 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Missing Evaluation Axis: What 10,000 Student Submissions Reveal About AI Tutor Effectiveness
May 07, 2026Current Artificial Intelligence (AI)-based tutoring systems (AI tutors) are primarily evaluated based on the pedagogical quality of their feedback messages. While important, pedagogy alone is insufficient because it ignores a critical question: what do students actually do with the feedback they receive? We argue that AI tutor evaluation should be extended with a behavioral dimension grounded in student interaction data, which complements pedagogical assessment. We propose an evaluation framework and apply it to 10,235 code submissions with corresponding AI tutor feedback from an introductory undergraduate programming course to measure whether students act on tutor feedback and whether those actions are applied correctly. Using this framework to compare two deployed AI tutors across different semesters in a large-scale introductory computer science course reveals substantial differences in student engagement patterns that are not captured by pedagogy-only evaluation. Moreover, these engagement-based behavioral signals are more strongly associated with student perception of helpful feedback than pedagogical quality alone, providing a more complete and actionable picture of AI tutor performance.
Cross-lingual Human-Preference Alignment for Neural Machine Translation with Direct Quality Optimization
Sep 26, 2024



Reinforcement Learning from Human Feedback (RLHF) and derivative techniques like Direct Preference Optimization (DPO) are task-alignment algorithms used to repurpose general, foundational models for specific tasks. We show that applying task-alignment to neural machine translation (NMT) addresses an existing task--data mismatch in NMT, leading to improvements across all languages of a multilingual model, even when task-alignment is only applied to a subset of those languages. We do so by introducing Direct Quality Optimization (DQO), a variant of DPO leveraging a pre-trained translation quality estimation model as a proxy for human preferences, and verify the improvements with both automatic metrics and human evaluation.
Pensieve Discuss: Scalable Small-Group CS Tutoring System with AI
Jul 24, 2024



Small-group tutoring in Computer Science (CS) is effective, but presents the challenge of providing a dedicated tutor for each group and encouraging collaboration among group members at scale. We present Pensieve Discuss, a software platform that integrates synchronous editing for scaffolded programming problems with online human and AI tutors, designed to improve student collaboration and experience during group tutoring sessions. Our semester-long deployment to 800 students in a CS1 course demonstrated consistently high collaboration rates, positive feedback about the AI tutor's helpfulness and correctness, increased satisfaction with the group tutoring experience, and a substantial increase in question volume. The use of our system was preferred over an interface lacking AI tutors and synchronous editing capabilities. Our experiences suggest that small-group tutoring sessions are an important avenue for future research in educational AI.
A Knowledge-Component-Based Methodology for Evaluating AI Assistants
Jun 09, 2024



We evaluate an automatic hint generator for CS1 programming assignments powered by GPT-4, a large language model. This system provides natural language guidance about how students can improve their incorrect solutions to short programming exercises. A hint can be requested each time a student fails a test case. Our evaluation addresses three Research Questions: RQ1: Do the hints help students improve their code? RQ2: How effectively do the hints capture problems in student code? RQ3: Are the issues that students resolve the same as the issues addressed in the hints? To address these research questions quantitatively, we identified a set of fine-grained knowledge components and determined which ones apply to each exercise, incorrect solution, and generated hint. Comparing data from two large CS1 offerings, we found that access to the hints helps students to address problems with their code more quickly, that hints are able to consistently capture the most pressing errors in students' code, and that hints that address a few issues at once rather than a single bug are more likely to lead to direct student progress.
Putting the Con in Context: Identifying Deceptive Actors in the Game of Mafia
Jul 05, 2022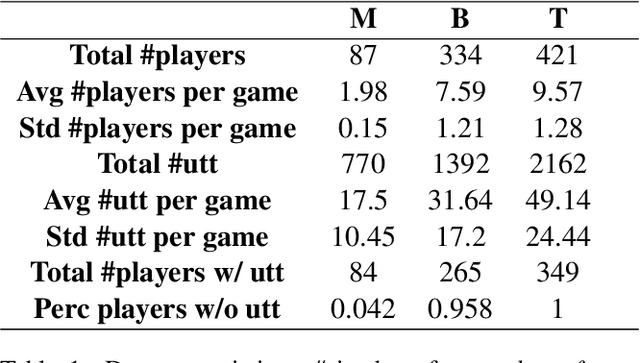
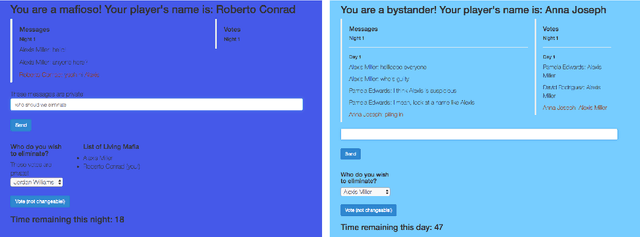


While neural networks demonstrate a remarkable ability to model linguistic content, capturing contextual information related to a speaker's conversational role is an open area of research. In this work, we analyze the effect of speaker role on language use through the game of Mafia, in which participants are assigned either an honest or a deceptive role. In addition to building a framework to collect a dataset of Mafia game records, we demonstrate that there are differences in the language produced by players with different roles. We confirm that classification models are able to rank deceptive players as more suspicious than honest ones based only on their use of language. Furthermore, we show that training models on two auxiliary tasks outperforms a standard BERT-based text classification approach. We also present methods for using our trained models to identify features that distinguish between player roles, which could be used to assist players during the Mafia game.
