 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Latent Actor-Critic: Deep Reinforcement Learning with a Latent Variable Model
Jul 01, 2019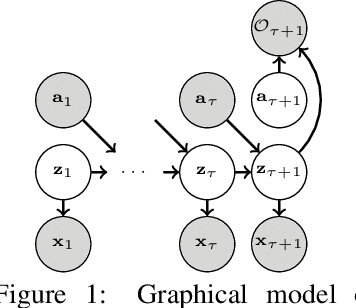
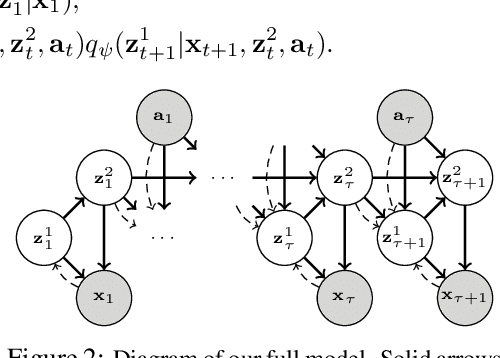

Deep reinforcement learning (RL) algorithms can use high-capacity deep networks to learn directly from image observations. However, these kinds of observation spaces present a number of challenges in practice, since the policy must now solve two problems: a representation learning problem, and a task learning problem. In this paper, we aim to explicitly learn representations that can accelerate reinforcement learning from images. We propose the stochastic latent actor-critic (SLAC) algorithm: a sample-efficient and high-performing RL algorithm for learning policies for complex continuous control tasks directly from high-dimensional image inputs. SLAC learns a compact latent representation space using a stochastic sequential latent variable model, and then learns a critic model within this latent space. By learning a critic within a compact state space, SLAC can learn much more efficiently than standard RL methods. The proposed model improves performance substantially over alternative representations as well, such as variational autoencoders. In fact, our experimental evaluation demonstrates that the sample efficiency of our resulting method is comparable to that of model-based RL methods that directly use a similar type of model for control. Furthermore, our method outperforms both model-free and model-based alternatives in terms of final performance and sample efficiency, on a range of difficult image-based control tasks.
On the Feasibility of Learning, Rather than Assuming, Human Biases for Reward Inference
Jun 23, 2019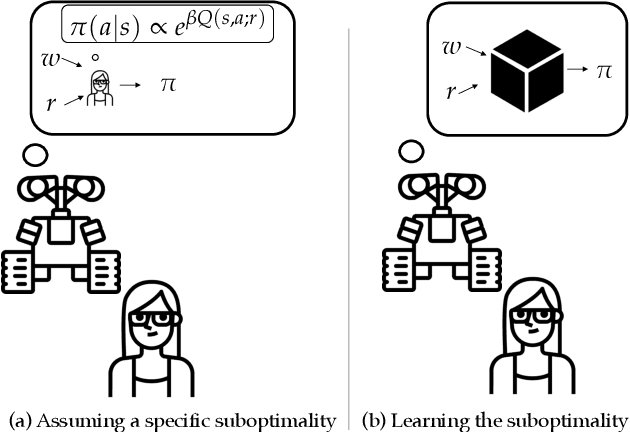
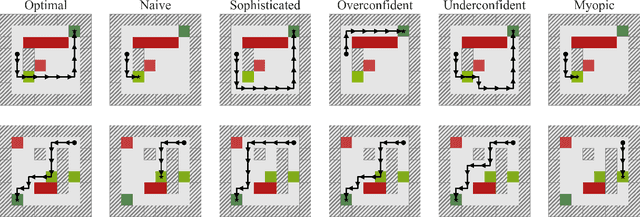
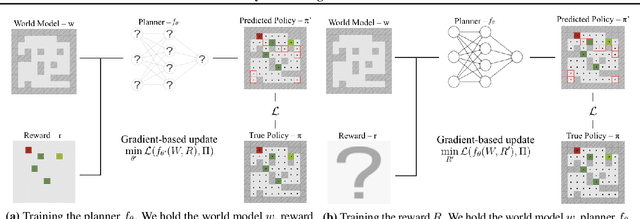
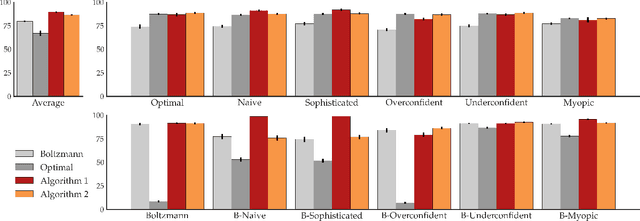
Our goal is for agents to optimize the right reward function, despite how difficult it is for us to specify what that is. Inverse Reinforcement Learning (IRL) enables us to infer reward functions from demonstrations, but it usually assumes that the expert is noisily optimal. Real people, on the other hand, often have systematic biases: risk-aversion, myopia, etc. One option is to try to characterize these biases and account for them explicitly during learning. But in the era of deep learning, a natural suggestion researchers make is to avoid mathematical models of human behavior that are fraught with specific assumptions, and