 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Network Social User Embedding with Hybrid Differential Privacy Guarantees
Sep 04, 2022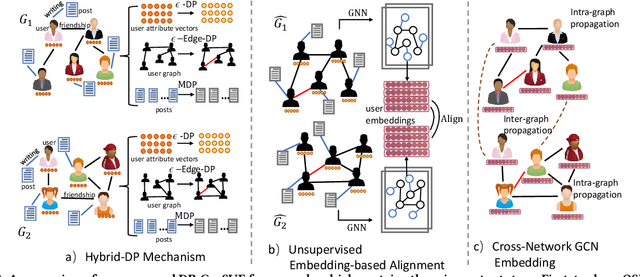

Integrating multiple online social networks (OSNs) has important implications for many downstream social mining tasks, such as user preference modelling, recommendation, and link prediction. However, it is unfortunately accompanied by growing privacy concerns about leaking sensitive user information. How to fully utilize the data from different online social networks while preserving user privacy remains largely unsolved. To this end, we propose a Cross-network Social User Embedding framework, namely DP-CroSUE, to learn the comprehensive representations of users in a privacy-preserving way. We jointly consider information from partially aligned social networks with differential privacy guarantees. In particular, for each heterogeneous social network, we first introduce a hybrid differential privacy notion to capture the variation of privacy expectations for heterogeneous data types. Next, to find user linkages across social networks, we make unsupervised user embedding-based alignment in which the user embeddings are achieved by the heterogeneous network embedding technology. To further enhance user embeddings, a novel cross-network GCN embedding model is designed to transfer knowledge across networks through those aligned users. Extensive experiments on three real-world datasets demonstrate that our approach makes a significant improvement on user interest prediction tasks as well as defending user attribute inference attacks from embedding.
A Self-supervised Riemannian GNN with Time Varying Curvature for Temporal Graph Learning
Aug 30, 2022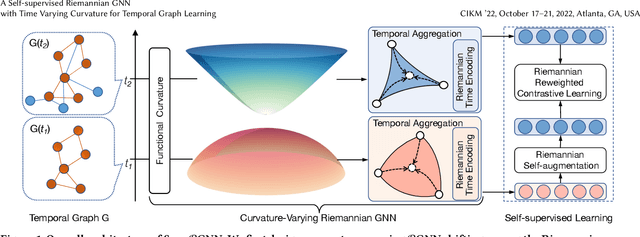

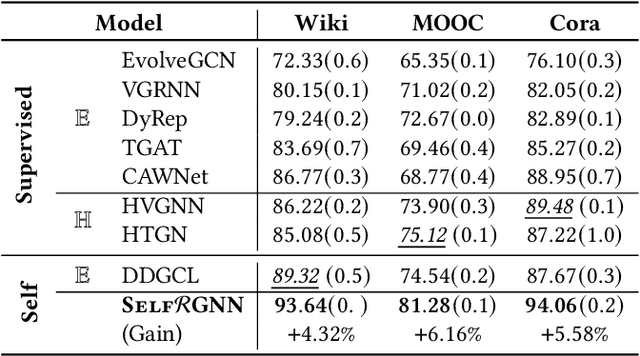
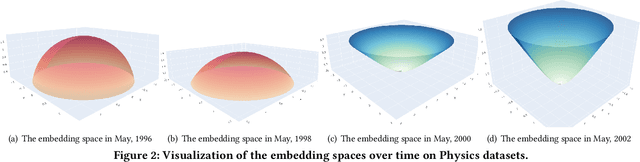
Representation learning on temporal graphs has drawn considerable research attention owing to its fundamental importance in a wide spectrum of real-world applications. Though a number of studies succeed in obtaining time-dependent representations, it still faces significant challenges. On the one hand, most of the existing methods restrict the embedding space with a certain curvature. However, the underlying geometry in fact shifts among the positive curvature hyperspherical, zero curvature Euclidean and negative curvature hyperbolic spaces in the evolvement over time. On the other hand, these methods usually require abundant labels to learn temporal representations, and thereby notably limit their wide use in the unlabeled graphs of the real applications. To bridge this gap, we make the first attempt to study the problem of self-supervised temporal graph representation learning in the general Riemannian space, supporting the time-varying curvature to shift among hyperspherical, Euclidean and hyperbolic spaces. In this paper, we present a novel self-supervised Riemannian graph neural network (SelfRGNN). Specifically, we design a curvature-varying Riemannian GNN with a theoretically grounded time encoding, and formulate a functional curvature over time to model the evolvement shifting among the positive, zero and negative curvature spaces. To enable the self-supervised learning, we propose a novel reweighting self-contrastive approach, exploring the Riemannian space itself without augmentation, and propose an edge-based self-supervised curvature learning with the Ricci curvature. Extensive experiments show the superiority of SelfRGNN, and moreover, the case study shows the time-varying curvature of temporal graph in reality.
