 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Design Paradigms for Social Robots
Jul 30, 2024The demand for social robots in fields like healthcare, education, and entertainment increases due to their emotional adaptation features. These robots leverage multimodal communication, incorporating speech, facial expressions, and gestures to enhance user engagement and emotional support. The understanding of design paradigms of social robots is obstructed by the complexity of the system and the necessity to tune it to a specific task. This article provides a structured review of social robot design paradigms, categorizing them into cognitive architectures, role design models, linguistic models, communication flow, activity system models, and integrated design models. By breaking down the articles on social robot design and application based on these paradigms, we highlight the strengths and areas for improvement in current approaches. We further propose our original integrated design model that combines the most important aspects of the design of social robots. Our approach shows the importance of integrating operational, communicational, and emotional dimensions to create more adaptive and empathetic interactions between robots and humans.
ERIT Lightweight Multimodal Dataset for Elderly Emotion Recognition and Multimodal Fusion Evaluation
Jul 25, 2024



ERIT is a novel multimodal dataset designed to facilitate research in a lightweight multimodal fusion. It contains text and image data collected from videos of elderly individuals reacting to various situations, as well as seven emotion labels for each data sample. Because of the use of labeled images of elderly users reacting emotionally, it is also facilitating research on emotion recognition in an underrepresented age group in machine learning visual emotion recognition. The dataset is validated through comprehensive experiments indicating its importance in neural multimodal fusion research.
Hallucinations in Neural Automatic Speech Recognition: Identifying Errors and Hallucinatory Models
Jan 03, 2024



Hallucinations are a type of output error produced by deep neural networks. While this has been studied in natural language processing, they have not been researched previously in automatic speech recognition. Here, we define hallucinations in ASR as transcriptions generated by a model that are semantically unrelated to the source utterance, yet still fluent and coherent. The similarity of hallucinations to probable natural language outputs of the model creates a danger of deception and impacts the credibility of the system. We show that commonly used metrics, such as word error rates, cannot differentiate between hallucinatory and non-hallucinatory models. To address this, we propose a perturbation-based method for assessing the susceptibility of an automatic speech recognition (ASR) model to hallucination at test time, which does not require access to the training dataset. We demonstrate that this method helps to distinguish between hallucinatory and non-hallucinatory models that have similar baseline word error rates. We further explore the relationship between the types of ASR errors and the types of dataset noise to determine what types of noise are most likely to create hallucinatory outputs. We devise a framework for identifying hallucinations by analysing their semantic connection with the ground truth and their fluency. Finally, we discover how to induce hallucinations with a random noise injection to the utterance.
Cross-Lingual Cross-Age Group Adaptation for Low-Resource Elderly Speech Emotion Recognition
Jun 26, 2023Speech emotion recognition plays a crucial role in human-computer interactions. However, most speech emotion recognition research is biased toward English-speaking adults, which hinders its applicability to other demographic groups in different languages and age groups. In this work, we analyze the transferability of emotion recognition across three different languages--English, Mandarin Chinese, and Cantonese; and 2 different age groups--adults and the elderly. To conduct the experiment, we develop an English-Mandarin speech emotion benchmark for adults and the elderly, BiMotion, and a Cantonese speech emotion dataset, YueMotion. This study concludes that different language and age groups require specific speech features, thus making cross-lingual inference an unsuitable method. However, cross-group data augmentation is still beneficial to regularize the model, with linguistic distance being a significant influence on cross-lingual transferability. We release publicly release our code at https://github.com/HLTCHKUST/elderly_ser.
