 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOceanGym: A Benchmark Environment for Underwater Embodied Agents
Sep 30, 2025We introduce OceanGym, the first comprehensive benchmark for ocean underwater embodied agents, designed to advance AI in one of the most demanding real-world environments. Unlike terrestrial or aerial domains, underwater settings present extreme perceptual and decision-making challenges, including low visibility, dynamic ocean currents, making effective agent deployment exceptionally difficult. OceanGym encompasses eight realistic task domains and a unified agent framework driven by Multi-modal Large Language Models (MLLMs), which integrates perception, memory, and sequential decision-making. Agents are required to comprehend optical and sonar data, autonomously explore complex environments, and accomplish long-horizon objectives under these harsh conditions. Extensive experiments reveal substantial gaps between state-of-the-art MLLM-driven agents and human experts, highlighting the persistent difficulty of perception, planning, and adaptability in ocean underwater environments. By providing a high-fidelity, rigorously designed platform, OceanGym establishes a testbed for developing robust embodied AI and transferring these capabilities to real-world autonomous ocean underwater vehicles, marking a decisive step toward intelligent agents capable of operating in one of Earth's last unexplored frontiers. The code and data are available at https://github.com/OceanGPT/OceanGym.
Memp: Exploring Agent Procedural Memory
Aug 08, 2025Large Language Models (LLMs) based agents excel at diverse tasks, yet they suffer from brittle procedural memory that is manually engineered or entangled in static parameters. In this work, we investigate strategies to endow agents with a learnable, updatable, and lifelong procedural memory. We propose Memp that distills past agent trajectories into both fine-grained, step-by-step instructions and higher-level, script-like abstractions, and explore the impact of different strategies for Build, Retrieval, and Update of procedural memory. Coupled with a dynamic regimen that continuously updates, corrects, and deprecates its contents, this repository evolves in lockstep with new experience. Empirical evaluation on TravelPlanner and ALFWorld shows that as the memory repository is refined, agents achieve steadily higher success rates and greater efficiency on analogous tasks. Moreover, procedural memory built from a stronger model retains its value: migrating the procedural memory to a weaker model yields substantial performance gains.
Why Do Open-Source LLMs Struggle with Data Analysis? A Systematic Empirical Study
Jun 24, 2025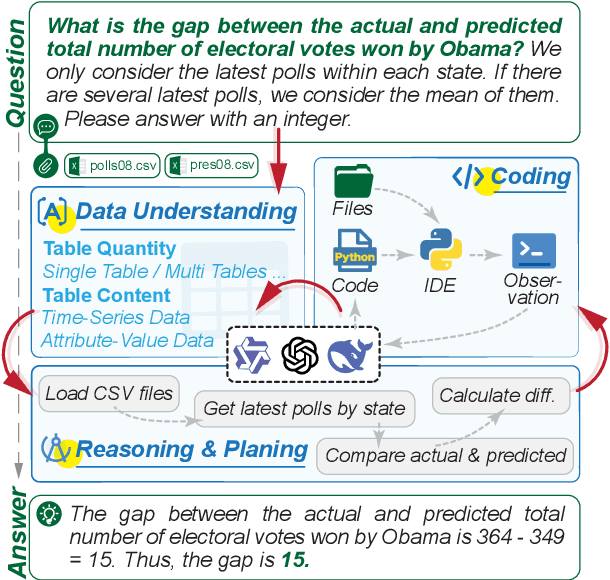
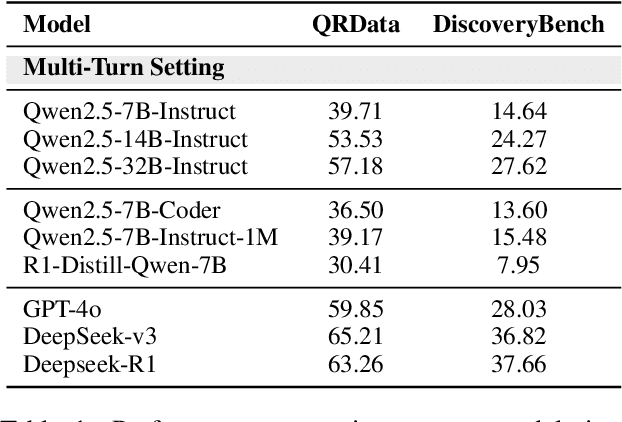
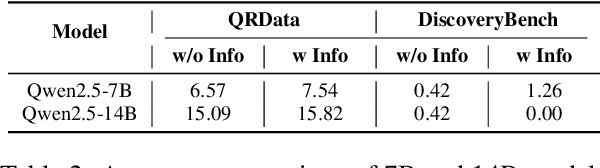
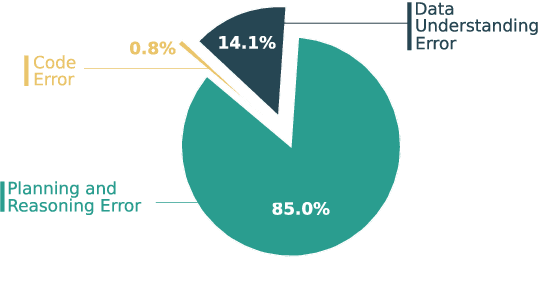
