CNNs), we transfer a hierarchical vision Transformer backbone innovatively to predict $\mathcal{W^+}$ latent codes at token level. We further apply a Style-driven Multi-scale Adaptive Refinement Transformer (SMART) in $\mathcal{F}$ space to refine the intermediate style features of the generator. By treating style features as queries to retrieve lost identity information from the encoder's feature maps, SMART can not only produce high-quality inverted images but also surprisingly adapt to editing tasks. We then prove that StylePrompter lies in a more disentangled $\mathcal{W^+}$ and show the controllability of SMART. Finally, quantitative and qualitative experiments demonstrate that StylePrompter can achieve desirable performance in balancing reconstruction quality and editability, and is "smart" enough to fit into most edits, outperforming other $\mathcal{F}$-involved inversion methods.
Blind Image Quality Assessment via Transformer Predicted Error Map and Perceptual Quality Token
May 16, 2023



Image quality assessment is a fundamental problem in the field of image processing, and due to the lack of reference images in most practical scenarios, no-reference image quality assessment (NR-IQA), has gained increasing attention recently. With the development of deep learning technology, many deep neural network-based NR-IQA methods have been developed, which try to learn the image quality based on the understanding of database information. Currently, Transformer has achieved remarkable progress in various vision tasks. Since the characteristics of the attention mechanism in Transformer fit the global perceptual impact of artifacts perceived by a human, Transformer is thus well suited for image quality assessment tasks. In this paper, we propose a Transformer based NR-IQA model using a predicted objective error map and perceptual quality token. Specifically, we firstly generate the predicted error map by pre-training one model consisting of a Transformer encoder and decoder, in which the objective difference between the distorted and the reference images is used as supervision. Then, we freeze the parameters of the pre-trained model and design another branch using the vision Transformer to extract the perceptual quality token for feature fusion with the predicted error map. Finally, the fused features are regressed to the final image quality score. Extensive experiments have shown that our proposed method outperforms the current state-of-the-art in both authentic and synthetic image databases. Moreover, the attentional map extracted by the perceptual quality token also does conform to the characteristics of the human visual system.
BASICS: Broad quality Assessment of Static point clouds In Compression Scenarios
Feb 09, 2023