instead use a purely data-driven approach. We decided to put this to the test -- rather than relying on assumptions about which specific bias the demonstrator has when planning, we instead learn the demonstrator's planning algorithm that they use to generate demonstrations, as a differentiable planner. Our exploration yielded mixed findings: on the one hand, learning the planner can lead to better reward inference than relying on the wrong assumption; on the other hand, this benefit is dwarfed by the loss we incur by going from an exact to a differentiable planner. This suggest that at least for the foreseeable future, agents need a middle ground between the flexibility of data-driven methods and the useful bias of known human biases. Code is available at https://tinyurl.com/learningbiases.
Evaluating Protein Transfer Learning with TAPE
Jun 19, 2019
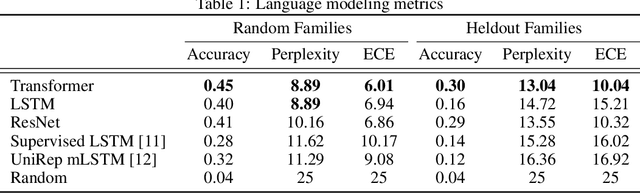
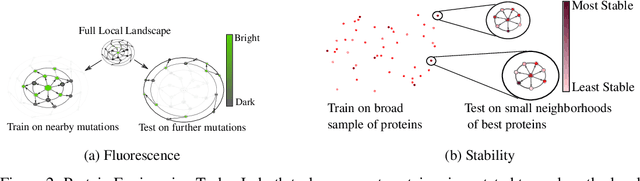
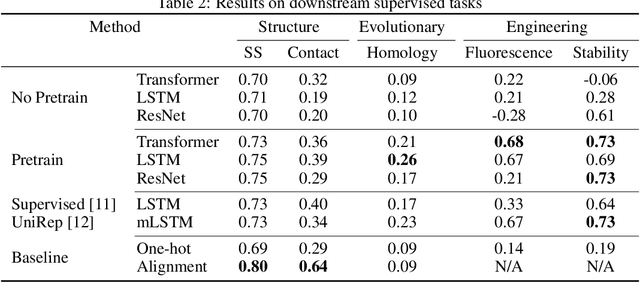
Protein modeling is an increasingly popular area of machine learning research. Semi-supervised learning has emerged as an important paradigm in protein modeling due to the high cost of acquiring supervised protein labels, but the current literature is fragmented when it comes to datasets and standardized evaluation techniques. To facilitate progress in this field, we introduce the Tasks Assessing Protein Embeddings (TAPE), a set of five biologically relevant semi-supervised learning tasks spread across different domains of protein biology. We curate tasks into specific training, validation, and test splits to ensure that each task tests biologically relevant generalization that transfers to real-life scenarios. We benchmark a range of approaches to semi-supervised protein representation learning, which span recent work as well as canonical sequence learning techniques. We find that self-supervised pretraining is helpful for almost all models on all tasks, more than doubling performance in some cases. Despite this increase, in several cases features learned by self-supervised pretraining still lag behind features extracted by state-of-the-art non-neural techniques. This gap in performance suggests a huge opportunity for innovative architecture design and improved modeling paradigms that better capture the signal in biological sequences. TAPE will help the machine learning community focus effort on scientifically relevant problems. Toward this end, all data and code used to run these experiments are available at https://github.com/songlab-cal/tape.