A Generic Algorithm for Top-K On-Shelf Utility Mining
Aug 27, 2022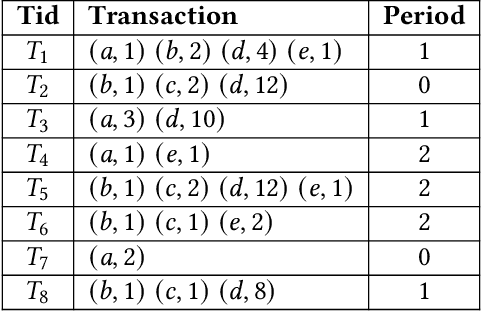
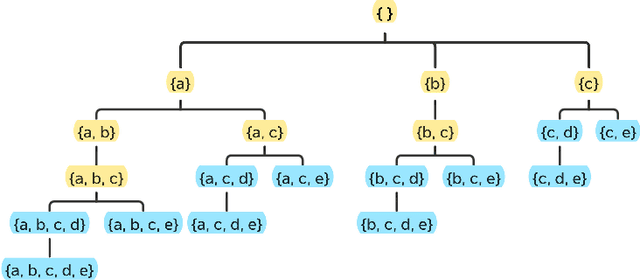

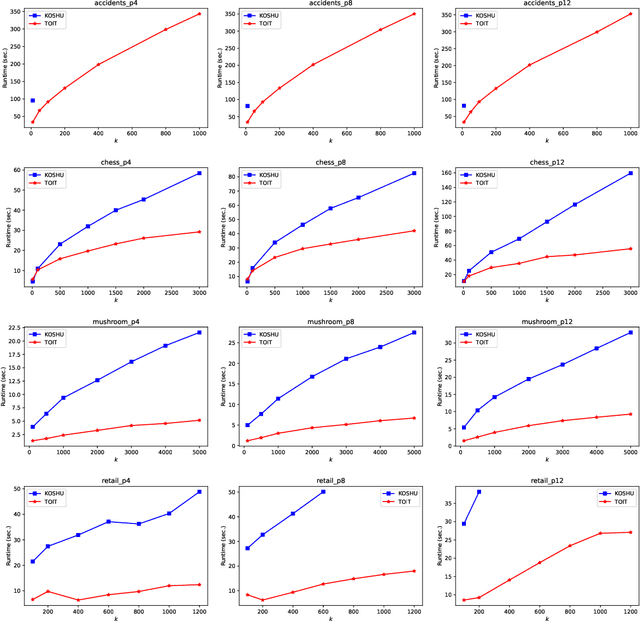
On-shelf utility mining (OSUM) is an emerging research direction in data mining. It aims to discover itemsets that have high relative utility in their selling time period. Compared with traditional utility mining, OSUM can find more practical and meaningful patterns in real-life applications. However, there is a major drawback to traditional OSUM. For normal users, it is hard to define a minimum threshold minutil for mining the right amount of on-shelf high utility itemsets. On one hand, if the threshold is set too high, the number of patterns would not be enough. On the other hand, if the threshold is set too low, too many patterns will be discovered and cause an unnecessary waste of time and memory consumption. To address this issue, the user usually directly specifies a parameter k, where only the top-k high relative utility itemsets would be considered. Therefore, in this paper, we propose a generic algorithm named TOIT for mining Top-k On-shelf hIgh-utility paTterns to solve this problem. TOIT applies a novel strategy to raise the minutil based on the on-shelf datasets. Besides, two novel upper-bound strategies named subtree utility and local utility are applied to prune the search space. By adopting the strategies mentioned above, the TOIT algorithm can narrow the search space as early as possible, improve the mining efficiency, and reduce the memory consumption, so it can obtain better performance than other algorithms. A series of experiments have been conducted on real datasets with different styles to compare the effects with the state-of-the-art KOSHU algorithm. The experimental results showed that TOIT outperforms KOSHU in both running time and memory consumption.