State-of-the-art generalisation research in NLP: a taxonomy and review
Oct 10, 2022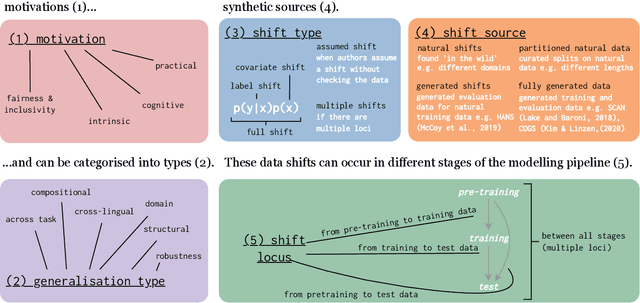
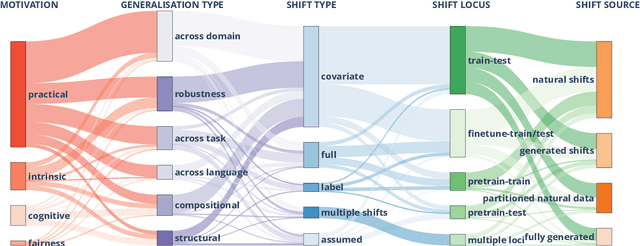
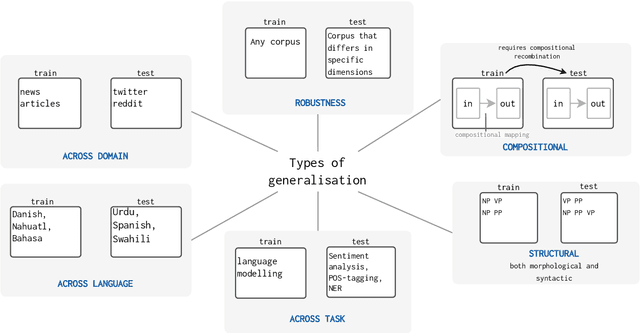

The ability to generalise well is one of the primary desiderata of natural language processing (NLP). Yet, what `good generalisation' entails and how it should be evaluated is not well understood, nor are there any common standards to evaluate it. In this paper, we aim to lay the ground-work to improve both of these issues. We present a taxonomy for characterising and understanding generalisation research in NLP, we use that taxonomy to present a comprehensive map of published generalisation studies, and we make recommendations for which areas might deserve attention in the future. Our taxonomy is based on an extensive literature review of generalisation research, and contains five axes along which studies can differ: their main motivation, the type of generalisation they aim to solve, the type of data shift they consider, the source by which this data shift is obtained, and the locus of the shift within the modelling pipeline. We use our taxonomy to classify over 400 previous papers that test generalisation, for a total of more than 600 individual experiments. Considering the results of this review, we present an in-depth analysis of the current state of generalisation research in NLP, and make recommendations for the future. Along with this paper, we release a webpage where the results of our review can be dynamically explored, and which we intend to up-date as new NLP generalisation studies are published. With this work, we aim to make steps towards making state-of-the-art generalisation testing the new status quo in NLP.
What Did I Just Hear? Detecting Pornographic Sounds in Adult Videos Using Neural Networks
Sep 08, 2022
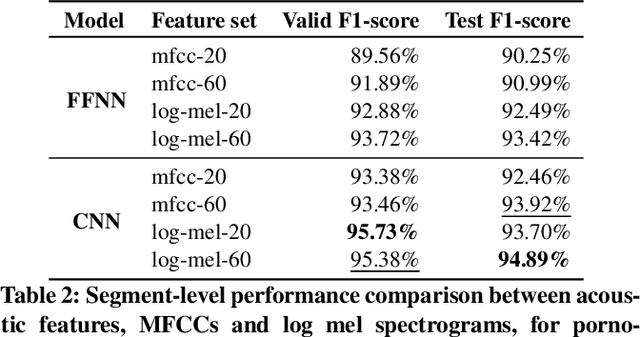
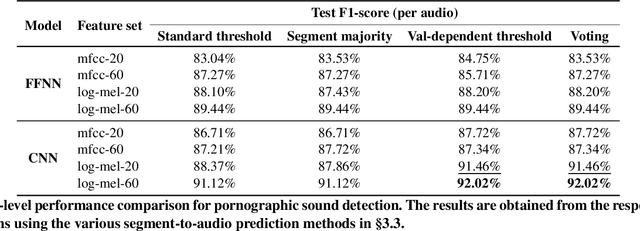
Audio-based pornographic detection enables efficient adult content filtering without sacrificing performance by exploiting distinct spectral characteristics. To improve it, we explore pornographic sound modeling based on different neural architectures and acoustic features. We find that CNN trained on log mel spectrogram achieves the best performance on Pornography-800 dataset. Our experiment results also show that log mel spectrogram allows better representations for the models to recognize pornographic sounds. Finally, to classify whole audio waveforms rather than segments, we employ voting segment-to-audio technique that yields the best audio-level detection results.
