 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Rating: A Comprehensive Evaluation and Benchmark for AI Reviews
Apr 22, 2026The rapid adoption of Large Language Models (LLMs) has spurred interest in automated peer review; however, progress is currently stifled by benchmarks that treat reviewing primarily as a rating prediction task. We argue that the utility of a review lies in its textual justification--its arguments, questions, and critique--rather than a scalar score. To address this, we introduce Beyond Rating, a holistic evaluation framework that assesses AI reviewers across five dimensions: Content Faithfulness, Argumentative Alignment, Focus Consistency, Question Constructiveness, and AI-Likelihood. Notably, we propose a Max-Recall strategy to accommodate valid expert disagreement and introduce a curated dataset of paper with high-confidence reviews, rigorously filtered to remove procedural noise. Extensive experiments demonstrate that while traditional n-gram metrics fail to reflect human preferences, our proposed text-centric metrics--particularly the recall of weakness arguments--correlate strongly with rating accuracy. These findings establish that aligning AI critique focus with human experts is a prerequisite for reliable automated scoring, offering a robust standard for future research.
AI Can Learn Scientific Taste
Mar 15, 2026Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
AgentLongBench: A Controllable Long Benchmark For Long-Contexts Agents via Environment Rollouts
Jan 29, 2026The evolution of Large Language Models (LLMs) into autonomous agents necessitates the management of extensive, dynamic contexts. Current benchmarks, however, remain largely static, relying on passive retrieval tasks that fail to simulate the complexities of agent-environment interaction, such as non-linear reasoning and iterative feedback. To address this, we introduce \textbf{AgentLongBench}, which evaluates agents through simulated environment rollouts based on Lateral Thinking Puzzles. This framework generates rigorous interaction trajectories across knowledge-intensive and knowledge-free scenarios. Experiments with state-of-the-art models and memory systems (32K to 4M tokens) expose a critical weakness: while adept at static retrieval, agents struggle with the dynamic information synthesis essential for workflows. Our analysis indicates that this degradation is driven by the minimum number of tokens required to resolve a query. This factor explains why the high information density inherent in massive tool responses poses a significantly greater challenge than the memory fragmentation typical of long-turn dialogues.
AstroReason-Bench: Evaluating Unified Agentic Planning across Heterogeneous Space Planning Problems
Jan 16, 2026Recent advances in agentic Large Language Models (LLMs) have positioned them as generalist planners capable of reasoning and acting across diverse tasks. However, existing agent benchmarks largely focus on symbolic or weakly grounded environments, leaving their performance in physics-constrained real-world domains underexplored. We introduce AstroReason-Bench, a comprehensive benchmark for evaluating agentic planning in Space Planning Problems (SPP), a family of high-stakes problems with heterogeneous objectives, strict physical constraints, and long-horizon decision-making. AstroReason-Bench integrates multiple scheduling regimes, including ground station communication and agile Earth observation, and provides a unified agent-oriented interaction protocol. Evaluating on a range of state-of-the-art open- and closed-source agentic LLM systems, we find that current agents substantially underperform specialized solvers, highlighting key limitations of generalist planning under realistic constraints. AstroReason-Bench offers a challenging and diagnostic testbed for future agentic research.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025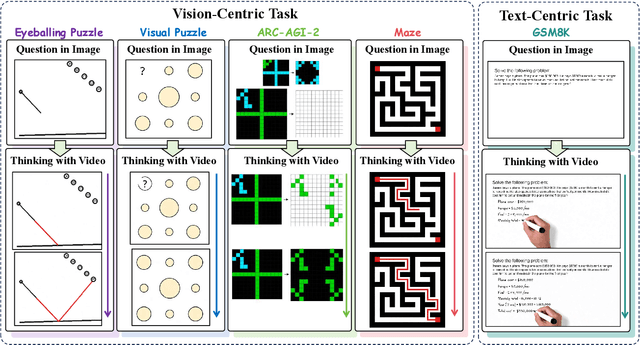
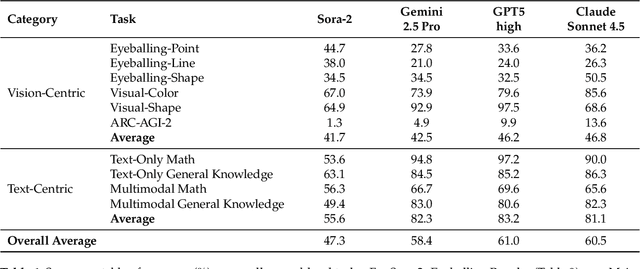
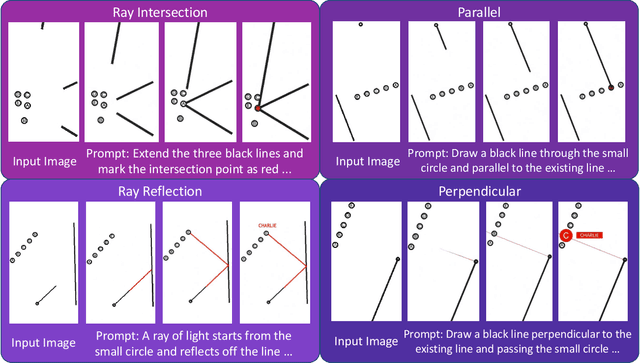

"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
MARAG-R1: Beyond Single Retriever via Reinforcement-Learned Multi-Tool Agentic Retrieval
Oct 31, 2025