Point clouds are now commonly used to represent 3D scenes in virtual world, in addition to 3D meshes. Their ease of capture enable various applications on mobile devices, such as smartphones or other microcontrollers. Point cloud compression is now at an advanced level and being standardized. Nevertheless, quality assessment databases, which is needed to develop better objective quality metrics, are still limited. In this work, we create a broad quality assessment database for static point clouds, mainly for telepresence scenario. For the sake of completeness, the created database is analyzed using the mean opinion scores, and it is used to benchmark several state-of-the-art quality estimators. The generated database is named Broad quality Assessment of Static point clouds In Compression Scenario (BASICS). Currently, the BASICS database is used as part of the ICIP 2023 Grand Challenge on Point Cloud Quality Assessment, and therefore only a part of the database has been made publicly available at the challenge website. The rest of the database will be made available once the challenge is over.
View Sub-sampling and Reconstruction for Efficient Light Field Compression
Aug 12, 2022
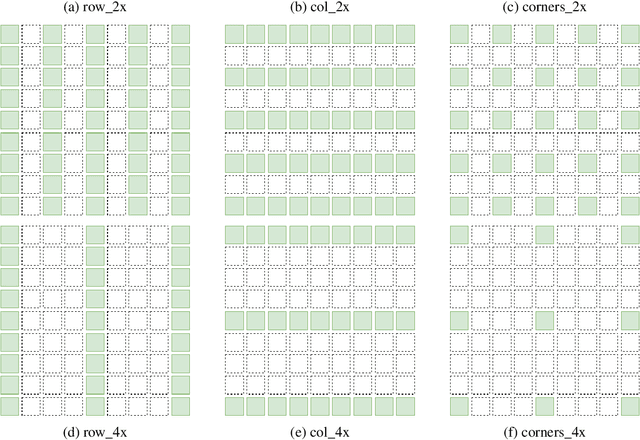
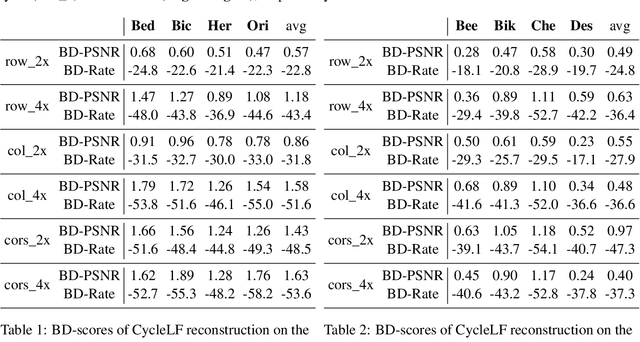
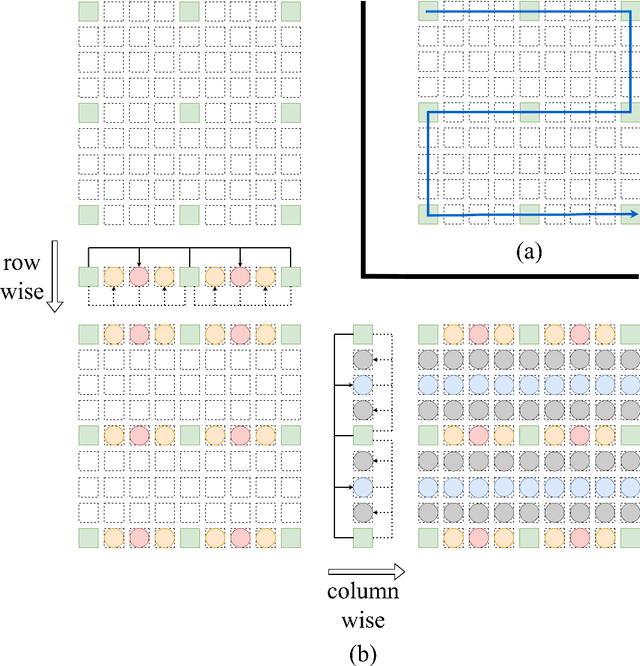
Compression is an important task for many practical applications of light fields. Although previous work has proposed numerous methods for efficient light field compression, the effect of view selection on this task is not well exploited. In this work, we study different sub-sampling and reconstruction strategies for light field compression. We apply various sub-sampling and corresponding reconstruction strategies before and after light field compression. Then, fully reconstructed light fields are assessed to evaluate the performance of different methods. Our evaluation is performed on both real-world and synthetic datasets, and optimal strategies are devised from our experimental results. We hope this study would be beneficial for future research such as light field streaming, storage, and transmission.
Jointformer: Single-Frame Lifting Transformer with Error Prediction and Refinement for 3D Human Pose Estimation
Aug 07, 2022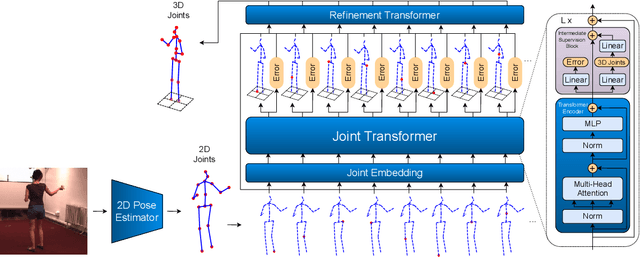
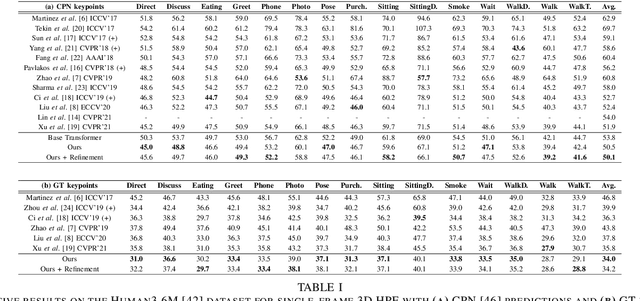
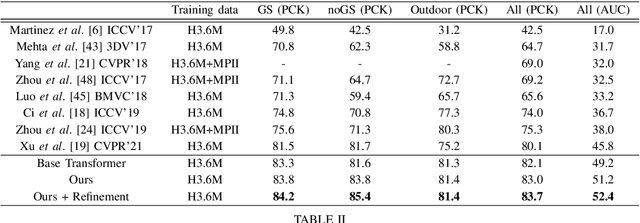
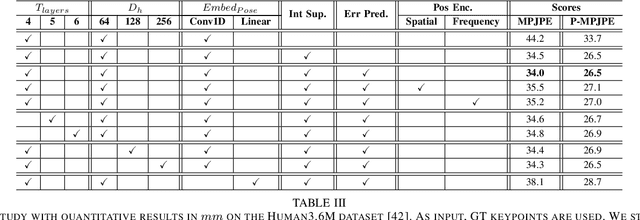
Monocular 3D human pose estimation technologies have the potential to greatly increase the availability of human movement data. The best-performing models for single-image 2D-3D lifting use graph convolutional networks (GCNs) that typically require some manual input to define the relationships between different body joints. We propose a novel transformer-based approach that uses the more generalised self-attention mechanism to learn these relationships within a sequence of tokens representing joints. We find that the use of intermediate supervision, as well as residual connections between the stacked encoders benefits performance. We also suggest that using error prediction as part of a multi-task learning framework improves performance by allowing the network to compensate for its confidence level. We perform extensive ablation studies to show that each of our contributions increases performance. Furthermore, we show that our approach outperforms the recent state of the art for single-frame 3D human pose estimation by a large margin. Our code and trained models are made publicly available on Github.