VScript: Controllable Script Generation with Audio-Visual Presentation
Mar 01, 2022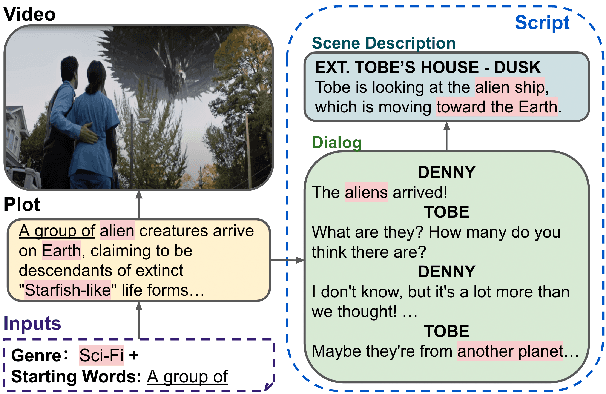
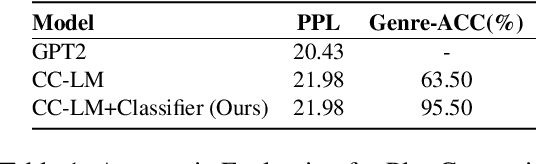
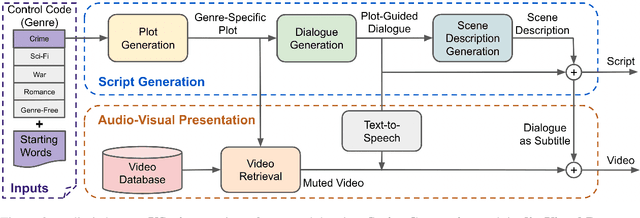
Automatic script generation could save a considerable amount of resources and offer inspiration to professional scriptwriters. We present VScript, a controllable pipeline that generates complete scripts including dialogues and scene descriptions, and presents visually using video retrieval and aurally using text-to-speech for spoken dialogue. With an interactive interface, our system allows users to select genres and input starting words that control the theme and development of the generated script. We adopt a hierarchical structure, which generates the plot, then the script and its audio-visual presentation. We also introduce a novel approach to plot-guided dialogue generation by treating it as an inverse dialogue summarization. Experiment results show that our approach outperforms the baselines on both automatic and human evaluations, especially in terms of genre control.
