 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQi Liu
Multi-Dimensional Ability Diagnosis for Machine Learning Algorithms
Jul 14, 2023
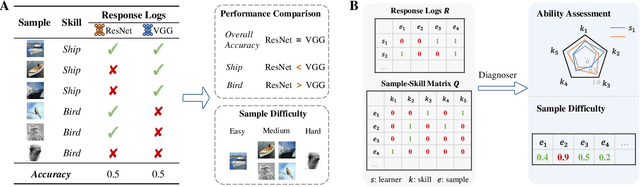
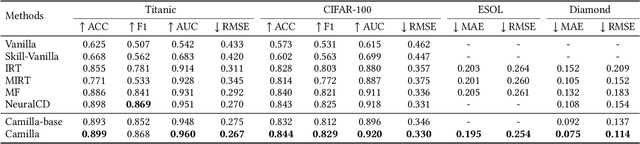
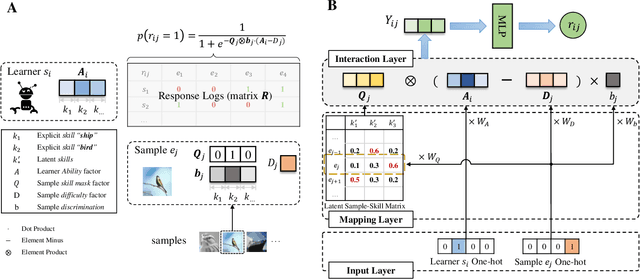
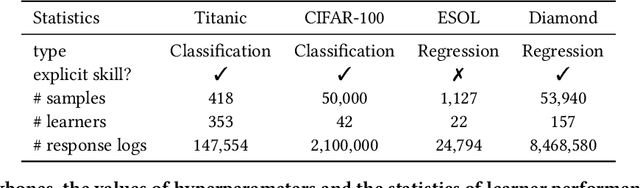
Machine learning algorithms have become ubiquitous in a number of applications (e.g. image classification). However, due to the insufficient measurement of traditional metrics (e.g. the coarse-grained Accuracy of each classifier), substantial gaps are usually observed between the real-world performance of these algorithms and their scores in standardized evaluations. In this paper, inspired by the psychometric theories from human measurement, we propose a task-agnostic evaluation framework Camilla, where a multi-dimensional diagnostic metric Ability is defined for collaboratively measuring the multifaceted strength of each machine learning algorithm. Specifically, given the response logs from different algorithms to data samples, we leverage cognitive diagnosis assumptions and neural networks to learn the complex interactions among algorithms, samples and the skills (explicitly or implicitly pre-defined) of each sample. In this way, both the abilities of each algorithm on multiple skills and some of the sample factors (e.g. sample difficulty) can be simultaneously quantified. We conduct extensive experiments with hundreds of machine learning algorithms on four public datasets, and our experimental results demonstrate that Camilla not only can capture the pros and cons of each algorithm more precisely, but also outperforms state-of-the-art baselines on the metric reliability, rank consistency and rank stability.
NS4AR: A new, focused on sampling areas sampling method in graphical recommendation Systems
Jul 13, 2023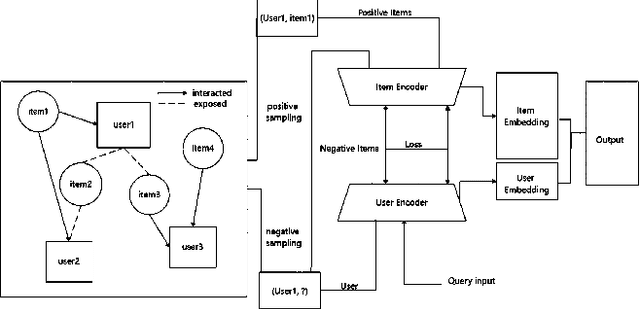

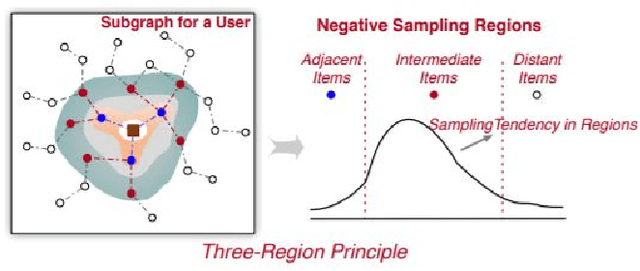

The effectiveness of graphical recommender system depends on the quantity and quality of negative sampling. This paper selects some typical recommender system models, as well as some latest negative sampling strategies on the models as baseline. Based on typical graphical recommender model, we divide sample region into assigned-n areas and use AdaSim to give different weight to these areas to form positive set and negative set. Because of the volume and significance of negative items, we also proposed a subset selection model to narrow the core negative samples.