Large Language Models (LLMs) hold promise in automating data analysis tasks, yet open-source models face significant limitations in these kinds of reasoning-intensive scenarios. In this work, we investigate strategies to enhance the data analysis capabilities of open-source LLMs. By curating a seed dataset of diverse, realistic scenarios, we evaluate models across three dimensions: data understanding, code generation, and strategic planning. Our analysis reveals three key findings: (1) Strategic planning quality serves as the primary determinant of model performance; (2) Interaction design and task complexity significantly influence reasoning capabilities; (3) Data quality demonstrates a greater impact than diversity in achieving optimal performance. We leverage these insights to develop a data synthesis methodology, demonstrating significant improvements in open-source LLMs' analytical reasoning capabilities.
KnowRL: Exploring Knowledgeable Reinforcement Learning for Factuality
Jun 24, 2025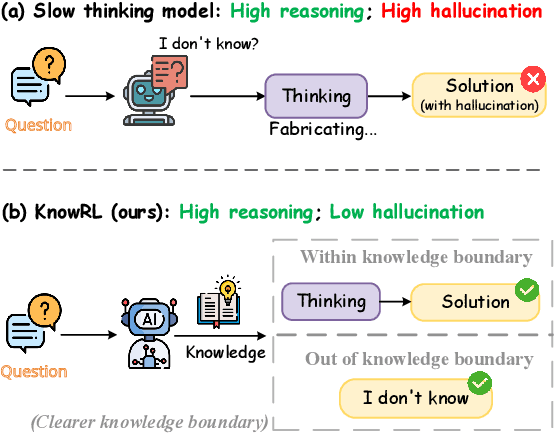
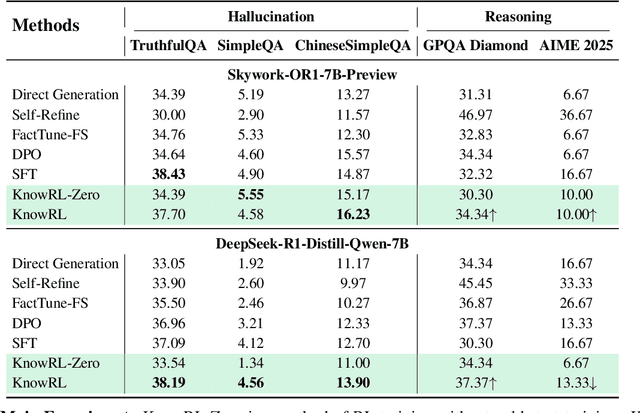
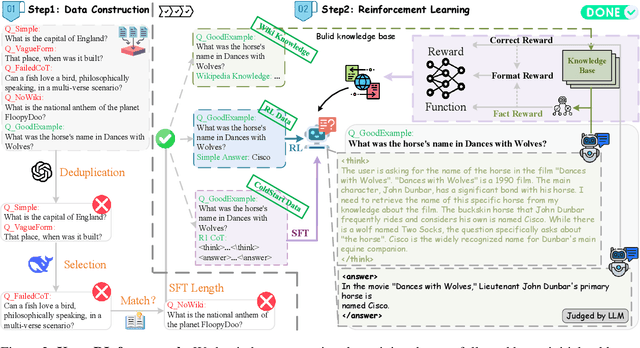
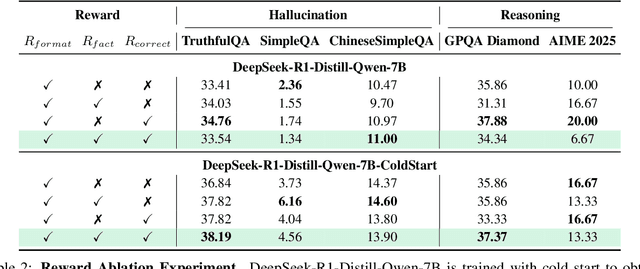
Large Language Models (LLMs), particularly slow-thinking models, often exhibit severe hallucination, outputting incorrect content due to an inability to accurately recognize knowledge boundaries during reasoning. While Reinforcement Learning (RL) can enhance complex reasoning abilities, its outcome-oriented reward mechanism often lacks factual supervision over the thinking process, further exacerbating the hallucination problem. To address the high hallucination in slow-thinking models, we propose Knowledge-enhanced RL, KnowRL. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. This targeted factual input during RL training enables the model to learn and internalize fact-based reasoning strategies. By directly rewarding adherence to facts within the reasoning steps, KnowRL fosters a more reliable thinking process. Experimental results on three hallucination evaluation datasets and two reasoning evaluation datasets demonstrate that KnowRL effectively mitigates hallucinations in slow-thinking models while maintaining their original strong reasoning capabilities. Our code is available at https://github.com/zjunlp/KnowRL.
AutoMind: Adaptive Knowledgeable Agent for Automated Data Science
Jun 12, 2025Large Language Model (LLM) agents have shown great potential in addressing real-world data science problems. LLM-driven data science agents promise to automate the entire machine learning pipeline, yet their real-world effectiveness remains limited. Existing frameworks depend on rigid, pre-defined workflows and inflexible coding strategies; consequently, they excel only on relatively simple, classical problems and fail to capture the empirical expertise that human practitioners bring to complex, innovative tasks. In this work, we introduce AutoMind, an adaptive, knowledgeable LLM-agent framework that overcomes these