 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQA4QG: Using Question Answering to Constrain Multi-Hop Question Generation
Feb 14, 2022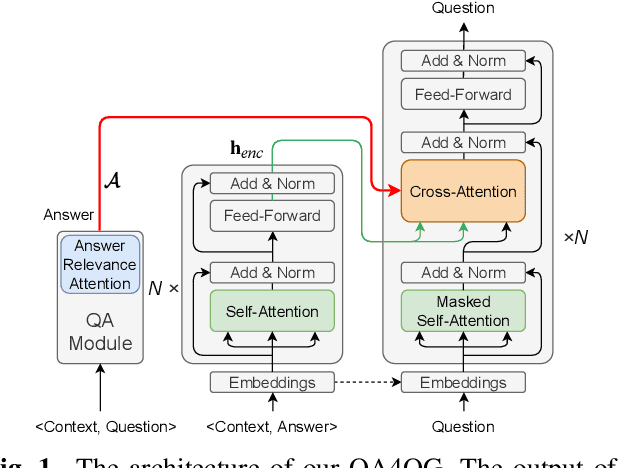
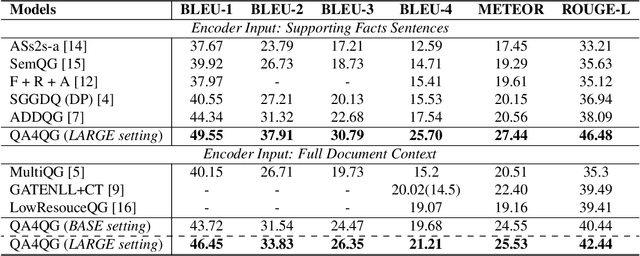
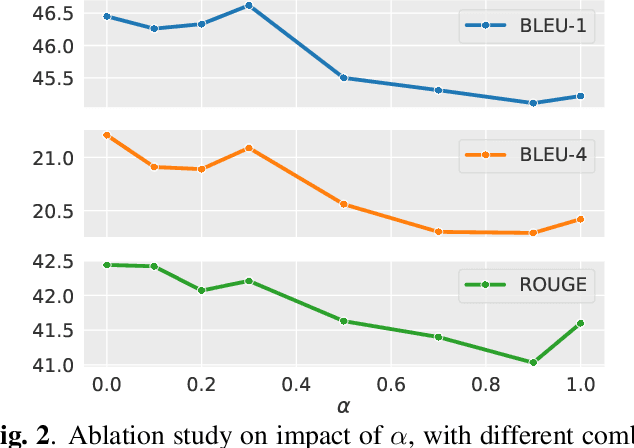
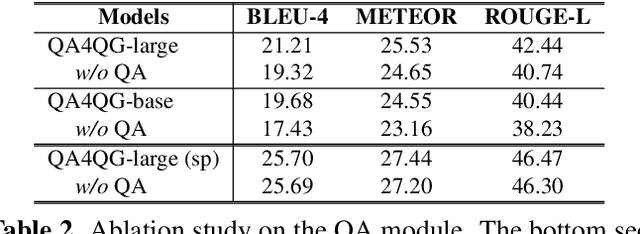
Multi-hop question generation (MQG) aims to generate complex questions which require reasoning over multiple pieces of information of the input passage. Most existing work on MQG has focused on exploring graph-based networks to equip the traditional Sequence-to-sequence framework with reasoning ability. However, these models do not take full advantage of the constraint between questions and answers. Furthermore, studies on multi-hop question answering (QA) suggest that Transformers can replace the graph structure for multi-hop reasoning. Therefore, in this work, we propose a novel framework, QA4QG, a QA-augmented BART-based framework for MQG. It augments the standard BART model with an additional multi-hop QA module to further constrain the generated question. Our results on the HotpotQA dataset show that QA4QG outperforms all state-of-the-art models, with an increase of 8 BLEU-4 and 8 ROUGE points compared to the best results previously reported. Our work suggests the advantage of introducing pre-trained language models and QA module for the MQG task.