Large Language Models (LLMs) excel at reasoning and generation but are inherently limited by static pretraining data, resulting in factual inaccuracies and weak adaptability to new information. Retrieval-Augmented Generation (RAG) addresses this issue by grounding LLMs in external knowledge; However, the effectiveness of RAG critically depends on whether the model can adequately access relevant information. Existing RAG systems rely on a single retriever with fixed top-k selection, restricting access to a narrow and static subset of the corpus. As a result, this single-retriever paradigm has become the primary bottleneck for comprehensive external information acquisition, especially in tasks requiring corpus-level reasoning. To overcome this limitation, we propose MARAG-R1, a reinforcement-learned multi-tool RAG framework that enables LLMs to dynamically coordinate multiple retrieval mechanisms for broader and more precise information access. MARAG-R1 equips the model with four retrieval tools -- semantic search, keyword search, filtering, and aggregation -- and learns both how and when to use them through a two-stage training process: supervised fine-tuning followed by reinforcement learning. This design allows the model to interleave reasoning and retrieval, progressively gathering sufficient evidence for corpus-level synthesis. Experiments on GlobalQA, HotpotQA, and 2WikiMultiHopQA demonstrate that MARAG-R1 substantially outperforms strong baselines and achieves new state-of-the-art results in corpus-level reasoning tasks.
Towards Global Retrieval Augmented Generation: A Benchmark for Corpus-Level Reasoning
Oct 30, 2025



Retrieval-augmented generation (RAG) has emerged as a leading approach to reducing hallucinations in large language models (LLMs). Current RAG evaluation benchmarks primarily focus on what we call local RAG: retrieving relevant chunks from a small subset of documents to answer queries that require only localized understanding within specific text chunks. However, many real-world applications require a fundamentally different capability -- global RAG -- which involves aggregating and analyzing information across entire document collections to derive corpus-level insights (for example, "What are the top 10 most cited papers in 2023?"). In this paper, we introduce GlobalQA -- the first benchmark specifically designed to evaluate global RAG capabilities, covering four core task types: counting, extremum queries, sorting, and top-k extraction. Through systematic evaluation across different models and baselines, we find that existing RAG methods perform poorly on global tasks, with the strongest baseline achieving only 1.51 F1 score. To address these challenges, we propose GlobalRAG, a multi-tool collaborative framework that preserves structural coherence through chunk-level retrieval, incorporates LLM-driven intelligent filters to eliminate noisy documents, and integrates aggregation modules for precise symbolic computation. On the Qwen2.5-14B model, GlobalRAG achieves 6.63 F1 compared to the strongest baseline's 1.51 F1, validating the effectiveness of our method.
Improving Cross-task Generalization of Unified Table-to-text Models with Compositional Task Configurations
Dec 17, 2022



There has been great progress in unifying various table-to-text tasks using a single encoder-decoder model trained via multi-task learning (Xie et al., 2022). However, existing methods typically encode task information with a simple dataset name as a prefix to the encoder. This not only limits the effectiveness of multi-task learning, but also hinders the model's ability to generalize to new domains or tasks that were not seen during training, which is crucial for real-world applications. In this paper, we propose compositional task configurations, a set of prompts prepended to the encoder to improve cross-task generalization of unified models. We design the task configurations to explicitly specify the task type, as well as its input and output types. We show that this not only allows the model to better learn shared knowledge across different tasks at training, but also allows us to control the model by composing new configurations that apply novel input-output combinations in a zero-shot manner. We demonstrate via experiments over ten table-to-text tasks that our method outperforms the UnifiedSKG baseline by noticeable margins in both in-domain and zero-shot settings, with average improvements of +0.5 and +12.6 from using a T5-large backbone, respectively.