Automatic Correction of Human Translations
Jun 17, 2022
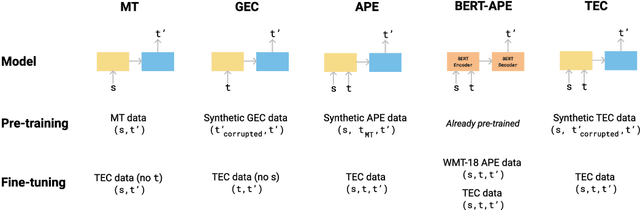
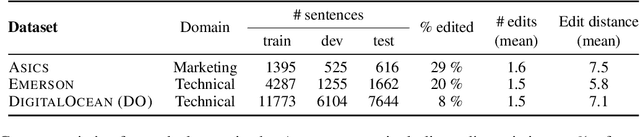

We introduce translation error correction (TEC), the task of automatically correcting human-generated translations. Imperfections in machine translations (MT) have long motivated systems for improving translations post-hoc with automatic post-editing. In contrast, little attention has been devoted to the problem of automatically correcting human translations, despite the intuition that humans make distinct errors that machines would be well-suited to assist with, from typos to inconsistencies in translation conventions. To investigate this, we build and release the Aced corpus with three TEC datasets. We show that human errors in TEC exhibit a more diverse range of errors and far fewer translation fluency errors than the MT errors in automatic post-editing datasets, suggesting the need for dedicated TEC models that are specialized to correct human errors. We show that pre-training instead on synthetic errors based on human errors improves TEC F-score by as much as 5.1 points. We conducted a human-in-the-loop user study with nine professional translation editors and found that the assistance of our TEC system led them to produce significantly higher quality revised translations.
Enriched Annotations for Tumor Attribute Classification from Pathology Reports with Limited Labeled Data
Dec 15, 2020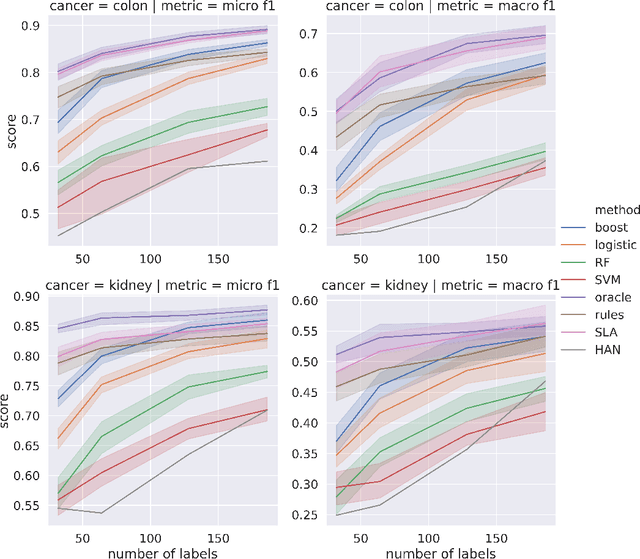
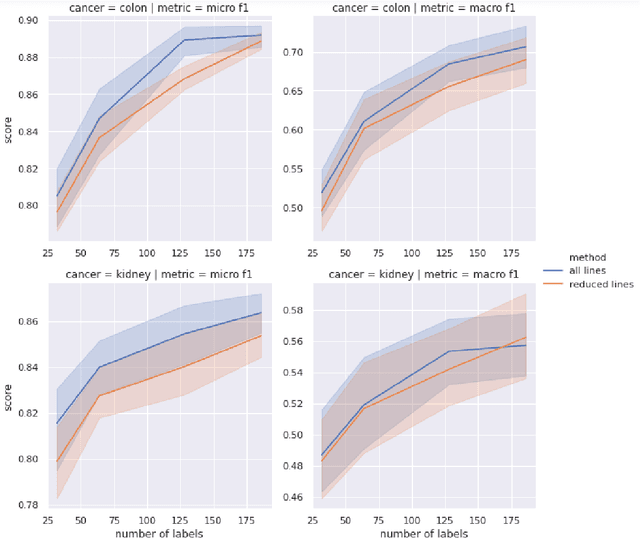
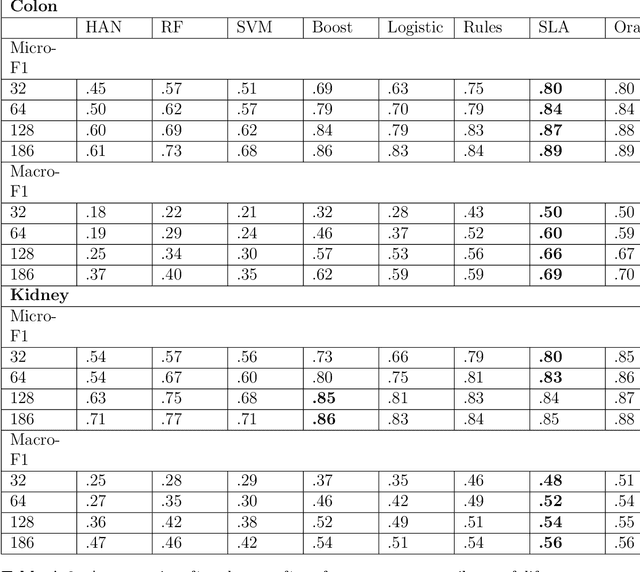
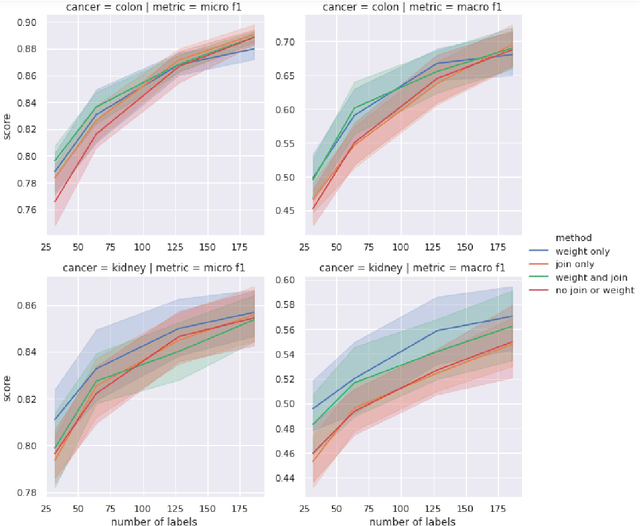
Precision medicine has the potential to revolutionize healthcare, but much of the data for patients is locked away in unstructured free-text, limiting research and delivery of effective personalized treatments. Generating large annotated datasets for information extraction from clinical notes is often challenging and expensive due to the high level of expertise needed for high quality annotations. To enable natural language processing for small dataset sizes, we develop a novel enriched hierarchical annotation scheme and algorithm, Supervised Line Attention (SLA), and apply this algorithm to predicting categorical tumor attributes from kidney and colon cancer pathology reports from the University of California San Francisco (UCSF). Whereas previous work only annotated document level labels, we in addition ask the annotators to enrich the traditional label by asking them to also highlight the relevant line or potentially lines for the final label, which leads to a 20% increase of annotation time required per document. With the enriched annotations, we develop a simple and interpretable machine learning algorithm that first predicts the relevant lines in the document and then predicts the tumor attribute. Our results show across the small dataset sizes of 32, 64, 128, and 186 labeled documents per cancer, SLA only requires half the number of labeled documents as state-of-the-art methods to achieve similar or better micro-f1 and macro-f1 scores for the vast majority of comparisons that we made. Accounting for the increased annotation time, this leads to a 40% reduction in total annotation time over the state of the art.