A Systematic Survey in Geometric Deep Learning for Structure-based Drug Design
Jul 03, 2023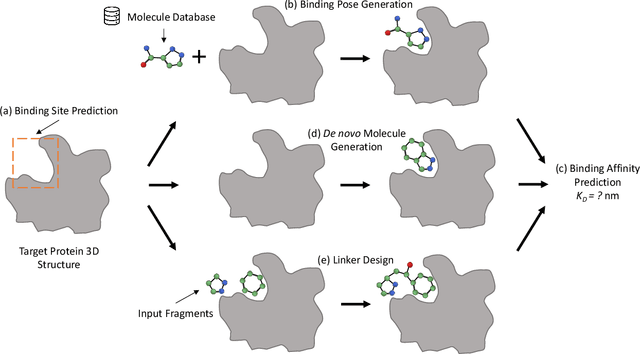
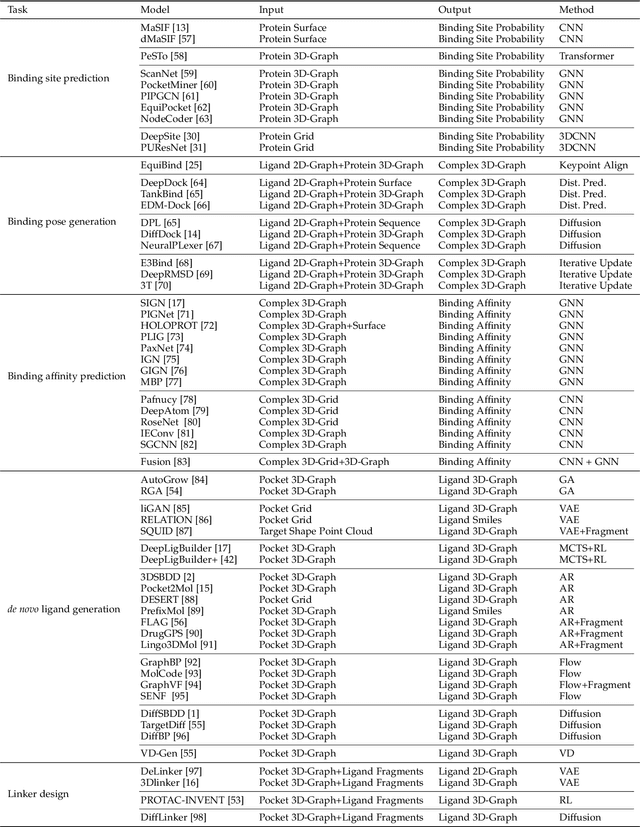
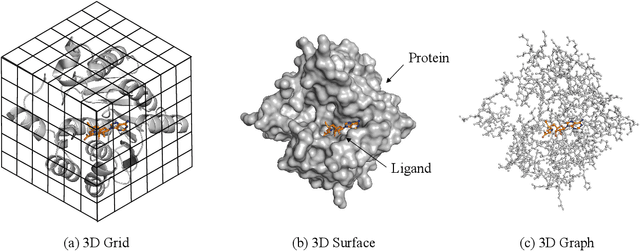
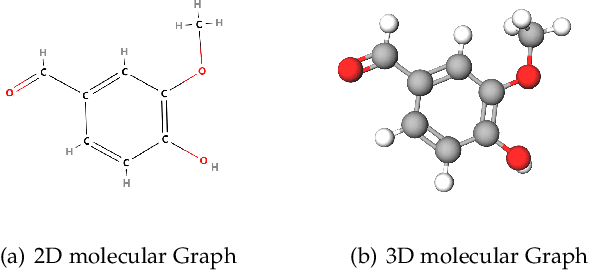
Structure-based drug design (SBDD), which utilizes the three-dimensional geometry of proteins to identify potential drug candidates, is becoming increasingly vital in drug discovery. However, traditional methods based on physiochemical modeling and experts' domain knowledge are time-consuming and laborious. The recent advancements in geometric deep learning, which integrates and processes 3D geometric data, coupled with the availability of accurate protein 3D structure predictions from tools like AlphaFold, have significantly propelled progress in structure-based drug design. In this paper, we systematically review the recent progress of geometric deep learning for structure-based drug design. We start with a brief discussion of the mainstream tasks in structure-based drug design, commonly used 3D protein representations and representative predictive/generative models. Then we delve into detailed reviews for each task (binding site prediction, binding pose generation, \emph{de novo} molecule generation, linker design, and binding affinity prediction), including the problem setup, representative methods, datasets, and evaluation metrics. Finally, we conclude this survey with the current challenges and highlight potential opportunities of geometric deep learning for structure-based drug design.We curate a GitHub repo containing the related papers \url{https://github.com/zaixizhang/Awesome-SBDD}.