Language Agnostic Multilingual Information Retrieval with Contrastive Learning
Oct 12, 2022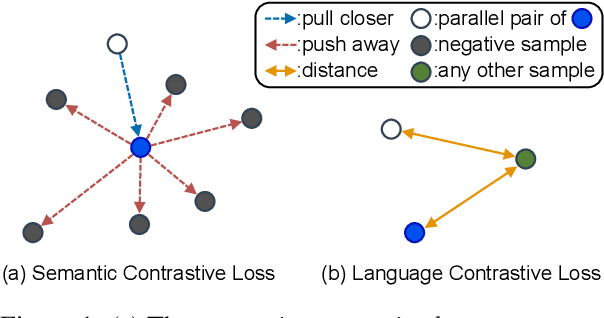
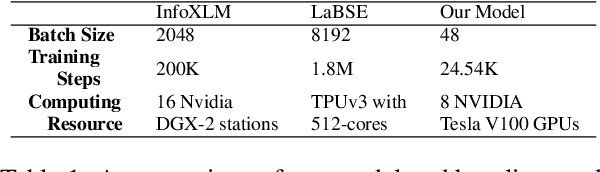
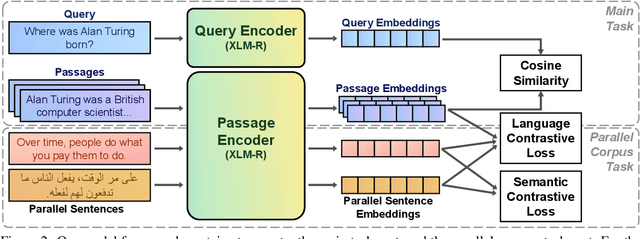
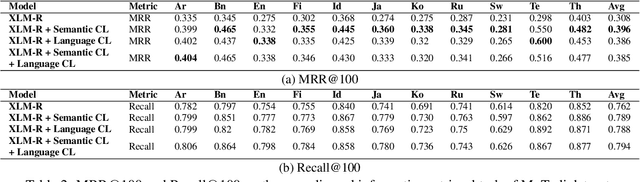
Multilingual information retrieval is challenging due to the lack of training datasets for many low-resource languages. We present an effective method by leveraging parallel and non-parallel corpora to improve the pretrained multilingual language models' cross-lingual transfer ability for information retrieval. We design the semantic contrastive loss as regular contrastive learning to improve the cross-lingual alignment of parallel sentence pairs, and we propose a new contrastive loss, the language contrastive loss, to leverage both parallel corpora and non-parallel corpora to further improve multilingual representation learning. We train our model on an English information retrieval dataset, and test its zero-shot transfer ability to other languages. Our experiment results show that our method brings significant improvement to prior work on retrieval performance, while it requires much less computational effort. Our model can work well even with a small number of parallel corpora. And it can be used as an add-on module to any backbone and other tasks. Our code is available at: https://github.com/xiyanghu/multilingualIR.
Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner
May 18, 2022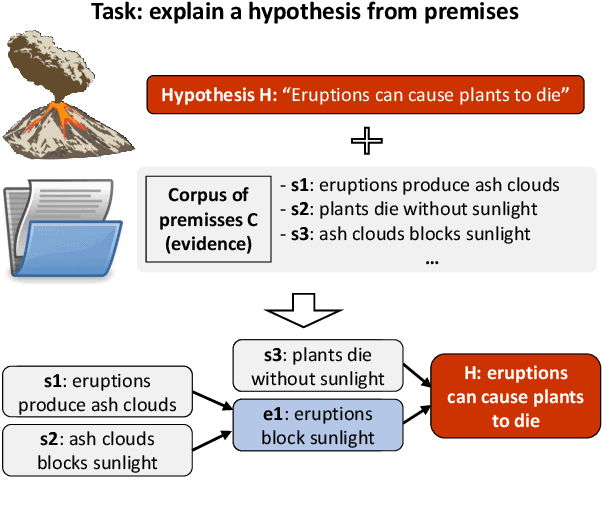
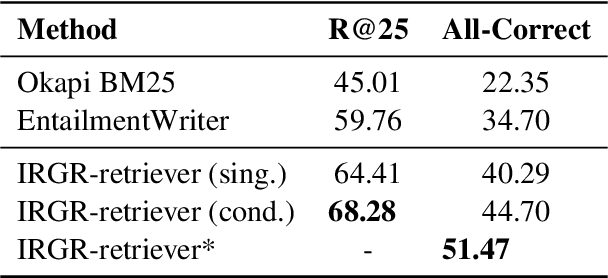
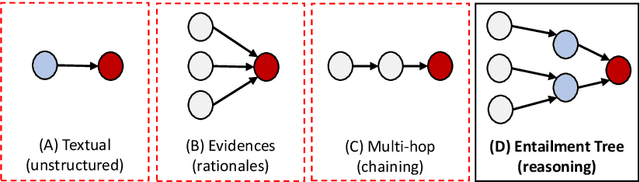
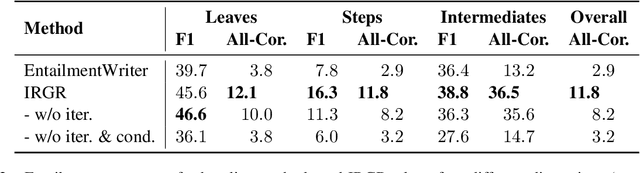
Large language models have achieved high performance on various question answering (QA) benchmarks, but the explainability of their output remains elusive. Structured explanations, called entailment trees, were recently suggested as a way to explain and inspect a QA system's answer. In order to better generate such entailment trees, we propose an architecture called Iterative Retrieval-Generation Reasoner (IRGR). Our model is able to explain a given hypothesis by systematically generating a step-by-step explanation from textual premises. The IRGR model iteratively searches for suitable premises, constructing a single entailment step at a time. Contrary to previous approaches, our method combines generation steps and retrieval of premises, allowing the model to leverage intermediate conclusions, and mitigating the input size limit of baseline encoder-decoder models. We conduct experiments using the EntailmentBank dataset, where we outperform existing benchmarks on premise retrieval and entailment tree generation, with around 300% gain in overall correctness.