Survey of Hallucination in Natural Language Generation
Feb 08, 2022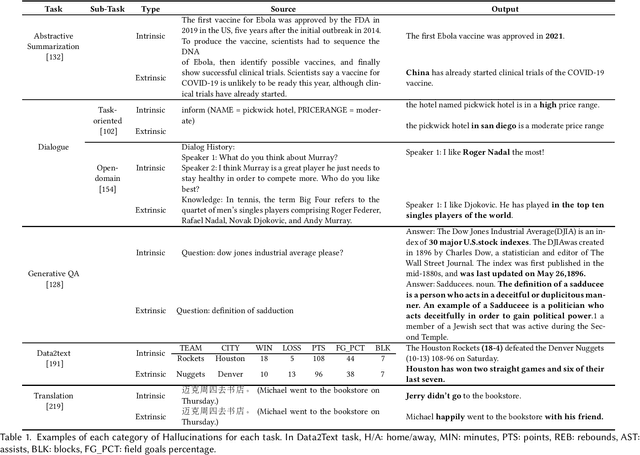
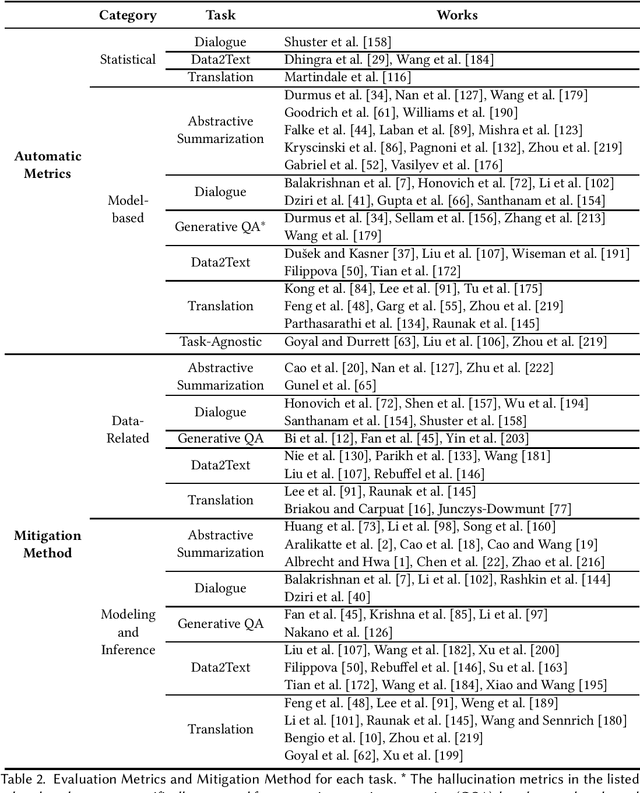
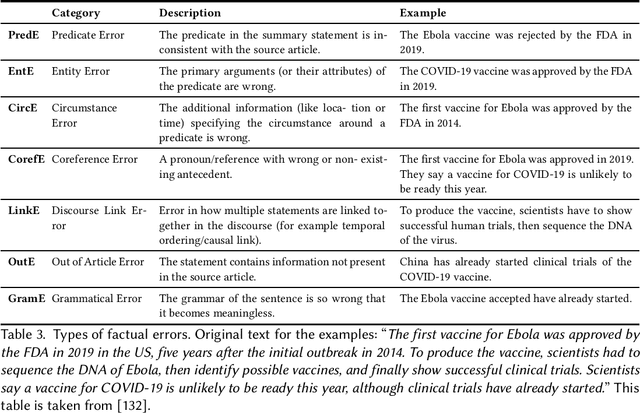
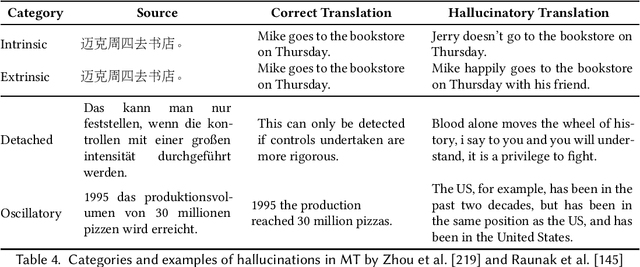
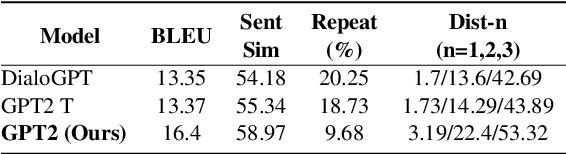
Natural Language Generation (NLG) has improved exponentially in recent years thanks to the development of deep learning technologies such as Transformer-based language models. This advancement has led to more fluent and coherent natural language generation, naturally leading to development in downstream tasks such as abstractive summarization, dialogue generation and data-to-text generation. However, it is also investigated that such generation includes hallucinated texts, which makes the performances of text generation fail to meet users' expectations in many real-world scenarios. In order to address this issue, studies in evaluation and mitigation methods of hallucinations have been presented in various tasks, but have not been reviewed in a combined manner. In this survey, we provide a broad overview of the research progress and challenges in the hallucination problem of NLG. The survey is organized into two big divisions: (i) a general overview of metrics, mitigation methods, and future directions; (ii) task-specific research progress for hallucinations in a large set of downstream tasks: abstractive summarization, dialogue generation, generative question answering, data-to-text generation, and machine translation. This survey could facilitate collaborative efforts among researchers in these tasks.