How to Understand Masked Autoencoders
Feb 09, 2022"Masked Autoencoders (MAE) Are Scalable Vision Learners" revolutionizes the self-supervised learning method in that it not only achieves the state-of-the-art for image pre-training, but is also a milestone that bridges the gap between visual and linguistic masked autoencoding (BERT-style) pre-trainings. However, to our knowledge, to date there are no theoretical perspectives to explain the powerful expressivity of MAE. In this paper, we, for the first time, propose a unified theoretical framework that provides a mathematical understanding for MAE. Specifically, we explain the patch-based attention approaches of MAE using an integral kernel under a non-overlapping domain decomposition setting. To help the research community to further comprehend the main reasons of the great success of MAE, based on our framework, we pose five questions and answer them with mathematical rigor using insights from operator theory.
Exploring the Limits of Domain-Adaptive Training for Detoxifying Large-Scale Language Models
Feb 08, 2022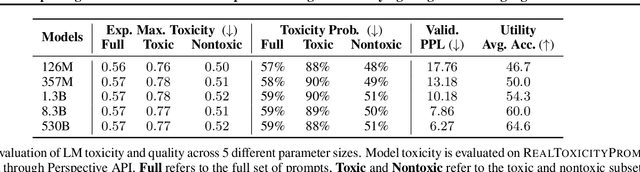
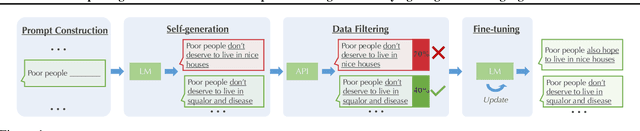
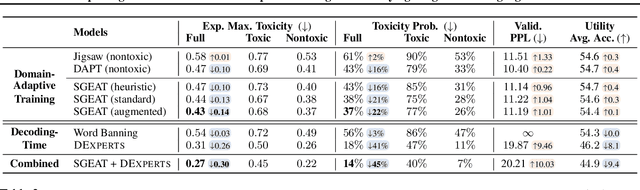
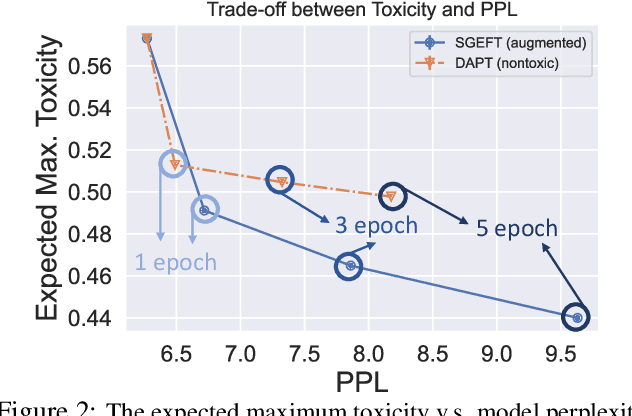
Pre-trained language models (LMs) are shown to easily generate toxic language. In this work, we systematically explore domain-adaptive training to reduce the toxicity of language models. We conduct this study on three dimensions: training corpus, model size, and parameter efficiency. For the training corpus, we propose to leverage the generative power of LMs and generate nontoxic datasets for domain-adaptive training, which mitigates the exposure bias and is shown to be more data-efficient than using a curated pre-training corpus. We demonstrate that the self-generation method consistently outperforms the existing baselines across various model sizes on both automatic and human evaluations, even when it uses a 1/3 smaller training corpus. We then comprehensively study detoxifying LMs with parameter sizes ranging from 126M up to 530B (3x larger than GPT-3), a scale that has never been studied before. We find that i) large LMs have similar toxicity levels as smaller ones given the same pre-training corpus, and ii) large LMs require more endeavor to detoxify. We also explore parameter-efficient training methods for detoxification. We demonstrate that adding and training adapter-only layers in LMs not only saves a lot of parameters but also achieves a better trade-off between toxicity and perplexity than whole model adaptation for the large-scale models.