Position-aware Structure Learning for Graph Topology-imbalance by Relieving Under-reaching and Over-squashing
Aug 17, 2022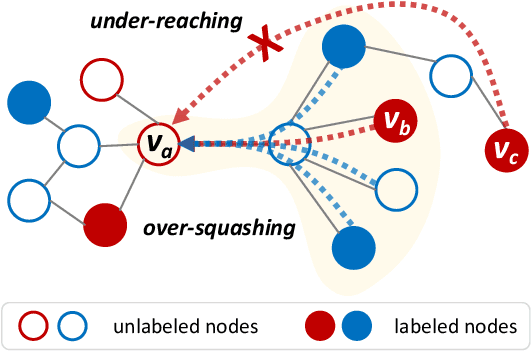
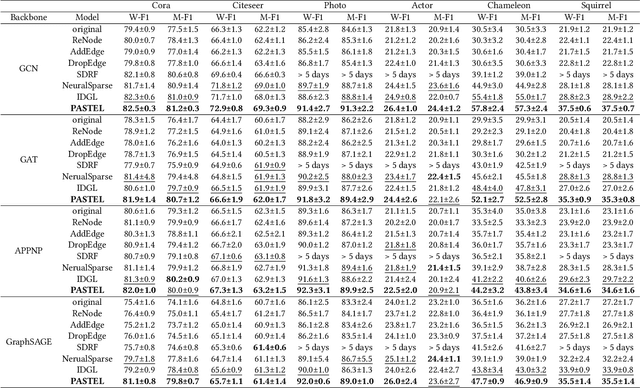
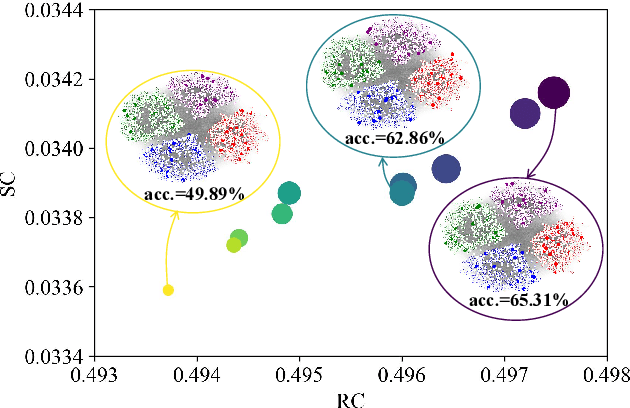
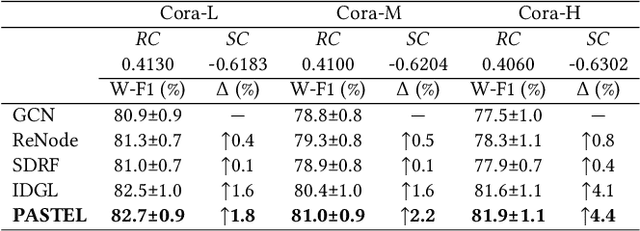
Topology-imbalance is a graph-specific imbalance problem caused by the uneven topology positions of labeled nodes, which significantly damages the performance of GNNs. What topology-imbalance means and how to measure its impact on graph learning remain under-explored. In this paper, we provide a new understanding of topology-imbalance from a global view of the supervision information distribution in terms of under-reaching and over-squashing, which motivates two quantitative metrics as measurements. In light of our analysis, we propose a novel position-aware graph structure learning framework named PASTEL, which directly optimizes the information propagation path and solves the topology-imbalance issue in essence. Our key insight is to enhance the connectivity of nodes within the same class for more supervision information, thereby relieving the under-reaching and over-squashing phenomena. Specifically, we design an anchor-based position encoding mechanism, which better incorporates relative topology position and enhances the intra-class inductive bias by maximizing the label influence. We further propose a class-wise conflict measure as the edge weights, which benefits the separation of different node classes. Extensive experiments demonstrate the superior potential and adaptability of PASTEL in enhancing GNNs' power in different data annotation scenarios.