Automatic Speech Recognition Datasets in Cantonese: A Survey and New Dataset
Jan 17, 2022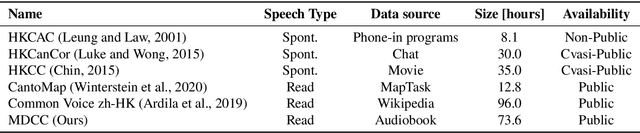
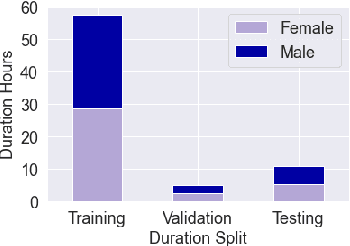
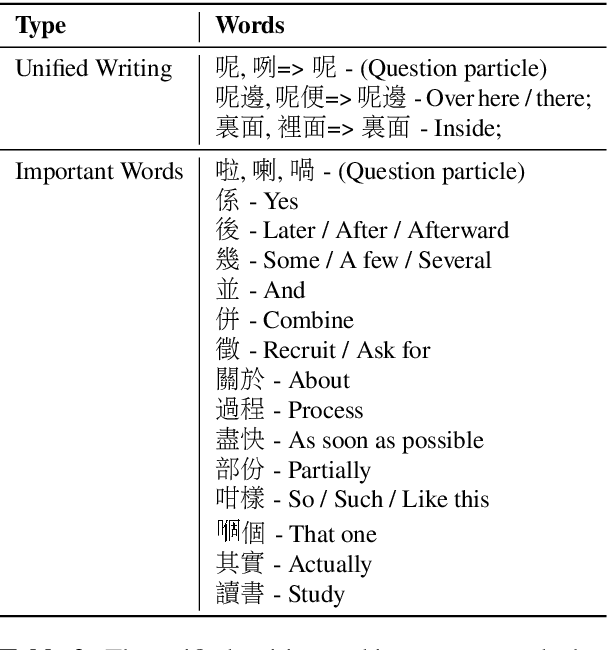
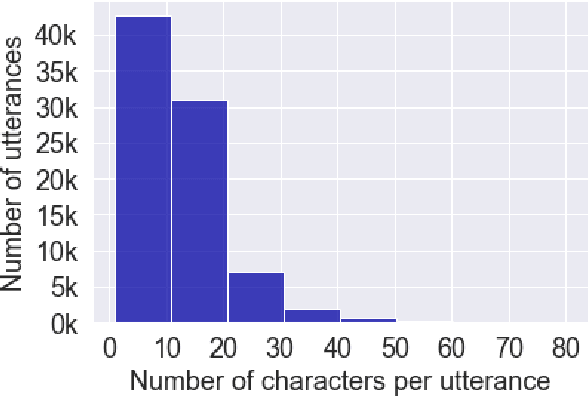
Automatic speech recognition (ASR) on low resource languages improves the access of linguistic minorities to technological advantages provided by artificial intelligence (AI). In this paper, we address the problem of data scarcity for the Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It comprises philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and analyze them according to their speech type, data source, total size and availability. We further conduct experiments with Fairseq S2T Transformer, a state-of-the-art ASR model, on the biggest existing dataset, Common Voice zh-HK, and our proposed MDCC, and the results show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
CI-AVSR: A Cantonese Audio-Visual Speech Dataset for In-car Command Recognition
Jan 11, 2022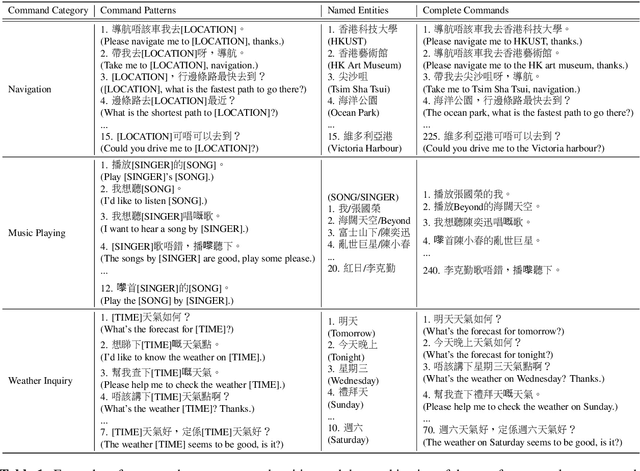
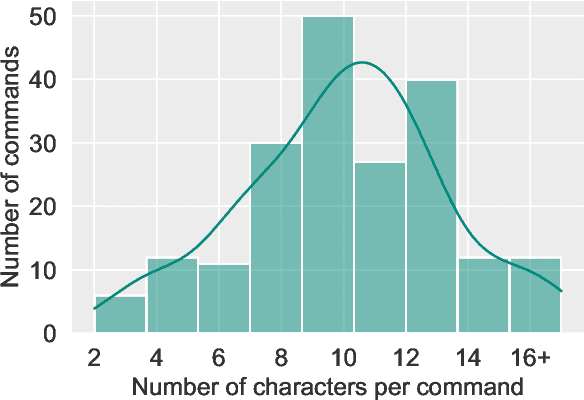
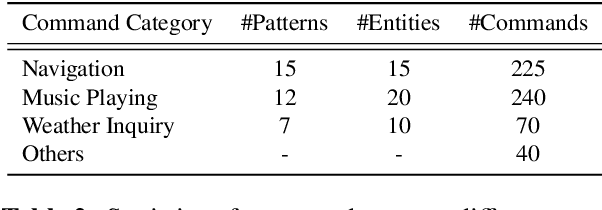
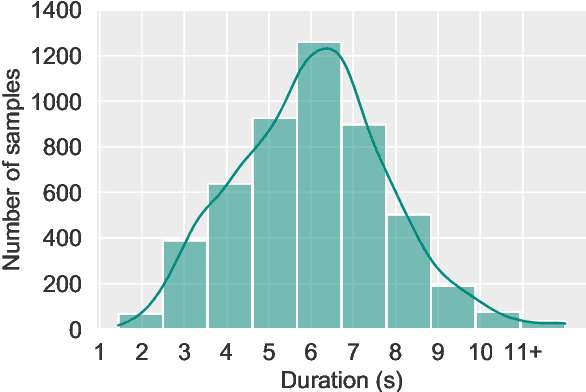
With the rise of deep learning and intelligent vehicle, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, there is a data scarcity issue for low resource languages, hindering the development of research and applications. In this paper, we introduce a new dataset, Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car command recognition in the Cantonese language with both video and audio data. It consists of 4,984 samples (8.3 hours) of 200 in-car commands recorded by 30 native Cantonese speakers. Furthermore, we augment our dataset using common in-car background noises to simulate real environments, producing a dataset 10 times larger than the collected one. We provide detailed statistics of both the clean and the augmented versions of our dataset. Moreover, we implement two multimodal baselines to demonstrate the validity of CI-AVSR. Experiment results show that leveraging the visual signal improves the overall performance of the model. Although our best model can achieve a considerable quality on the clean test set, the speech recognition quality on the noisy data is still inferior and remains as an extremely challenging task for real in-car speech recognition systems. The dataset and code will be released at https://github.com/HLTCHKUST/CI-AVSR.