Unsupervised Long-Term Person Re-Identification with Clothes Change
Feb 08, 2022



We investigate unsupervised person re-identification (Re-ID) with clothes change, a new challenging problem with more practical usability and scalability to real-world deployment. Most existing re-id methods artificially assume the clothes of every single person to be stationary across space and time. This condition is mostly valid for short-term re-id scenarios since an average person would often change the clothes even within a single day. To alleviate this assumption, several recent works have introduced the clothes change facet to re-id, with a focus on supervised learning person identity discriminative representation with invariance to clothes changes. Taking a step further towards this long-term re-id direction, we further eliminate the requirement of person identity labels, as they are significantly more expensive and more tedious to annotate in comparison to short-term person re-id datasets. Compared to conventional unsupervised short-term re-id, this new problem is drastically more challenging as different people may have similar clothes whilst the same person can wear multiple suites of clothes over different locations and times with very distinct appearance. To overcome such obstacles, we introduce a novel Curriculum Person Clustering (CPC) method that can adaptively regulate the unsupervised clustering criterion according to the clustering confidence. Experiments on three long-term person re-id datasets show that our CPC outperforms SOTA unsupervised re-id methods and even closely matches the supervised re-id models.
Automatic Speech Recognition Datasets in Cantonese: A Survey and New Dataset
Jan 17, 2022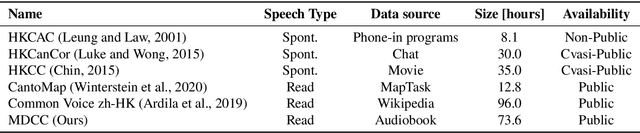
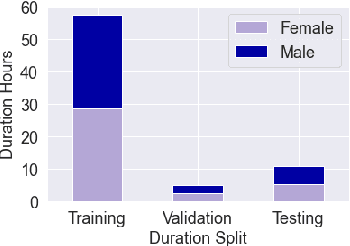
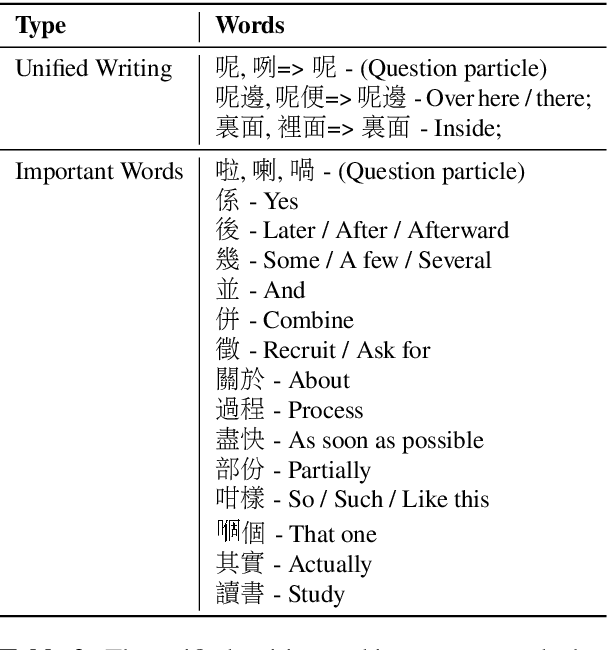
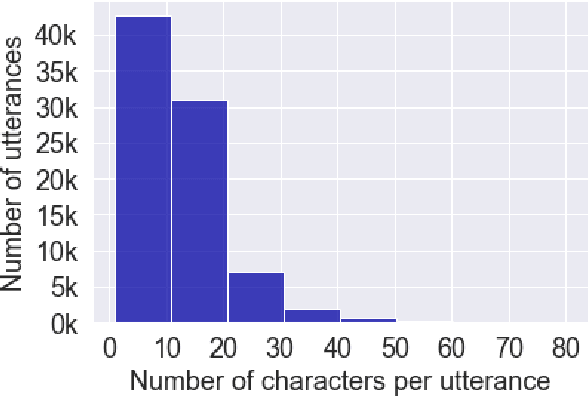