A Streaming Approach For Efficient Batched Beam Search
Oct 06, 2020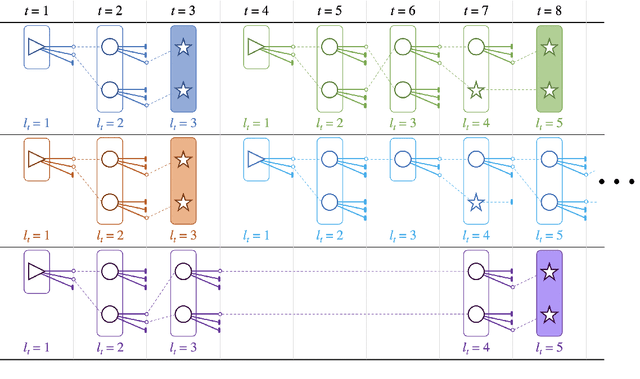
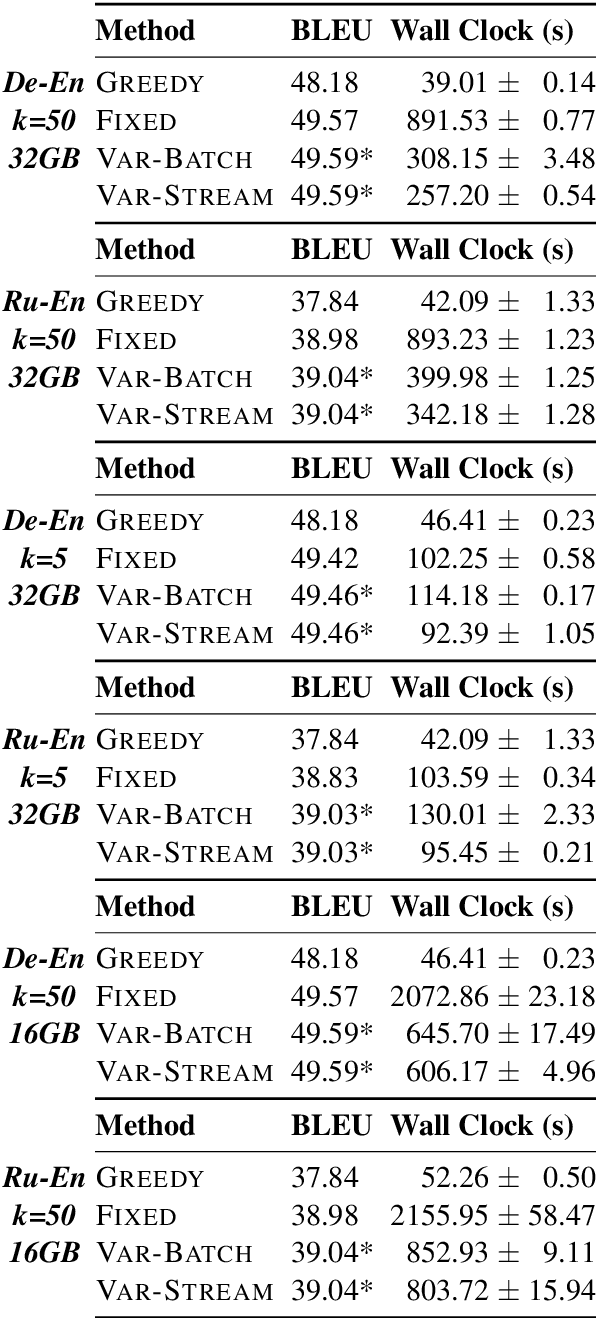
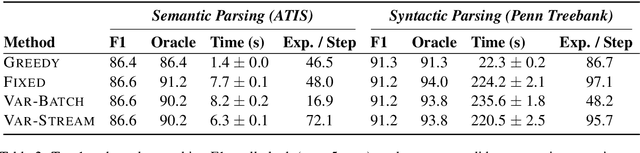
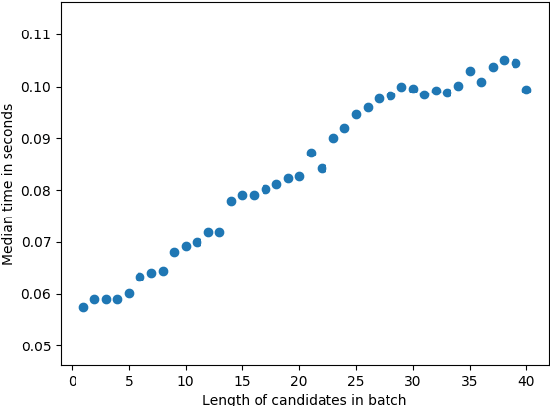
We propose an efficient batching strategy for variable-length decoding on GPU architectures. During decoding, when candidates terminate or are pruned according to heuristics, our streaming approach periodically "refills" the batch before proceeding with a selected subset of candidates. We apply our method to variable-width beam search on a state-of-the-art machine translation model. Our method decreases runtime by up to 71% compared to a fixed-width beam search baseline and 17% compared to a variable-width baseline, while matching baselines' BLEU. Finally, experiments show that our method can speed up decoding in other domains, such as semantic and syntactic parsing.