Feasibility of Universal Anomaly Detection without Knowing the Abnormality in Medical Images
Jul 03, 2023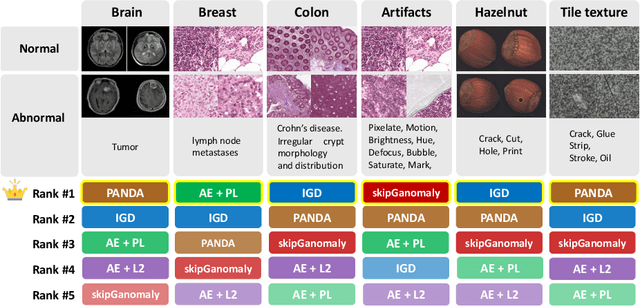
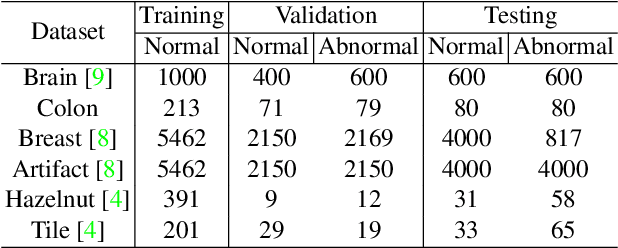
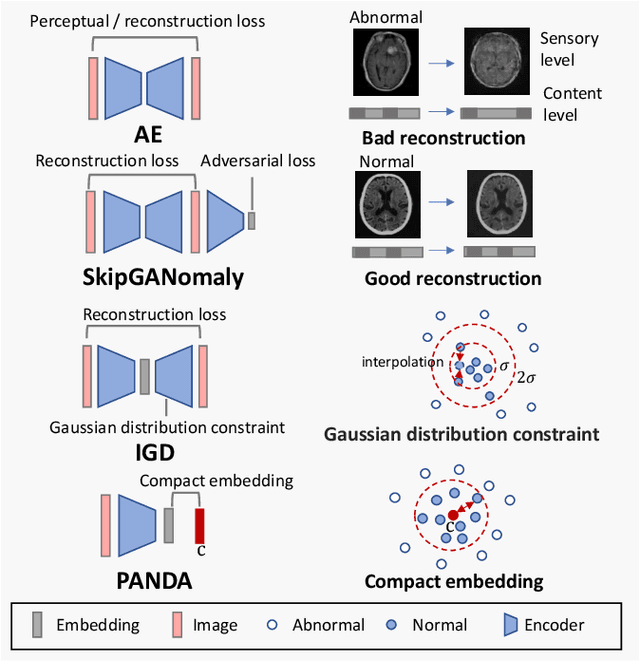
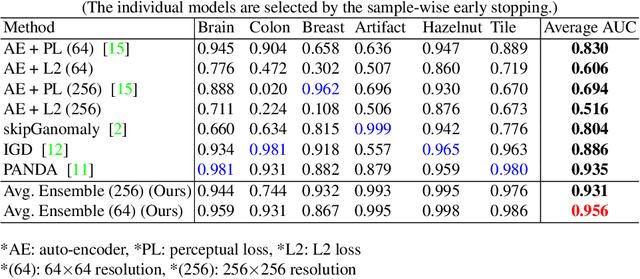
Many anomaly detection approaches, especially deep learning methods, have been recently developed to identify abnormal image morphology by only employing normal images during training. Unfortunately, many prior anomaly detection methods were optimized for a specific "known" abnormality (e.g., brain tumor, bone fraction, cell types). Moreover, even though only the normal images were used in the training process, the abnormal images were oftenly employed during the validation process (e.g., epoch selection, hyper-parameter tuning), which might leak the supposed ``unknown" abnormality unintentionally. In this study, we investigated these two essential aspects regarding universal anomaly detection in medical images by (1) comparing various anomaly detection methods across four medical datasets, (2) investigating the inevitable but often neglected issues on how to unbiasedly select the optimal anomaly detection model during the validation phase using only normal images, and (3) proposing a simple decision-level ensemble method to leverage the advantage of different kinds of anomaly detection without knowing the abnormality. The results of our experiments indicate that none of the evaluated methods consistently achieved the best performance across all datasets. Our proposed method enhanced the robustness of performance in general (average AUC 0.956).
Recognizing Unseen Objects via Multimodal Intensive Knowledge Graph Propagation
Jun 21, 2023
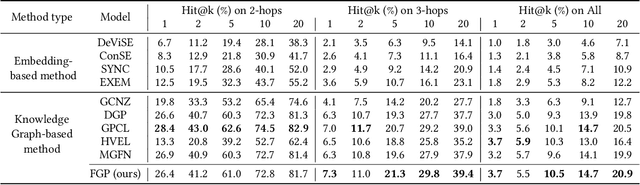
