 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Boundaries of Natural Reasoning: Interleaved Bonus from Formal-Logic Verification
Jan 30, 2026Large Language Models (LLMs) show remarkable capabilities, yet their stochastic next-token prediction creates logical inconsistencies and reward hacking that formal symbolic systems avoid. To bridge this gap, we introduce a formal logic verification-guided framework that dynamically interleaves formal symbolic verification with the natural language generation process, providing real-time feedback to detect and rectify errors as they occur. Distinguished from previous neuro-symbolic methods limited by passive post-hoc validation, our approach actively penalizes intermediate fallacies during the reasoning chain. We operationalize this framework via a novel two-stage training pipeline that synergizes formal logic verification-guided supervised fine-tuning and policy optimization. Extensive evaluation on six benchmarks spanning mathematical, logical, and general reasoning demonstrates that our 7B and 14B models outperform state-of-the-art baselines by average margins of 10.4% and 14.2%, respectively. These results validate that formal verification can serve as a scalable mechanism to significantly push the performance boundaries of advanced LLM reasoning.
MM-CRITIC: A Holistic Evaluation of Large Multimodal Models as Multimodal Critique
Nov 12, 2025



The ability of critique is vital for models to self-improve and serve as reliable AI assistants. While extensively studied in language-only settings, multimodal critique of Large Multimodal Models (LMMs) remains underexplored despite their growing capabilities in tasks like captioning and visual reasoning. In this work, we introduce MM-CRITIC, a holistic benchmark for evaluating the critique ability of LMMs across multiple dimensions: basic, correction, and comparison. Covering 8 main task types and over 500 tasks, MM-CRITIC collects responses from various LMMs with different model sizes and is composed of 4471 samples. To enhance the evaluation reliability, we integrate expert-informed ground answers into scoring rubrics that guide GPT-4o in annotating responses and generating reference critiques, which serve as anchors for trustworthy judgments. Extensive experiments validate the effectiveness of MM-CRITIC and provide a comprehensive assessment of leading LMMs' critique capabilities under multiple dimensions. Further analysis reveals some key insights, including the correlation between response quality and critique, and varying critique difficulty across evaluation dimensions. Our code is available at https://github.com/MichealZeng0420/MM-Critic.
EvolProver: Advancing Automated Theorem Proving by Evolving Formalized Problems via Symmetry and Difficulty
Oct 01, 2025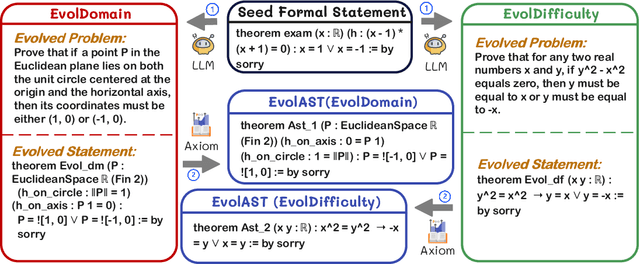
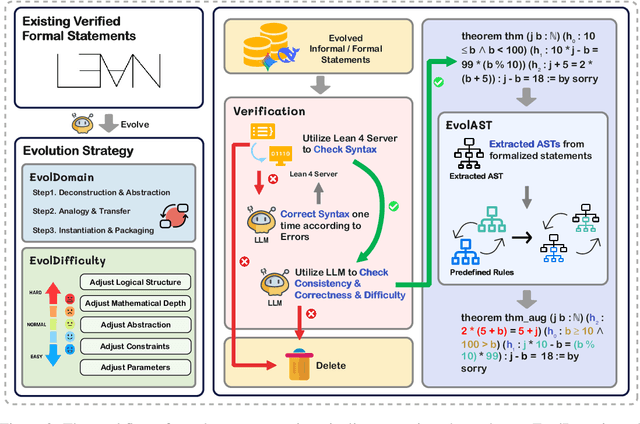
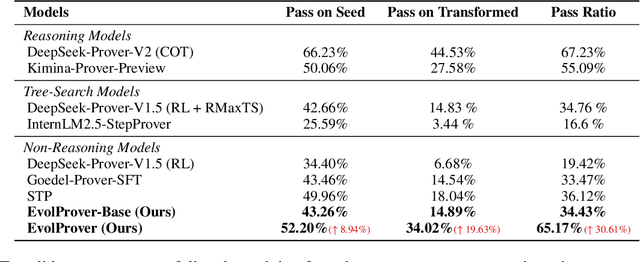