Automating DBSCAN via Deep Reinforcement Learning
Aug 09, 2022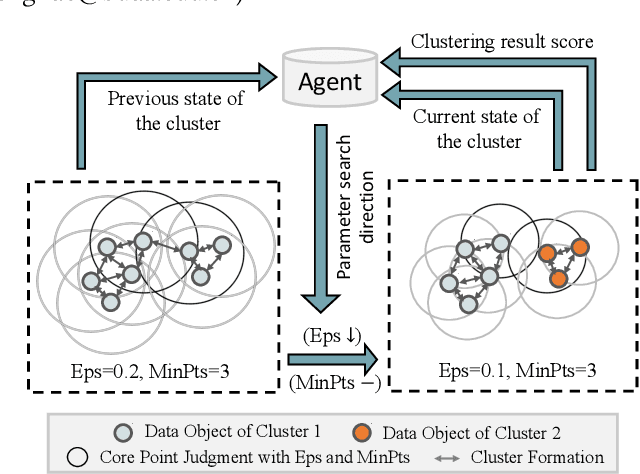
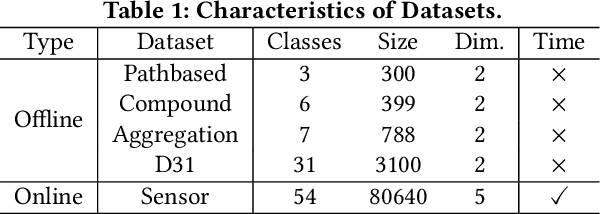
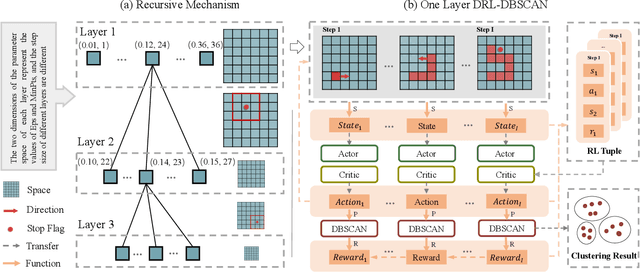
DBSCAN is widely used in many scientific and engineering fields because of its simplicity and practicality. However, due to its high sensitivity parameters, the accuracy of the clustering result depends heavily on practical experience. In this paper, we first propose a novel Deep Reinforcement Learning guided automatic DBSCAN parameters search framework, namely DRL-DBSCAN. The framework models the process of adjusting the parameter search direction by perceiving the clustering environment as a Markov decision process, which aims to find the best clustering parameters without manual assistance. DRL-DBSCAN learns the optimal clustering parameter search policy for different feature distributions via interacting with the clusters, using a weakly-supervised reward training policy network. In addition, we also present a recursive search mechanism driven by the scale of the data to efficiently and controllably process large parameter spaces. Extensive experiments are conducted on five artificial and real-world datasets based on the proposed four working modes. The results of offline and online tasks show that the DRL-DBSCAN not only consistently improves DBSCAN clustering accuracy by up to 26% and 25% respectively, but also can stably find the dominant parameters with high computational efficiency. The code is available at https://github.com/RingBDStack/DRL-DBSCAN.