KinePose: A temporally optimized inverse kinematics technique for 6DOF human pose estimation with biomechanical constraints
Jul 26, 2022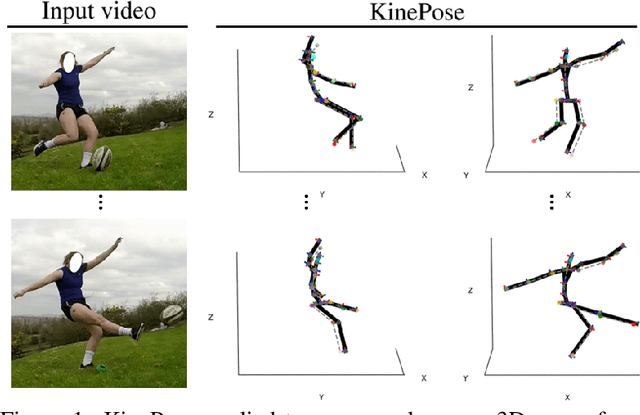

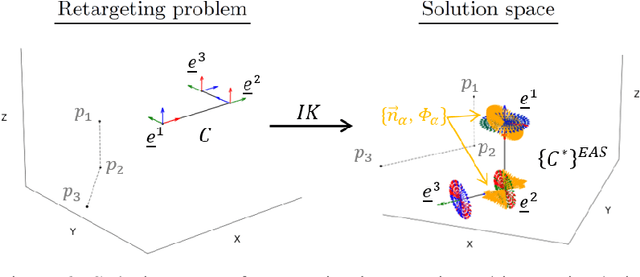
Computer vision/deep learning-based 3D human pose estimation methods aim to localize human joints from images and videos. Pose representation is normally limited to 3D joint positional/translational degrees of freedom (3DOFs), however, a further three rotational DOFs (6DOFs) are required for many potential biomechanical applications. Positional DOFs are insufficient to analytically solve for joint rotational DOFs in a 3D human skeletal model. Therefore, we propose a temporal inverse kinematics (IK) optimization technique to infer joint orientations throughout a biomechanically informed, and subject-specific kinematic chain. For this, we prescribe link directions from a position-based 3D pose estimate. Sequential least squares quadratic programming is used to solve a minimization problem that involves both frame-based pose terms, and a temporal term. The solution space is constrained using joint DOFs, and ranges of motion (ROMs). We generate 3D pose motion sequences to assess the IK approach both for general accuracy, and accuracy in boundary cases. Our temporal algorithm achieves 6DOF pose estimates with low Mean Per Joint Angular Separation (MPJAS) errors (3.7{\deg}/joint overall, & 1.6{\deg}/joint for lower limbs). With frame-by-frame IK we obtain low errors in the case of bent elbows and knees, however, motion sequences with phases of extended/straight limbs results in ambiguity in twist angle. With temporal IK, we reduce ambiguity for these poses, resulting in lower average errors.