End-to-End Neural Word Alignment Outperforms GIZA++
Apr 30, 2020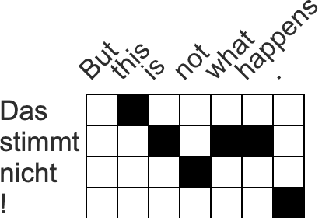

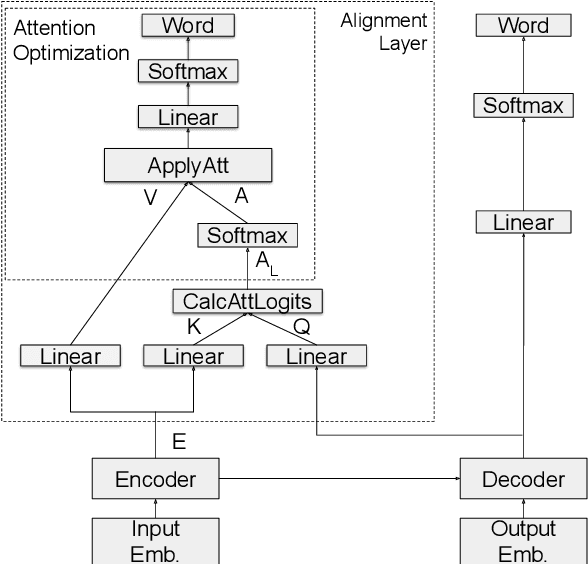
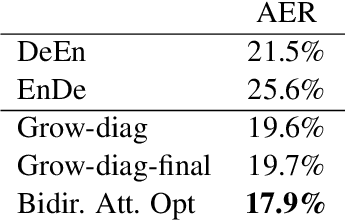
Word alignment was once a core unsupervised learning task in natural language processing because of its essential role in training statistical machine translation (MT) models. Although unnecessary for training neural MT models, word alignment still plays an important role in interactive applications of neural machine translation, such as annotation transfer and lexicon injection. While statistical MT methods have been replaced by neural approaches with superior performance, the twenty-year-old GIZA++ toolkit remains a key component of state-of-the-art word alignment systems. Prior work on neural word alignment has only been able to outperform GIZA++ by using its output during training. We present the first end-to-end neural word alignment method that consistently outperforms GIZA++ on three data sets. Our approach repurposes a Transformer model trained for supervised translation to also serve as an unsupervised word alignment model in a manner that is tightly integrated and does not affect translation quality.
Adding Interpretable Attention to Neural Translation Models Improves Word Alignment
Jan 31, 2019
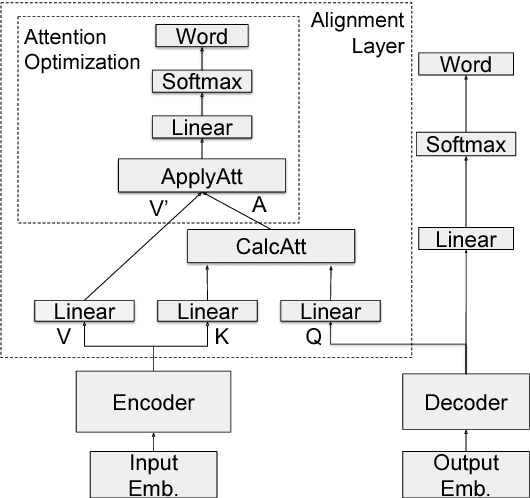

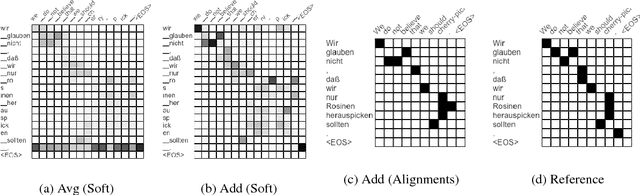
Multi-layer models with multiple attention heads per layer provide superior translation quality compared to simpler and shallower models, but determining what source context is most relevant to each target word is more challenging as a result. Therefore, deriving high-accuracy word alignments from the activations of a state-of-the-art neural machine translation model is an open challenge. We propose a simple model extension to the Transformer architecture that makes use of its hidden representations and is restricted to attend solely on encoder information to predict the next word. It can be trained on bilingual data without word-alignment information. We further introduce a novel alignment inference procedure which applies stochastic gradient descent to directly optimize the attention activations towards a given target word. The resulting alignments dramatically outperform the naive approach to interpreting Transformer attention activations, and are comparable to Giza++ on two publicly available data sets.