Benchmarking Node Outlier Detection on Graphs
Jun 21, 2022
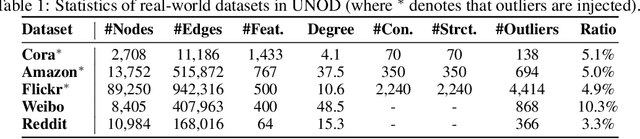

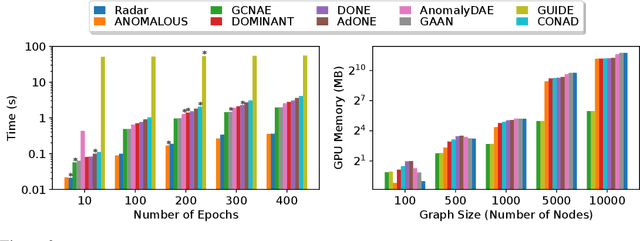
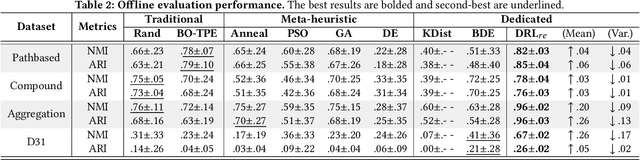
Graph outlier detection is an emerging but crucial machine learning task with numerous applications. Despite the proliferation of algorithms developed in recent years, the lack of a standard and unified setting for performance evaluation limits their advancement and usage in real-world applications. To tap the gap, we present, (to our best knowledge) the first comprehensive unsupervised node outlier detection benchmark for graphs called UNOD, with the following highlights: (1) evaluating fourteen methods with backbone spanning from classical matrix factorization to the latest graph neural networks; (2) benchmarking the method performance with different types of injected outliers and organic outliers on real-world datasets; (3) comparing the efficiency and scalability of the algorithms by runtime and GPU memory usage on synthetic graphs at different scales. Based on the analyses of extensive experimental results, we discuss the pros and cons of current UNOD methods, and point out multiple crucial and promising future research directions.
Collaborative Knowledge Graph Fusion by Exploiting the Open Corpus
Jun 15, 2022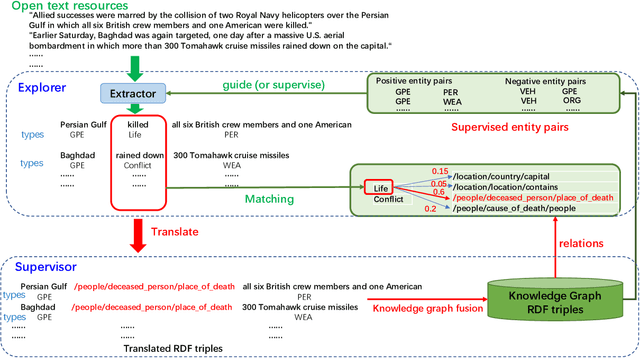
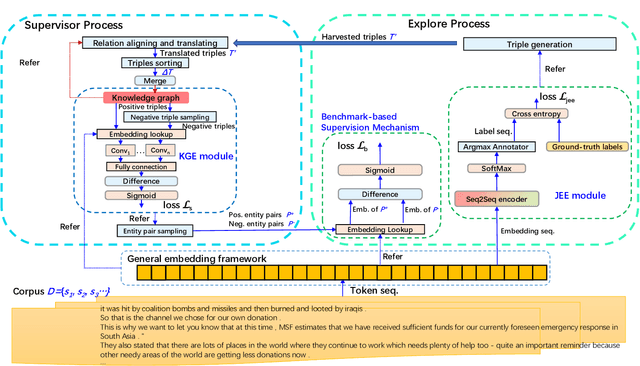
To alleviate the challenges of building Knowledge Graphs (KG) from scratch, a more general task is to enrich a KG using triples from an open corpus, where the obtained triples contain noisy entities and relations. It is challenging to enrich a KG with newly harvested triples while maintaining the quality of the knowledge representation. This paper proposes a system to refine a KG using information harvested from an additional corpus. To this end, we formulate our task as two coupled sub-tasks, namely join event extraction (JEE) and knowledge graph fusion (KGF). We then propose a Collaborative Knowledge Graph Fusion Framework to allow our sub-tasks to mutually assist one another in an alternating manner. More concretely, the explorer carries out the JEE supervised by both the ground-truth annotation and an existing KG provided by the supervisor. The supervisor then evaluates the triples extracted by the explorer and enriches the KG with those that are highly ranked. To implement this evaluation, we further propose a Translated Relation Alignment Scoring Mechanism to align and translate the extracted triples to the prior KG. Experiments verify that this collaboration can both improve the performance of the JEE and the KGF.