* https://kevgildea.github.io/KinePose/
Image Aesthetics Assessment Using Graph Attention Network
Jun 28, 2022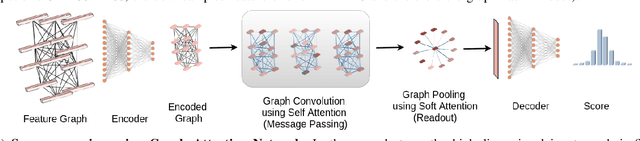
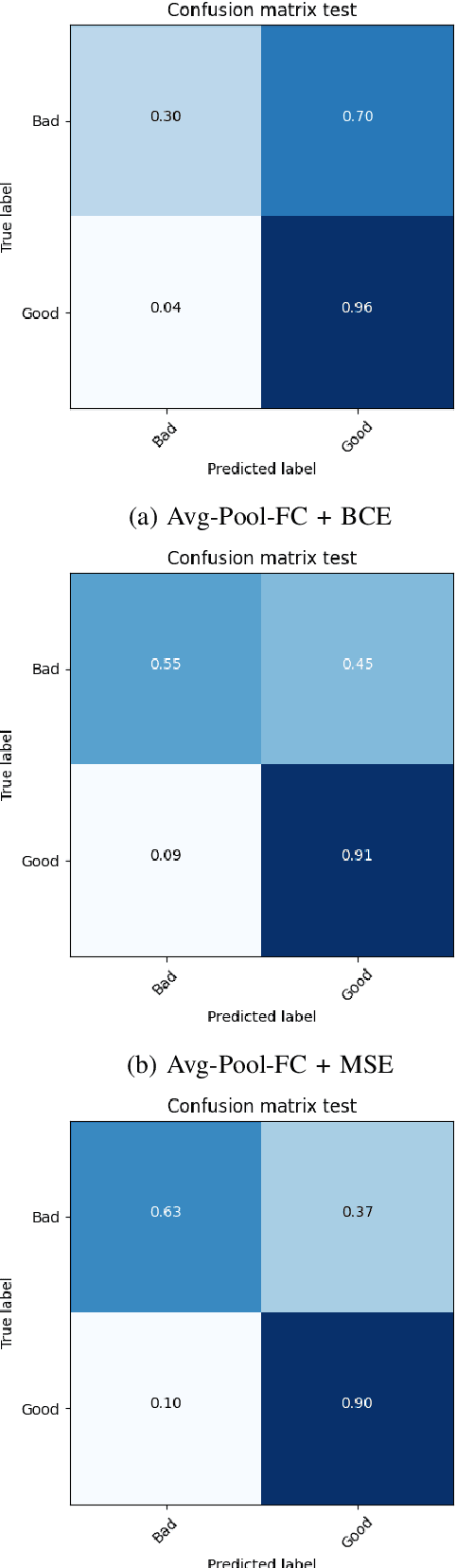
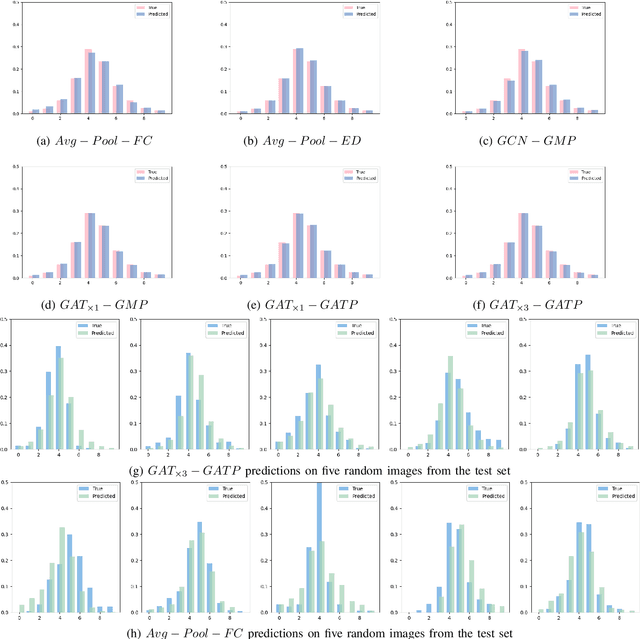

Aspect ratio and spatial layout are two of the principal factors determining the aesthetic value of a photograph. But, incorporating these into the traditional convolution-based frameworks for the task of image aesthetics assessment is problematic. The aspect ratio of the photographs gets distorted while they are resized/cropped to a fixed dimension to facilitate training batch sampling. On the other hand, the convolutional filters process information locally and are limited in their ability to model the global spatial layout of a photograph. In this work, we present a two-stage framework based on graph neural networks and address both these problems jointly. First, we propose a feature-graph representation in which the input image is modelled as a graph, maintaining its original aspect ratio and resolution. Second, we propose a graph neural network architecture that takes this feature-graph and captures the semantic relationship between the different regions of the input image using visual attention. Our experiments show that the proposed framework advances the state-of-the-art results in aesthetic score regression on the Aesthetic Visual Analysis (AVA) benchmark.