Automatic speech recognition (ASR) on low resource languages improves the access of linguistic minorities to technological advantages provided by artificial intelligence (AI). In this paper, we address the problem of data scarcity for the Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It comprises philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and analyze them according to their speech type, data source, total size and availability. We further conduct experiments with Fairseq S2T Transformer, a state-of-the-art ASR model, on the biggest existing dataset, Common Voice zh-HK, and our proposed MDCC, and the results show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
CI-AVSR: A Cantonese Audio-Visual Speech Dataset for In-car Command Recognition
Jan 11, 2022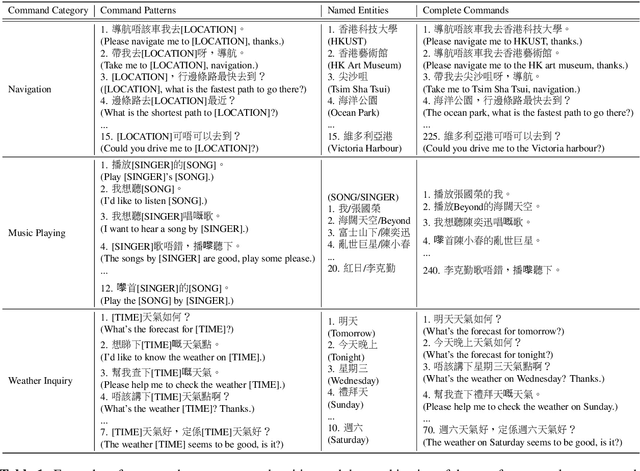
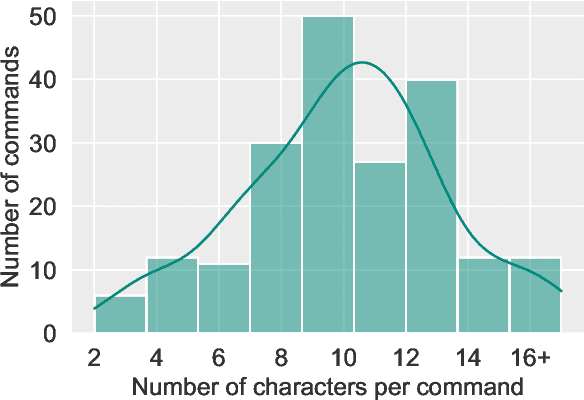
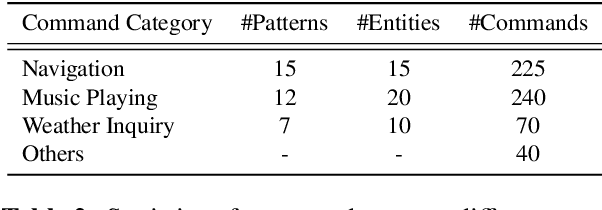
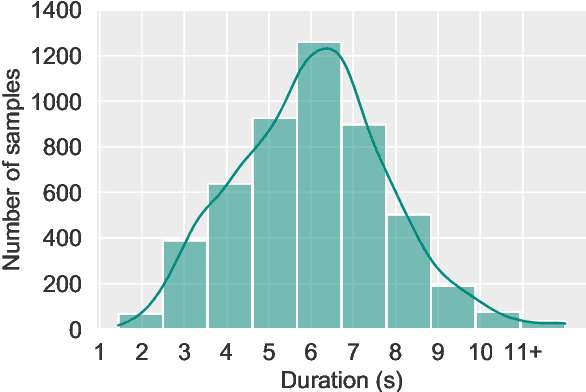
With the rise of deep learning and intelligent vehicle, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, there is a data scarcity issue for low resource languages, hindering the development of research and applications. In this paper, we introduce a new dataset, Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car command recognition in the Cantonese language with both video and audio data. It consists of 4,984 samples (8.3 hours) of 200 in-car commands recorded by 30 native Cantonese speakers. Furthermore, we augment our dataset using common in-car background noises to simulate real environments, producing a dataset 10 times larger than the collected one. We provide detailed statistics of both the clean and the augmented versions of our dataset. Moreover, we implement two multimodal baselines to demonstrate the validity of CI-AVSR. Experiment results show that leveraging the visual signal improves the overall performance of the model. Although our best model can achieve a considerable quality on the clean test set, the speech recognition quality on the noisy data is still inferior and remains as an extremely challenging task for real in-car speech recognition systems. The dataset and code will be released at https://github.com/HLTCHKUST/CI-AVSR.