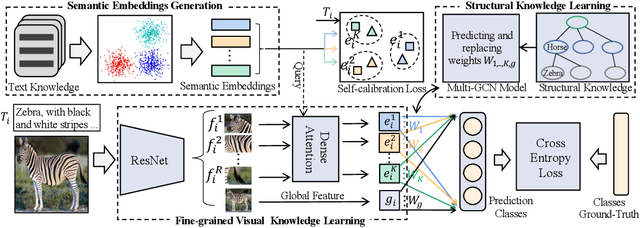
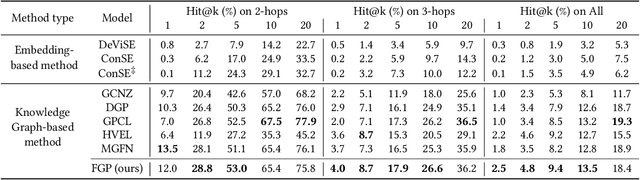
Zero-Shot Learning (ZSL), which aims at automatically recognizing unseen objects, is a promising learning paradigm to understand new real-world knowledge for machines continuously. Recently, the Knowledge Graph (KG) has been proven as an effective scheme for handling the zero-shot task with large-scale and non-attribute data. Prior studies always embed relationships of seen and unseen objects into visual information from existing knowledge graphs to promote the cognitive ability of the unseen data. Actually, real-world knowledge is naturally formed by multimodal facts. Compared with ordinary structural knowledge from a graph perspective, multimodal KG can provide cognitive systems with fine-grained knowledge. For example, the text description and visual content can depict more critical details of a fact than only depending on knowledge triplets. Unfortunately, this multimodal fine-grained knowledge is largely unexploited due to the bottleneck of feature alignment between different modalities. To that end, we propose a multimodal intensive ZSL framework that matches regions of images with corresponding semantic embeddings via a designed dense attention module and self-calibration loss. It makes the semantic transfer process of our ZSL framework learns more differentiated knowledge between entities. Our model also gets rid of the performance limitation of only using rough global features. We conduct extensive experiments and evaluate our model on large-scale real-world data. The experimental results clearly demonstrate the effectiveness of the proposed model in standard zero-shot classification tasks.