TEAM-Net: Multi-modal Learning for Video Action Recognition with Partial Decoding
Oct 17, 2021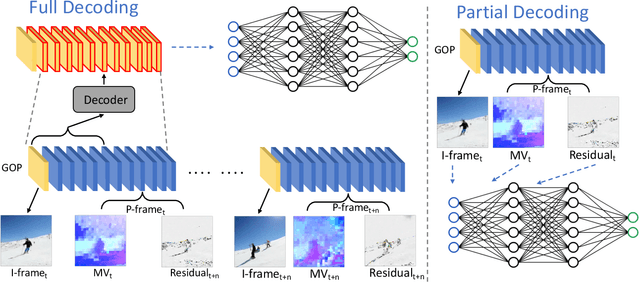


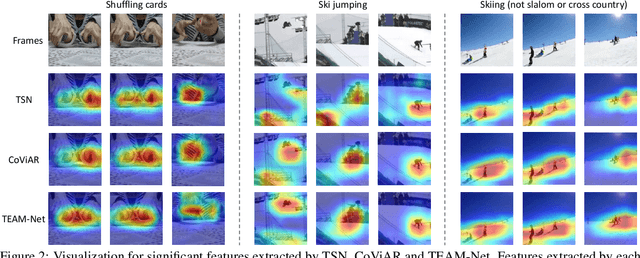
Most of existing video action recognition models ingest raw RGB frames. However, the raw video stream requires enormous storage and contains significant temporal redundancy. Video compression (e.g., H.264, MPEG-4) reduces superfluous information by representing the raw video stream using the concept of Group of Pictures (GOP). Each GOP is composed of the first I-frame (aka RGB image) followed by a number of P-frames, represented by motion vectors and residuals, which can be regarded and used as pre-extracted features. In this work, we 1) introduce sampling the input for the network from partially decoded videos based on the GOP-level, and 2) propose a plug-and-play mulTi-modal lEArning Module (TEAM) for training the network using information from I-frames and P-frames in an end-to-end manner. We demonstrate the superior performance of TEAM-Net compared to the baseline using RGB only. TEAM-Net also achieves the state-of-the-art performance in the area of video action recognition with partial decoding. Code is provided at https://github.com/villawang/TEAM-Net.
Spectral analysis of re-parameterized light fields
Oct 12, 2021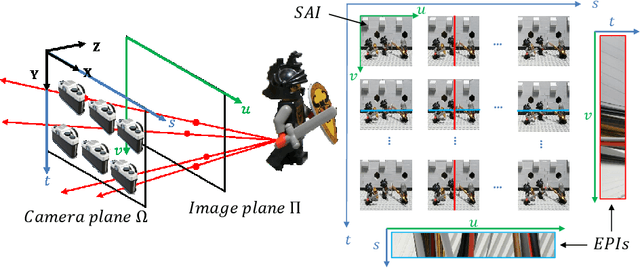
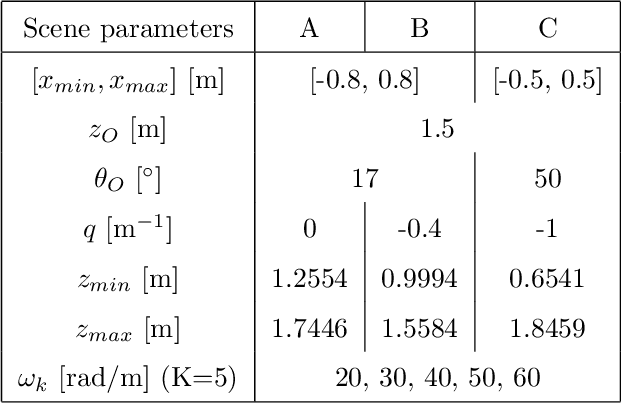
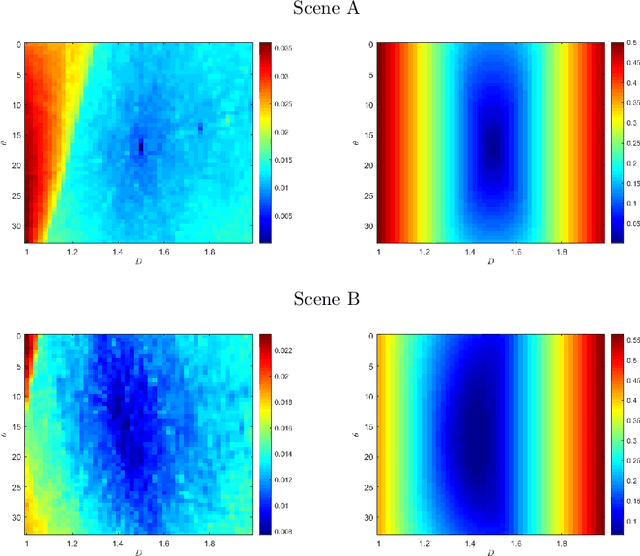
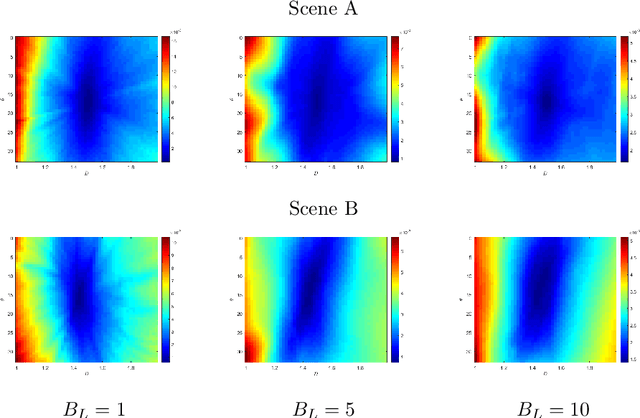
In this paper, we study the spectral properties of re-parameterized light field. Following previous studies of the light field spectrum, which notably provided sampling guidelines, we focus on the two plane parameterization of the light field. However, we introduce additional flexibility by allowing the image plane to be tilted and not only parallel. A