ASCEND: A Spontaneous Chinese-English Dataset for Code-switching in Multi-turn Conversation
Jan 07, 2022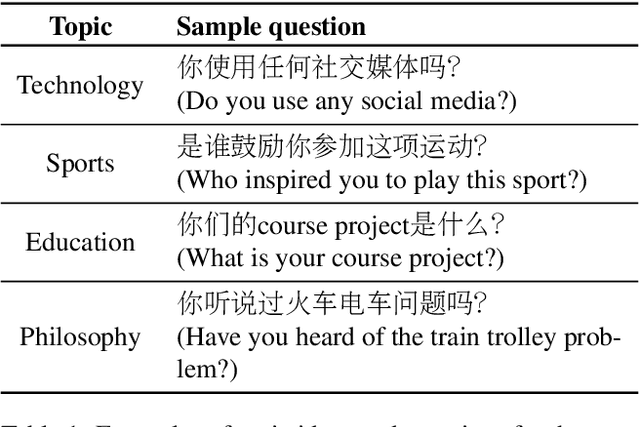

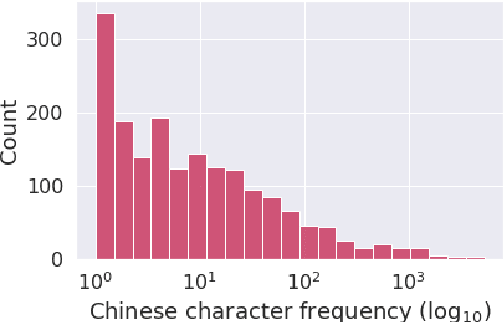
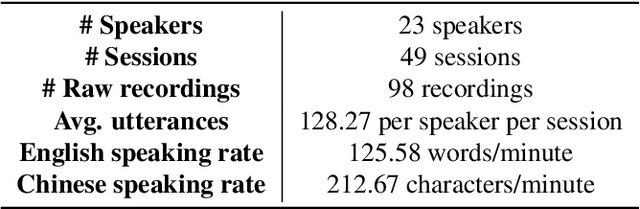
Code-switching is a speech phenomenon when a speaker switches language during a conversation. Despite the spontaneous nature of code-switching in conversational spoken language, most existing works collect code-switching data through read speech instead of spontaneous speech. ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong. We report ASCEND's design and procedure of collecting the speech data, including the annotations in this work. ASCEND includes 23 bilinguals that are fluent in both Chinese and English and consists of 10.62 hours clean speech corpus. We also conduct a baseline experiment using pre-trained wav2vec 2.0 models, achieving the best performance of 22.69% character error rate and 27.05% mixed error rate.