deficiencies through three key advances: (1) a curated expert knowledge base that grounds the agent in domain expert knowledge, (2) an agentic knowledgeable tree search algorithm that strategically explores possible solutions, and (3) a self-adaptive coding strategy that dynamically tailors code generation to task complexity. Evaluations on two automated data science benchmarks demonstrate that AutoMind delivers superior performance versus state-of-the-art baselines. Additional analyses confirm favorable effectiveness, efficiency, and qualitative solution quality, highlighting AutoMind as an efficient and robust step toward fully automated data science.
ChineseHarm-Bench: A Chinese Harmful Content Detection Benchmark
Jun 12, 2025Large language models (LLMs) have been increasingly applied to automated harmful content detection tasks, assisting moderators in identifying policy violations and improving the overall efficiency and accuracy of content review. However, existing resources for harmful content detection are predominantly focused on English, with Chinese datasets remaining scarce and often limited in scope. We present a comprehensive, professionally annotated benchmark for Chinese content harm detection, which covers six representative categories and is constructed entirely from real-world data. Our annotation process further yields a knowledge rule base that provides explicit expert knowledge to assist LLMs in Chinese harmful content detection. In addition, we propose a knowledge-augmented baseline that integrates both human-annotated knowledge rules and implicit knowledge from large language models, enabling smaller models to achieve performance comparable to state-of-the-art LLMs. Code and data are available at https://github.com/zjunlp/ChineseHarm-bench.
Spatial Knowledge Graph-Guided Multimodal Synthesis
May 28, 2025Recent advances in multimodal large language models (MLLMs) have significantly enhanced their capabilities; however, their spatial perception abilities remain a notable limitation. To address this challenge, multimodal data synthesis offers a promising solution. Yet, ensuring that synthesized data adhere to spatial common sense is a non-trivial task. In this work, we introduce SKG2Data, a novel multimodal synthesis approach guided by spatial knowledge graphs, grounded in the concept of knowledge-to-data generation. SKG2Data automatically constructs a Spatial Knowledge Graph (SKG) to emulate human-like perception of spatial directions and distances, which is subsequently utilized to guide multimodal data synthesis. Extensive experiments demonstrate that data synthesized from diverse types of spatial knowledge, including direction and distance, not only enhance the spatial perception and reasoning abilities of MLLMs but also exhibit strong generalization capabilities. We hope that the idea of knowledge-based data synthesis can advance the development of spatial intelligence.