Efficiently Measuring the Cognitive Ability of LLMs: An Adaptive Testing Perspective
Jun 18, 2023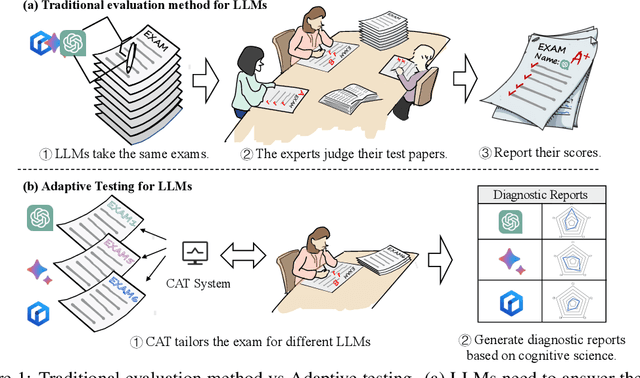
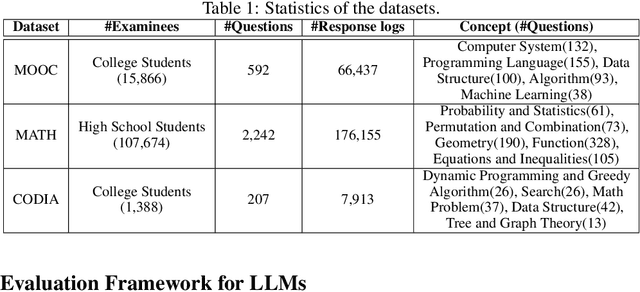
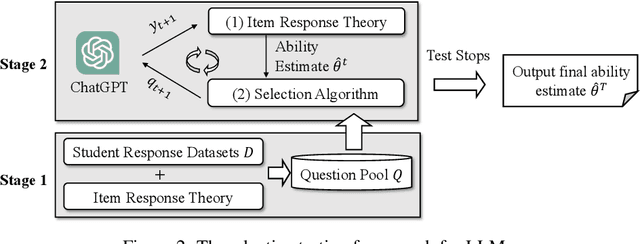
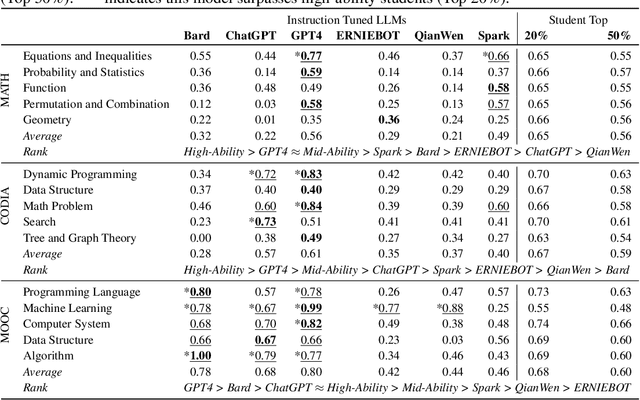
Large language models (LLMs), like ChatGPT, have shown some human-like cognitive abilities. For comparing these abilities of different models, several benchmarks (i.e. sets of standard test questions) from different fields (e.g., Literature, Biology and Psychology) are often adopted and the test results under traditional metrics such as accuracy, recall and F1, are reported. However, such way for evaluating LLMs can be inefficient and inaccurate from the cognitive science perspective. Inspired by Computerized Adaptive Testing (CAT) used in psychometrics, we propose an adaptive testing framework for LLM evaluation. Rather than using a standard test set and simply reporting accuracy, this approach dynamically adjusts the characteristics of the test questions, such as difficulty, based on the model's performance. This allows for a more accurate estimation of the model's abilities, using fewer questions. More importantly, it allows LLMs to be compared with humans easily, which is essential for NLP models that aim for human-level ability. Our diagnostic reports have found that ChatGPT often behaves like a ``careless student'', prone to slip and occasionally guessing the questions. We conduct a fine-grained diagnosis and rank the latest 6 instruction-tuned LLMs from three aspects of Subject Knowledge, Mathematical Reasoning, and Programming, where GPT4 can outperform other models significantly and reach the cognitive ability of middle-level students. Different tests for different models using efficient adaptive testing -- we believe this has the potential to become a new norm in evaluating large language models.