formal theoretical analysis is first presented, which shows that more flexible sampling guidelines (i.e. wider camera baselines) can be used to sample the light field when adapting the image plane orientation to the scene geometry. We then present our simulations and results to support these theoretical findings. While the work introduced in this paper is mostly theoretical, we believe these new findings open exciting avenues for more practical application of light fields, such as view synthesis or compact representation.
Frequency Domain Loss Function for Deep Exposure Correction of Dark Images
May 21, 2021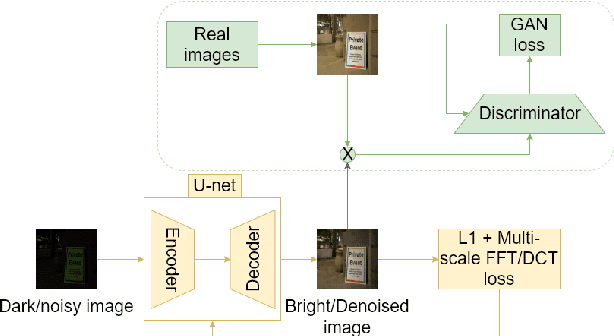
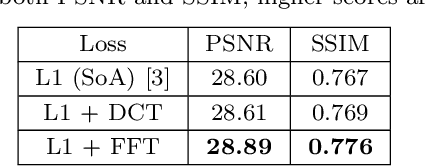
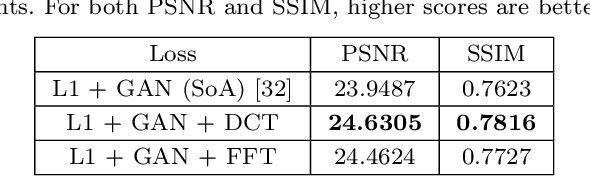

We address the problem of exposure correction of dark, blurry and noisy images captured in low-light conditions in the wild. Classical image-denoising filters work well in the frequency space but are constrained by several factors such as the correct choice of thresholds, frequency estimates etc. On the other hand, traditional deep networks are trained end-to-end in the RGB space by formulating this task as an image-translation problem. However, that is done without any explicit constraints on the inherent noise of the dark images and thus produce noisy and blurry outputs. To this end we propose a DCT/FFT based multi-scale loss function, which when combined with traditional losses, trains a network to translate the important features for visually pleasing output. Our loss function is end-to-end differentiable, scale-agnostic, and generic; i.e., it can be applied to both RAW and JPEG images in most existing frameworks without additional overhead. Using this loss function, we report significant improvements over the state-of-the-art using quantitative metrics and subjective tests.