UniErase: Unlearning Token as a Universal Erasure Primitive for Language Models
May 21, 2025Large language models require iterative updates to address challenges such as knowledge conflicts and outdated information (e.g., incorrect, private, or illegal contents). Machine unlearning provides a systematic methodology for targeted knowledge removal from trained models, enabling elimination of sensitive information influences. However, mainstream fine-tuning-based unlearning methods often fail to balance unlearning efficacy and model ability, frequently resulting in catastrophic model collapse under extensive knowledge removal. Meanwhile, in-context unlearning, which relies solely on contextual prompting without modifying the model's intrinsic mechanisms, suffers from limited generalizability and struggles to achieve true unlearning. In this work, we introduce UniErase, a novel unlearning paradigm that employs learnable parametric suffix (unlearning token) to steer language models toward targeted forgetting behaviors. UniErase operates through two key phases: (I) an optimization stage that binds desired unlearning outputs to the model's autoregressive probability distribution via token optimization, followed by (II) a lightweight model editing phase that activates the learned token to probabilistically induce specified forgetting objective. Serving as a new research direction for token learning to induce unlearning target, UniErase achieves state-of-the-art (SOTA) performance across batch, sequential, and precise unlearning under fictitious and real-world knowledge settings. Remarkably, in terms of TOFU benchmark, UniErase, modifying only around 3.66% of the LLM parameters, outperforms previous forgetting SOTA baseline by around 4.01 times for model ability with even better unlearning efficacy. Similarly, UniErase, maintaining more ability, also surpasses previous retaining SOTA by 35.96% for unlearning efficacy, showing dual top-tier performances in current unlearing domain.
Two Experts Are All You Need for Steering Thinking: Reinforcing Cognitive Effort in MoE Reasoning Models Without Additional Training
May 20, 2025Mixture-of-Experts (MoE) architectures within Large Reasoning Models (LRMs) have achieved impressive reasoning capabilities by selectively activating experts to facilitate structured cognitive processes. Despite notable advances, existing reasoning models often suffer from cognitive inefficiencies like overthinking and underthinking. To address these limitations, we introduce a novel inference-time steering methodology called Reinforcing Cognitive Experts (RICE), designed to improve reasoning performance without additional training or complex heuristics. Leveraging normalized Pointwise Mutual Information (nPMI), we systematically identify specialized experts, termed ''cognitive experts'' that orchestrate meta-level reasoning operations characterized by tokens like ''<think>''. Empirical evaluations with leading MoE-based LRMs (DeepSeek-R1 and Qwen3-235B) on rigorous quantitative and scientific reasoning benchmarks demonstrate noticeable and consistent improvements in reasoning accuracy, cognitive efficiency, and cross-domain generalization. Crucially, our lightweight approach substantially outperforms prevalent reasoning-steering techniques, such as prompt design and decoding constraints, while preserving the model's general instruction-following skills. These results highlight reinforcing cognitive experts as a promising, practical, and interpretable direction to enhance cognitive efficiency within advanced reasoning models.
Knowledge Augmented Complex Problem Solving with Large Language Models: A Survey
May 06, 2025



Problem-solving has been a fundamental driver of human progress in numerous domains. With advancements in artificial intelligence, Large Language Models (LLMs) have emerged as powerful tools capable of tackling complex problems across diverse domains. Unlike traditional computational systems, LLMs combine raw computational power with an approximation of human reasoning, allowing them to generate solutions, make inferences, and even leverage external computational tools. However, applying LLMs to real-world problem-solving presents significant challenges, including multi-step reasoning, domain knowledge integration, and result verification. This survey explores the capabilities and limitations of LLMs in complex problem-solving, examining techniques including Chain-of-Thought (CoT) reasoning, knowledge augmentation, and various LLM-based and tool-based verification techniques. Additionally, we highlight domain-specific challenges in various domains, such as software engineering, mathematical reasoning and proving, data analysis and modeling, and scientific research. The paper further discusses the fundamental limitations of the current LLM solutions and the future directions of LLM-based complex problems solving from the perspective of multi-step reasoning, domain knowledge integration and result verification.