MSSRNet: Manipulating Sequential Style Representation for Unsupervised Text Style Transfer
Jun 12, 2023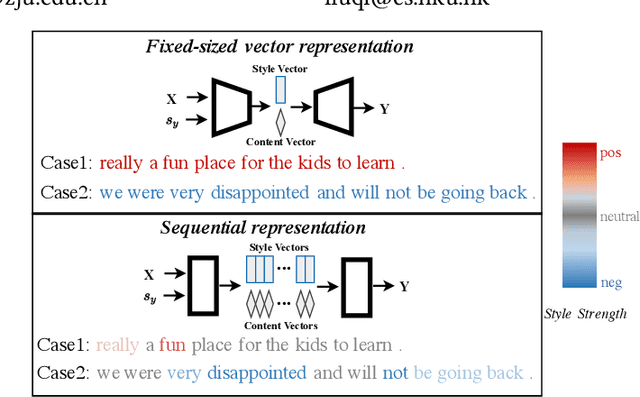
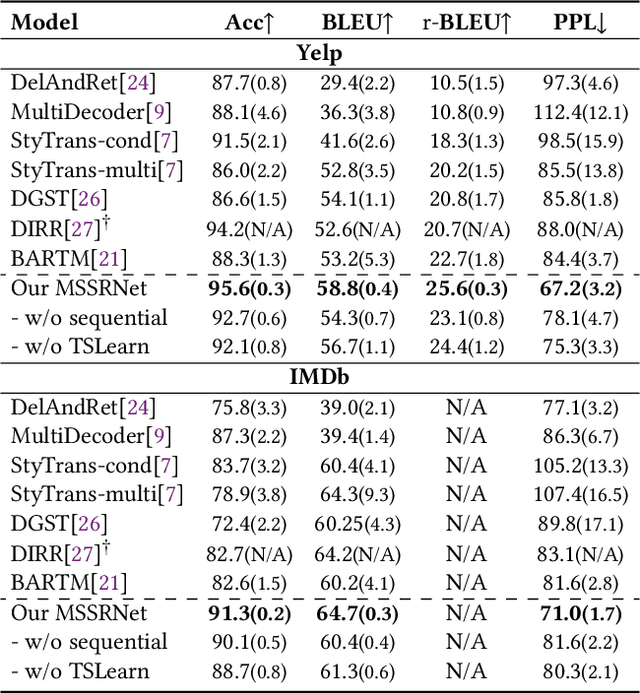
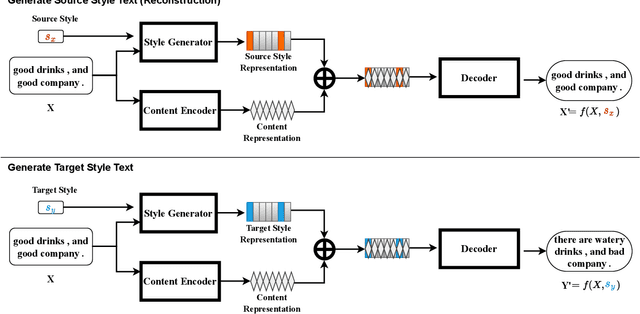

Unsupervised text style transfer task aims to rewrite a text into target style while preserving its main content. Traditional methods rely on the use of a fixed-sized vector to regulate text style, which is difficult to accurately convey the style strength for each individual token. In fact, each token of a text contains different style intensity and makes different contribution to the overall style. Our proposed method addresses this issue by assigning individual style vector to each token in a text, allowing for fine-grained control and manipulation of the style strength. Additionally, an adversarial training framework integrated with teacher-student learning is introduced to enhance training stability and reduce the complexity of high-dimensional optimization. The results of our experiments demonstrate the efficacy of our method in terms of clearly improved style transfer accuracy and content preservation in both two-style transfer and multi-style transfer settings.