Goal-conditioned Imitation Learning
Jun 13, 2019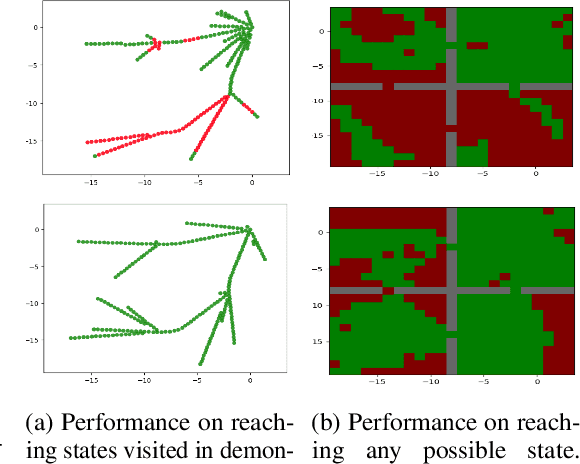

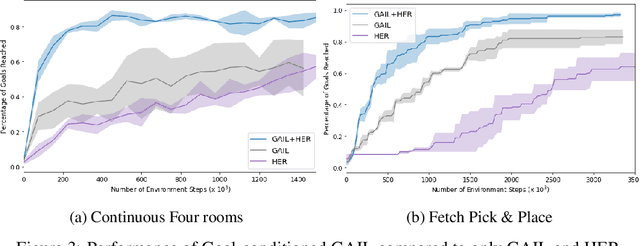
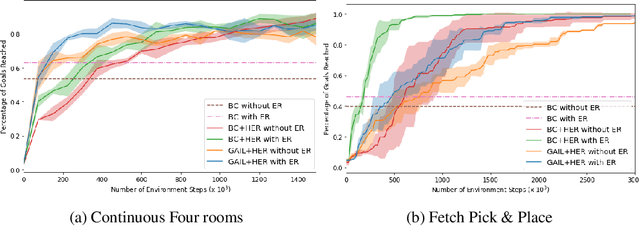
Designing rewards for Reinforcement Learning (RL) is challenging because it needs to convey the desired task, be efficient to optimize, and be easy to compute. The latter is particularly problematic when applying RL to robotics, where detecting whether the desired configuration is reached might require considerable supervision and instrumentation. Furthermore, we are often interested in being able to reach a wide range of configurations, hence setting up a different reward every time might be unpractical. Methods like Hindsight Experience Replay (HER) have recently shown promise to learn policies able to reach many goals, without the need of a reward. Unfortunately, without tricks like resetting to points along the trajectory, HER might take a very long time to discover how to reach certain areas of the state-space. In this work we investigate different approaches to incorporate demonstrations to drastically speed up the convergence to a policy able to reach any goal, also surpassing the performance of an agent trained with other Imitation Learning algorithms. Furthermore, our method can be used when only trajectories without expert actions are available, which can leverage kinestetic or third person demonstration. The code is available at https://sites.google.com/view/goalconditioned-il/ .
Sub-policy Adaptation for Hierarchical Reinforcement Learning
Jun 13, 2019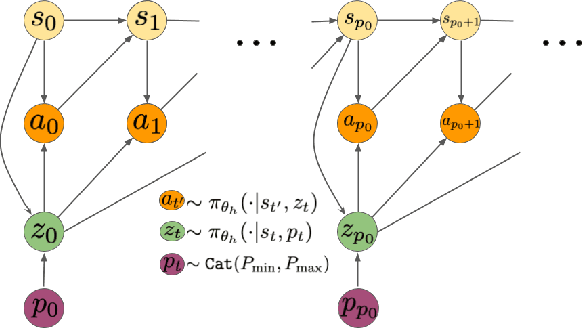
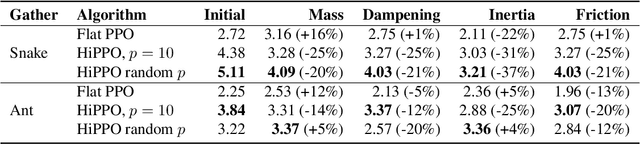
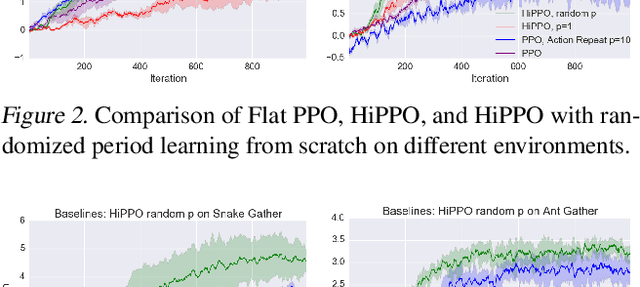
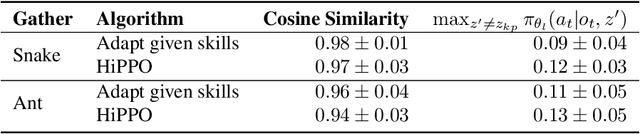
Hierarchical Reinforcement Learning is a promising approach to long-horizon decision-making problems with sparse rewards. Unfortunately, most methods still decouple the lower-level skill acquisition process and the training of a higher level that controls the skills in a new task. Treating the skills as fixed can lead to significant sub-optimality in the transfer setting. In this work, we propose a novel algorithm to discover a set of skills, and continuously adapt them along with the higher level even when training on a new task. Our main contributions are two-fold. First, we derive a new hierarchical policy gradient, as well as an unbiased latent-dependent baseline. We introduce Hierarchical Proximal Policy Optimization (HiPPO), an on-policy method to efficiently train all levels of the hierarchy simultaneously. Second, we propose a method of training time-abstractions that improves the robustness of the obtained skills to environment changes. Code and results are available at sites.google.com/view/hippo-rl .