Large Language Models (LLMs) for formal theorem proving have shown significant promise, yet they often lack generalizability and are fragile to even minor transformations of problem statements. To address this limitation, we introduce a novel data augmentation pipeline designed to enhance model robustness from two perspectives: symmetry and difficulty. From the symmetry perspective, we propose two complementary methods: EvolAST, an Abstract Syntax Tree (AST) based approach that targets syntactic symmetry to generate semantically equivalent problem variants, and EvolDomain, which leverages LLMs to address semantic symmetry by translating theorems across mathematical domains. From the difficulty perspective, we propose EvolDifficulty, which uses carefully designed evolutionary instructions to guide LLMs in generating new theorems with a wider range of difficulty. We then use the evolved data to train EvolProver, a 7B-parameter non-reasoning theorem prover. EvolProver establishes a new state-of-the-art (SOTA) on FormalMATH-Lite with a 53.8% pass@32 rate, surpassing all models of comparable size, including reasoning-based models. It also sets new SOTA records for non-reasoning models on MiniF2F-Test (69.8% pass@32), Ineq-Comp-Seed (52.2% pass@32), and Ineq-Comp-Transformed (34.0% pass@32). Ablation studies further confirm our data augmentation pipeline's effectiveness across multiple benchmarks.
Knowledge Augmented Complex Problem Solving with Large Language Models: A Survey
May 06, 2025



Problem-solving has been a fundamental driver of human progress in numerous domains. With advancements in artificial intelligence, Large Language Models (LLMs) have emerged as powerful tools capable of tackling complex problems across diverse domains. Unlike traditional computational systems, LLMs combine raw computational power with an approximation of human reasoning, allowing them to generate solutions, make inferences, and even leverage external computational tools. However, applying LLMs to real-world problem-solving presents significant challenges, including multi-step reasoning, domain knowledge integration, and result verification. This survey explores the capabilities and limitations of LLMs in complex problem-solving, examining techniques including Chain-of-Thought (CoT) reasoning, knowledge augmentation, and various LLM-based and tool-based verification techniques. Additionally, we highlight domain-specific challenges in various domains, such as software engineering, mathematical reasoning and proving, data analysis and modeling, and scientific research. The paper further discusses the fundamental limitations of the current LLM solutions and the future directions of LLM-based complex problems solving from the perspective of multi-step reasoning, domain knowledge integration and result verification.
CodeJudge-Eval: Can Large Language Models be Good Judges in Code Understanding?
Aug 20, 2024



Recent advancements in large language models (LLMs) have showcased impressive code generation capabilities, primarily evaluated through language-to-code benchmarks. However, these benchmarks may not fully capture a model's code understanding abilities. We introduce CodeJudge-Eval (CJ-Eval), a novel benchmark designed to assess LLMs' code understanding abilities from the perspective of code judging rather than code generation. CJ-Eval challenges models to determine the correctness of provided code solutions, encompassing various error types and compilation issues. By leveraging a diverse set of problems and a fine-grained judging system, CJ-Eval addresses the limitations of traditional benchmarks, including the potential memorization of solutions. Evaluation of 12 well-known LLMs on CJ-Eval reveals that even state-of-the-art models struggle, highlighting the benchmark's ability to probe deeper into models' code understanding abilities. Our benchmark will be available at \url{https://github.com/CodeLLM-Research/CodeJudge-Eval}.
CodeHalu: Code Hallucinations in LLMs Driven by Execution-based Verification
Apr 30, 2024



Large Language Models (LLMs) have made significant advancements in the field of code generation, offering unprecedented support for automated programming and assisting developers. However, LLMs sometimes generate code that appears plausible but fails to meet the expected requirements or executes incorrectly. This phenomenon of hallucinations in the coding field has not been explored. To advance the community's understanding and research on code hallucinations in LLMs, we propose a definition method for these hallucinations based on execution verification and introduce the concept of code hallucinations for the first time. We categorize code hallucinations into four main types: mapping, naming, resource, and logic hallucinations, each further divided into different subcategories to better understand and address the unique challenges faced by LLMs during code generation. To systematically evaluate code hallucinations, we propose a dynamic detection algorithm for code hallucinations and construct the CodeHalu benchmark, which includes 8,883 samples from 699 tasks, to actively detect hallucination phenomena in LLMs during programming. We tested 16 popular LLMs on this benchmark to evaluate the frequency and nature of their hallucinations during code generation. The findings reveal significant variations in the accuracy and reliability of LLMs in generating code, highlighting the urgent need to improve models and training methods to ensure the functional correctness and safety of automatically generated code. This study not only classifies and quantifies code hallucinations but also provides insights for future improvements in LLM-based code generation research. The CodeHalu benchmark and code are publicly available at https://github.com/yuchen814/CodeHalu.
MMCode: Evaluating Multi-Modal Code Large Language Models with Visually Rich Programming Problems
Apr 15, 2024