Towards Target Sequential Rules
Jun 09, 2022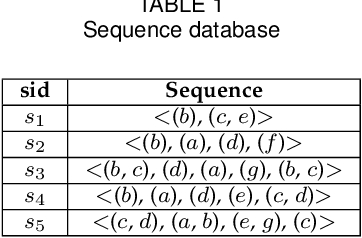
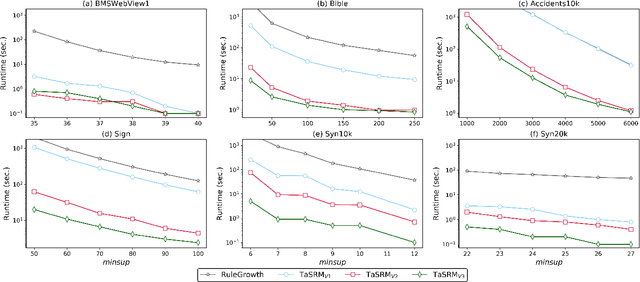
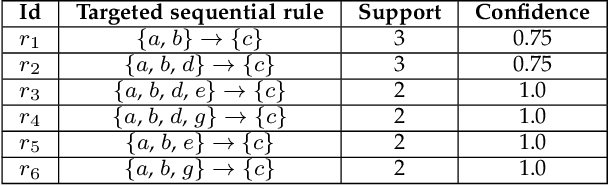
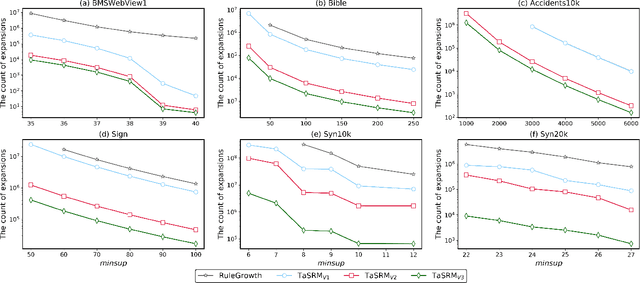
In many real-world applications, sequential rule mining (SRM) can provide prediction and recommendation functions for a variety of services. It is an important technique of pattern mining to discover all valuable rules that belong to high-frequency and high-confidence sequential rules. Although several algorithms of SRM are proposed to solve various practical problems, there are no studies on target sequential rules. Targeted sequential rule mining aims at mining the interesting sequential rules that users focus on, thus avoiding the generation of other invalid and unnecessary rules. This approach can further improve the efficiency of users in analyzing rules and reduce the consumption of data resources. In this paper, we provide the relevant definitions of target sequential rule and formulate the problem of targeted sequential rule mining. Furthermore, we propose an efficient algorithm, called targeted sequential rule mining (TaSRM). Several pruning strategies and an optimization are introduced to improve the efficiency of TaSRM. Finally, a large number of experiments are conducted on different benchmarks, and we analyze the results in terms of their running time, memory consumption, and scalability, as well as query cases with different query rules. It is shown that the novel algorithm TaSRM and its variants can achieve better experimental performance compared to the existing baseline algorithm.
Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination
Jun 03, 2022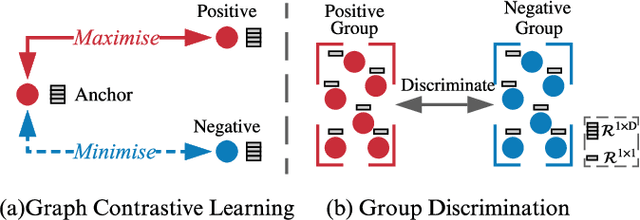
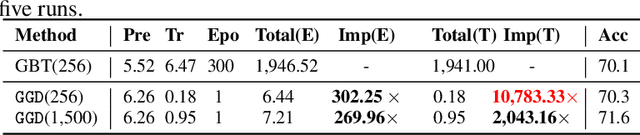
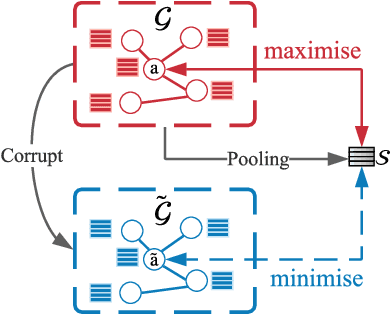
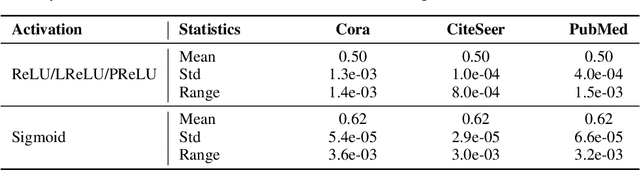
Graph contrastive learning (GCL) alleviates the heavy reliance on label information for graph representation learning (GRL) via self-supervised learning schemes. The core idea is to learn by maximising mutual information for similar instances, which requires similarity computation between two node instances. However, this operation can be computationally expensive. For example, the time complexity of two commonly adopted contrastive loss functions (i.e., InfoNCE and JSD estimator) for a node is $O(ND)$ and $O(D)$, respectively, where $N$ is the number of nodes, and $D$ is the embedding dimension. Additionally, GCL normally requires a large number of training epochs to be well-trained on large-scale datasets. Inspired by an observation of a technical defect (i.e., inappropriate usage of Sigmoid function) commonly used in two representative GCL works, DGI and MVGRL, we revisit GCL and introduce a new learning paradigm for self-supervised GRL, namely, Group Discrimination (GD), and propose a novel GD-based method called Graph Group Discrimination (GGD). Instead of similarity computation, GGD directly discriminates two groups of summarised node instances with a simple binary cross-entropy loss. As such, GGD only requires $O(1)$ for loss computation of a node. In addition, GGD requires much fewer training epochs to obtain competitive performance compared with GCL methods on large-scale datasets. These two advantages endow GGD with the very efficient property. Extensive experiments show that GGD outperforms state-of-the-art self-supervised methods on 8 datasets. In particular, GGD can be trained in 0.18 seconds (6.44 seconds including data preprocessing) on ogbn-arxiv, which is orders of magnitude (10,000+ faster than GCL baselines} while consuming much less memory. Trained with 9 hours on ogbn-papers100M with billion edges, GGD outperforms its GCL counterparts in both accuracy and efficiency.