Bit-Swap: Recursive Bits-Back Coding for Lossless Compression with Hierarchical Latent Variables
Jun 05, 2019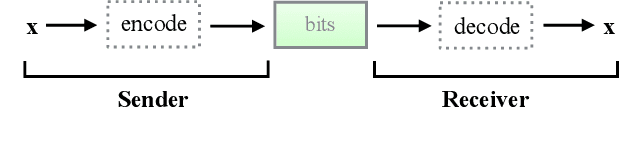

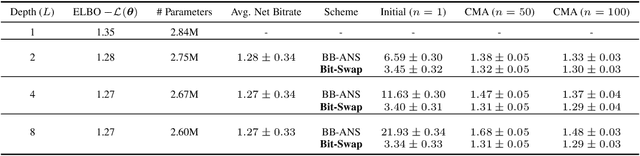
The bits-back argument suggests that latent variable models can be turned into lossless compression schemes. Translating the bits-back argument into efficient and practical lossless compression schemes for general latent variable models, however, is still an open problem. Bits-Back with Asymmetric Numeral Systems (BB-ANS), recently proposed by Townsend et al. (2019), makes bits-back coding practically feasible for latent variable models with one latent layer, but it is inefficient for hierarchical latent variable models. In this paper we propose Bit-Swap, a new compression scheme that generalizes BB-ANS and achieves strictly better compression rates for hierarchical latent variable models with Markov chain structure. Through experiments we verify that Bit-Swap results in lossless compression rates that are empirically superior to existing techniques. Our implementation is available at https://github.com/fhkingma/bitswap.
Learning latent state representation for speeding up exploration
May 27, 2019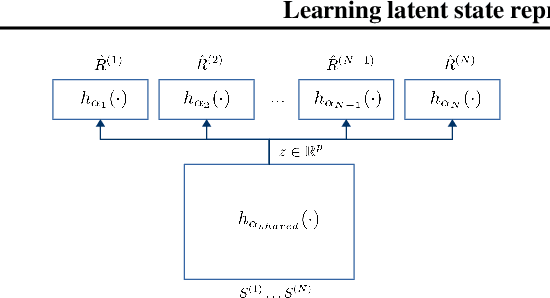
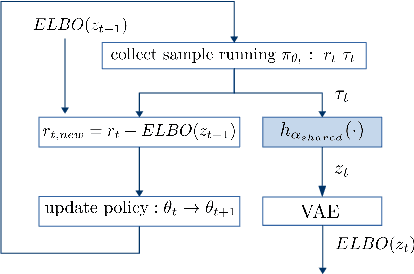
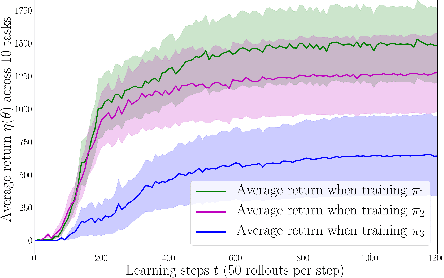
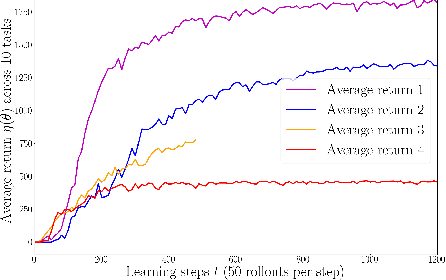
Exploration is an extremely challenging problem in reinforcement learning, especially in high dimensional state and action spaces and when only sparse rewards are available. Effective representations can indicate which components of the state are task relevant and thus reduce the dimensionality of the space to explore. In this work, we take a representation learning viewpoint on exploration, utilizing prior experience to learn effective latent representations, which can subsequently indicate which regions to explore. Prior experience on separate but related tasks help learn representations of the state which are effective at predicting instantaneous rewards. These learned representations can then be used with an entropy-based exploration method to effectively perform exploration in high dimensional spaces by effectively lowering the dimensionality of the search space. We show the benefits of this representation for meta-exploration in a simulated object pushing environment.