Programming often involves converting detailed and complex specifications into code, a process during which developers typically utilize visual aids to more effectively convey concepts. While recent developments in Large Multimodal Models have demonstrated remarkable abilities in visual reasoning and mathematical tasks, there is little work on investigating whether these models can effectively interpret visual elements for code generation. To this end, we present MMCode, the first multi-modal coding dataset for evaluating algorithmic problem-solving skills in visually rich contexts. MMCode contains 3,548 questions and 6,620 images collected from real-world programming challenges harvested from 10 code competition websites, presenting significant challenges due to the extreme demand for reasoning abilities. Our experiment results show that current state-of-the-art models struggle to solve these problems. The results highlight the lack of powerful vision-code models, and we hope MMCode can serve as an inspiration for future works in this domain. The data and code are publicly available at https://github.com/happylkx/MMCode.
Token Alignment via Character Matching for Subword Completion
Mar 13, 2024



Generative models, widely utilized in various applications, can often struggle with prompts corresponding to partial tokens. This struggle stems from tokenization, where partial tokens fall out of distribution during inference, leading to incorrect or nonsensical outputs. This paper examines a technique to alleviate the tokenization artifact on text completion in generative models, maintaining performance even in regular non-subword cases. The method, termed token alignment, involves backtracking to the last complete tokens and ensuring the model's generation aligns with the prompt. This approach showcases marked improvement across many partial token scenarios, including nuanced cases like space-prefix and partial indentation, with only a minor time increase. The technique and analysis detailed in this paper contribute to the continuous advancement of generative models in handling partial inputs, bearing relevance for applications like code completion and text autocompletion.
CodeTransOcean: A Comprehensive Multilingual Benchmark for Code Translation
Oct 08, 2023



Recent code translation techniques exploit neural machine translation models to translate source code from one programming language to another to satisfy production compatibility or to improve efficiency of codebase maintenance. Most existing code translation datasets only focus on a single pair of popular programming languages. To advance research on code translation and meet diverse requirements of real-world applications, we construct CodeTransOcean, a large-scale comprehensive benchmark that supports the largest variety of languages for code translation. CodeTransOcean consists of three novel multilingual datasets, namely, MultilingualTrans supporting translations between multiple popular programming languages, NicheTrans for translating between niche programming languages and popular ones, and LLMTrans for evaluating compilability of translated code by large language models (LLMs). CodeTransOcean also includes a novel cross-framework dataset, DLTrans, for translating deep learning code across different frameworks. We develop multilingual modeling approaches for code translation and demonstrate their great potential in improving the translation quality of both low-resource and high-resource language pairs and boosting the training efficiency. We also propose a novel evaluation metric Debugging Success Rate@K for program-level code translation. Last but not least, we evaluate LLM ChatGPT on our datasets and investigate its potential for fuzzy compilation predictions. We build baselines for CodeTransOcean and analyze challenges of code translation for guiding future research.
A Static Evaluation of Code Completion by Large Language Models
Jun 05, 2023



Large language models trained on code have shown great potential to increase productivity of software developers. Several execution-based benchmarks have been proposed to evaluate functional correctness of model-generated code on simple programming problems. Nevertheless, it is expensive to perform the same evaluation on complex real-world projects considering the execution cost. On the contrary, static analysis tools such as linters, which can detect errors without running the program, haven't been well explored for evaluating code generation models. In this work, we propose a static evaluation framework to quantify static errors in Python code completions, by leveraging Abstract Syntax Trees. Compared with execution-based evaluation, our method is not only more efficient, but also applicable to code in the wild. For experiments, we collect code context from open source repos to generate one million function bodies using public models. Our static analysis reveals that Undefined Name and Unused Variable are the most common errors among others made by language models. Through extensive studies, we also show the impact of sampling temperature, model size, and context on static errors in code completions.