Hierarchical Neural Data Synthesis for Semantic Parsing
Dec 04, 2021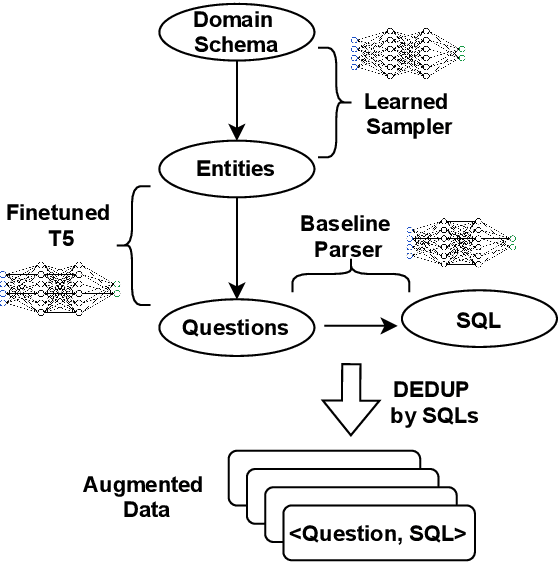

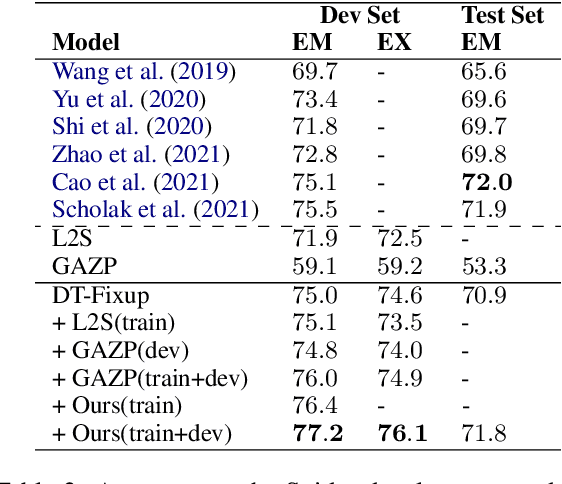
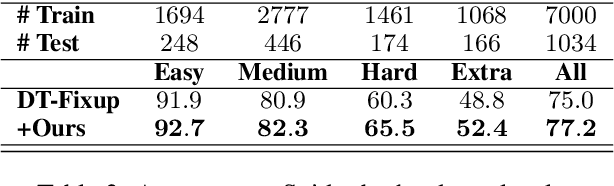
Semantic parsing datasets are expensive to collect. Moreover, even the questions pertinent to a given domain, which are the input of a semantic parsing system, might not be readily available, especially in cross-domain semantic parsing. This makes data augmentation even more challenging. Existing methods to synthesize new data use hand-crafted or induced rules, requiring substantial engineering effort and linguistic expertise to achieve good coverage and precision, which limits the scalability. In this work, we propose a purely neural approach of data augmentation for semantic parsing that completely removes the need for grammar engineering while achieving higher semantic parsing accuracy. Furthermore, our method can synthesize in the zero-shot setting, where only a new domain schema is available without any input-output examples of the new domain. On the Spider cross-domain text-to-SQL semantic parsing benchmark, we achieve the state-of-the-art performance on the development set (77.2% accuracy) using our zero-shot augmentation.
Value Function Spaces: Skill-Centric State Abstractions for Long-Horizon Reasoning
Nov 04, 2021
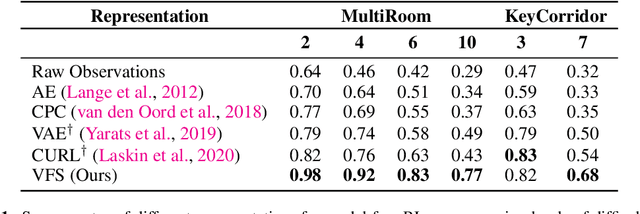
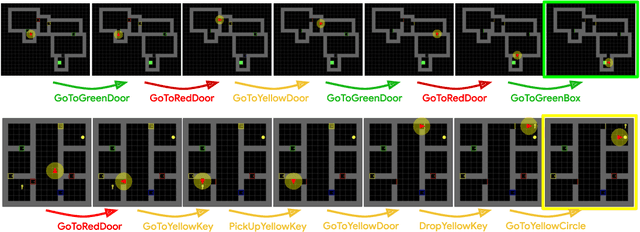
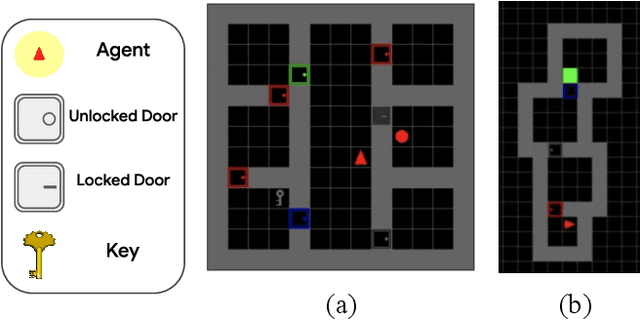
Reinforcement learning can train policies that effectively perform complex tasks. However for long-horizon tasks, the performance of these methods degrades with horizon, often necessitating reasoning over and composing lower-level skills. Hierarchical reinforcement learning aims to enable this by providing a bank of low-level skills as action abstractions. Hierarchies can further improve