A Multi-level Supervised Contrastive Learning Framework for Low-Resource Natural Language Inference
May 31, 2022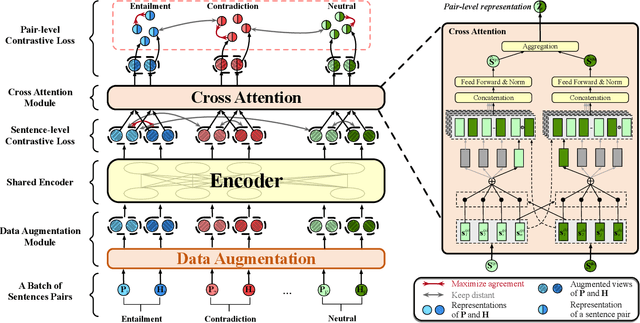
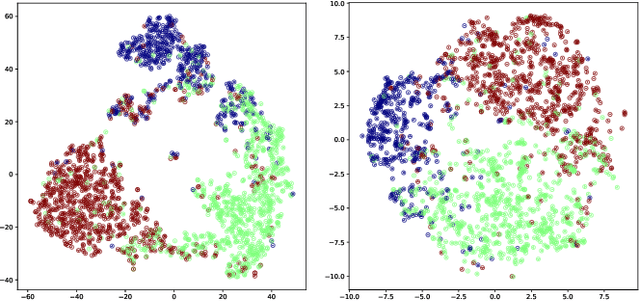
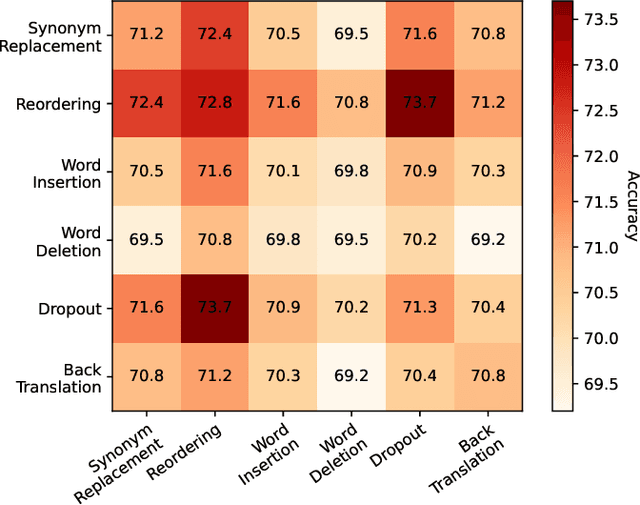
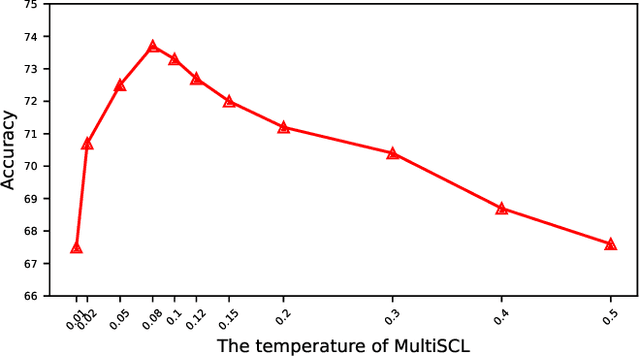
Natural Language Inference (NLI) is a growingly essential task in natural language understanding, which requires inferring the relationship between the sentence pairs (premise and hypothesis). Recently, low-resource natural language inference has gained increasing attention, due to significant savings in manual annotation costs and a better fit with real-world scenarios. Existing works fail to characterize discriminative representations between different classes with limited training data, which may cause faults in label prediction. Here we propose a multi-level supervised contrastive learning framework named MultiSCL for low-resource natural language inference. MultiSCL leverages a sentence-level and pair-level contrastive learning objective to discriminate between different classes of sentence pairs by bringing those in one class together and pushing away those in different classes. MultiSCL adopts a data augmentation module that generates different views for input samples to better learn the latent representation. The pair-level representation is obtained from a cross attention module. We conduct extensive experiments on two public NLI datasets in low-resource settings, and the accuracy of MultiSCL exceeds other models by 3.1% on average. Moreover, our method outperforms the previous state-of-the-art method on cross-domain tasks of text classification.