* 7 pages, 8 figures, workshop
MCP: Learning Composable Hierarchical Control with Multiplicative Compositional Policies
May 23, 2019

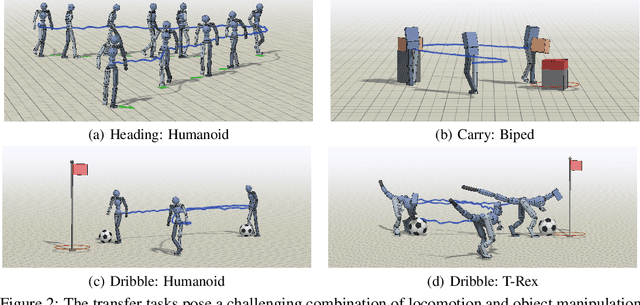
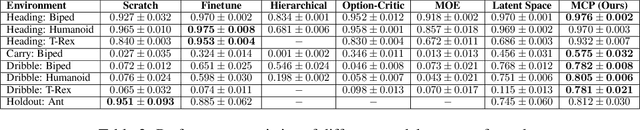
Humans are able to perform a myriad of sophisticated tasks by drawing upon skills acquired through prior experience. For autonomous agents to have this capability, they must be able to extract reusable skills from past experience that can be recombined in new ways for subsequent tasks. Furthermore, when controlling complex high-dimensional morphologies, such as humanoid bodies, tasks often require coordination of multiple skills simultaneously. Learning discrete primitives for every combination of skills quickly becomes prohibitive. Composable primitives that can be recombined to create a large variety of behaviors can be more suitable for modeling this combinatorial explosion. In this work, we propose multiplicative compositional policies (MCP), a method for learning reusable motor skills that can be composed to produce a range of complex behaviors. Our method factorizes an agent's skills into a collection of primitives, where multiple primitives can be activated simultaneously via multiplicative composition. This flexibility allows the primitives to be transferred and recombined to elicit new behaviors as necessary for novel tasks. We demonstrate that MCP is able to extract composable skills for highly complex simulated characters from pre-training tasks, such as motion imitation, and then reuse these skills to solve challenging continuous control tasks, such as dribbling a soccer ball to a goal, and picking up an object and transporting it to a target location.
Compression with Flows via Local Bits-Back Coding
May 22, 2019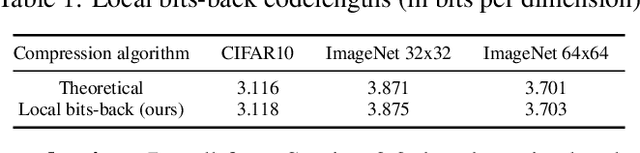
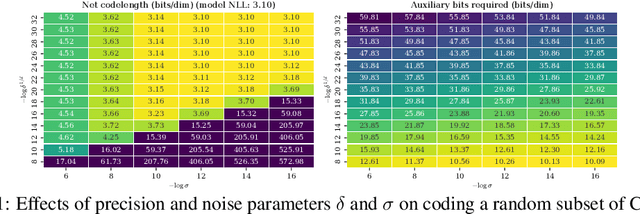
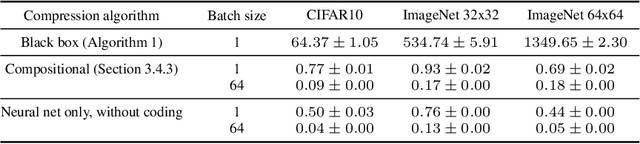
Likelihood-based generative models are the backbones of lossless compression, due to the guaranteed existence of codes with lengths close to negative log likelihood. However, there is no guaranteed existence of computationally efficient codes that achieve these lengths, and coding algorithms must be hand-tailored to specific types of generative models to ensure computational efficiency. Such coding algorithms are known for autoregressive models and variational autoencoders, but not for general types of flow models. To fill in this gap, we introduce local bits-back coding, a new compression technique compatible with flow models. We present efficient algorithms that instantiate our technique for many popular types of flows, and we demonstrate that our algorithms closely achieve theoretical codelengths for state-of-the-art flow models on high-dimensional data.
Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules
May 14, 2019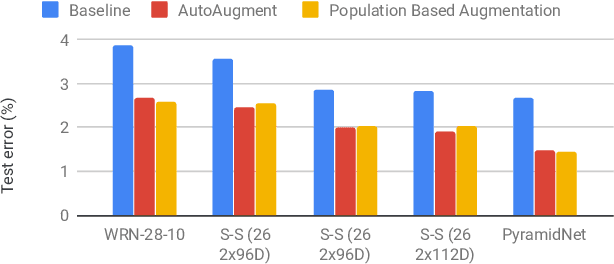
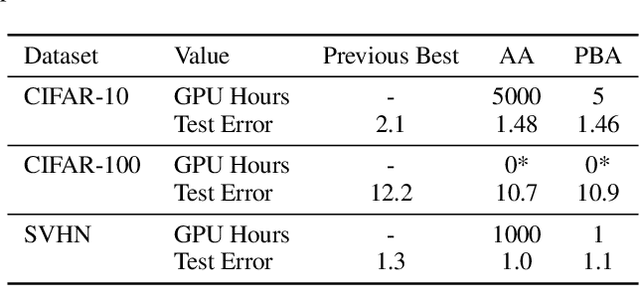
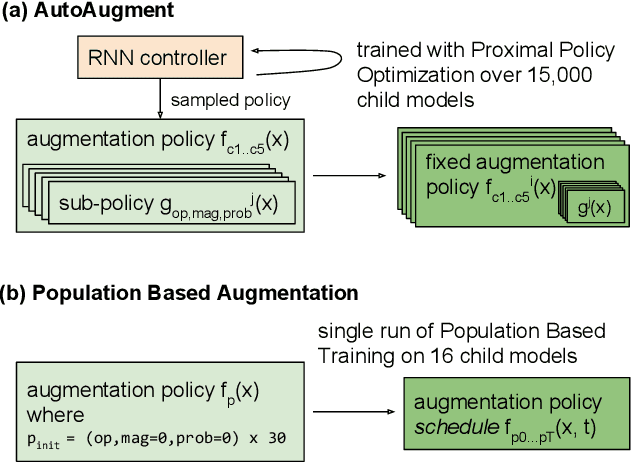
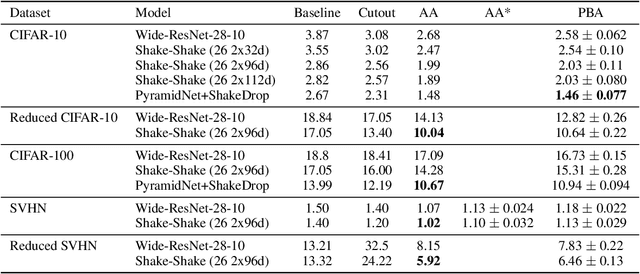
A key challenge in leveraging data augmentation for neural network training is choosing an effective augmentation policy from a large search space of candidate operations. Properly chosen augmentation policies can lead to significant generalization improvements; however, state-of-the-art approaches such as AutoAugment are computationally infeasible to run for the ordinary user. In this paper, we introduce a new data augmentation algorithm, Population Based Augmentation (PBA), which generates nonstationary augmentation policy schedules instead of a fixed augmentation policy. We show that PBA can match the performance of AutoAugment on CIFAR-10, CIFAR-100, and SVHN, with three orders of magnitude less overall compute. On CIFAR-10 we achieve a mean test error of 1.46%, which is a slight improvement upon the current state-of-the-art. The code for PBA is open source and is available at https://github.com/arcelien/pba.