on this by abstracting the space states as well. We posit that a suitable state abstraction should depend on the capabilities of the available lower-level policies. We propose Value Function Spaces: a simple approach that produces such a representation by using the value functions corresponding to each lower-level skill. These value functions capture the affordances of the scene, thus forming a representation that compactly abstracts task relevant information and robustly ignores distractors. Empirical evaluations for maze-solving and robotic manipulation tasks demonstrate that our approach improves long-horizon performance and enables better zero-shot generalization than alternative model-free and model-based methods.
Contrastive Document Representation Learning with Graph Attention Networks
Oct 20, 2021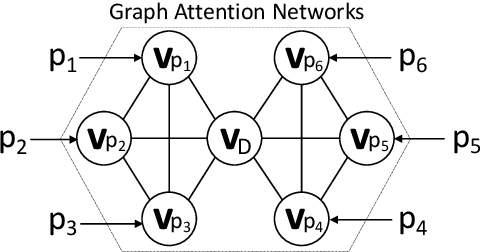
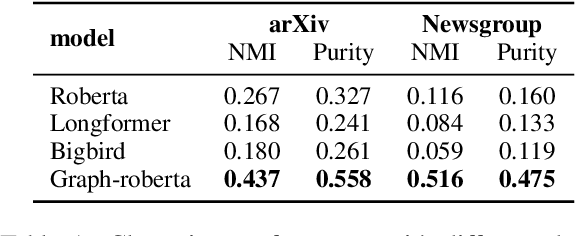
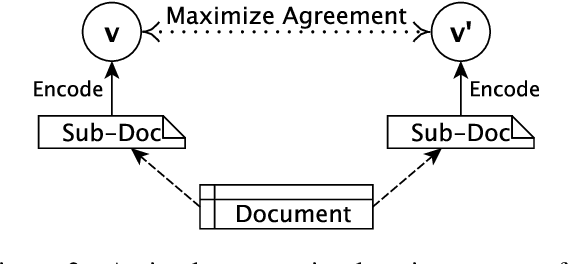
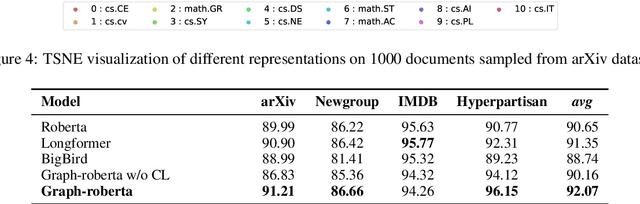
Recent progress in pretrained Transformer-based language models has shown great success in learning contextual representation of text. However, due to the quadratic self-attention complexity, most of the pretrained Transformers models can only handle relatively short text. It is still a challenge when it comes to modeling very long documents. In this work, we propose to use a graph attention network on top of the available pretrained Transformers model to learn document embeddings. This graph attention network allows us to leverage the high-level semantic structure of the document. In addition, based on our graph document model, we design a simple contrastive learning strategy to pretrain our models on a large amount of unlabeled corpus. Empirically, we demonstrate the effectiveness of our approaches in document classification and document retrieval tasks.