 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Code Sketches
Jun 18, 2021

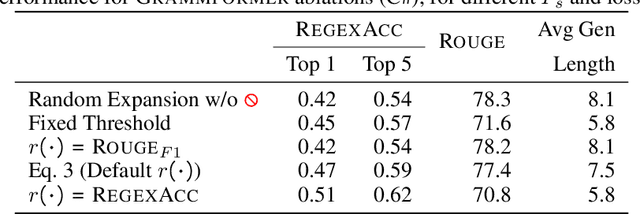
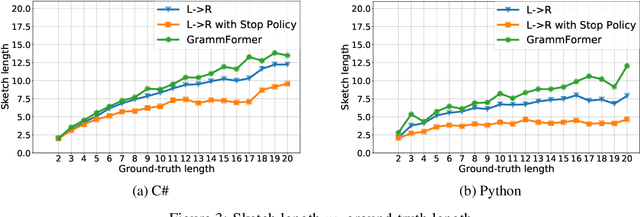
Traditional generative models are limited to predicting sequences of terminal tokens. However, ambiguities in the generation task may lead to incorrect outputs. Towards addressing this, we introduce Grammformers, transformer-based grammar-guided models that learn (without explicit supervision) to generate sketches -- sequences of tokens with holes. Through reinforcement learning, Grammformers learn to introduce holes avoiding the generation of incorrect tokens where there is ambiguity in the target task. We train Grammformers for statement-level source code completion, i.e., the generation of code snippets given an ambiguous user intent, such as a partial code context. We evaluate Grammformers on code completion for C# and Python and show that it generates 10-50% more accurate sketches compared to traditional generative models and 37-50% longer sketches compared to sketch-generating baselines trained with similar techniques.
GEM: A General Evaluation Benchmark for Multimodal Tasks
Jun 18, 2021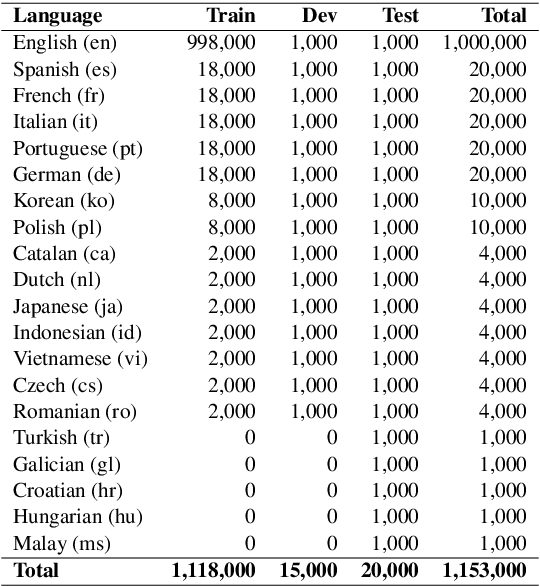

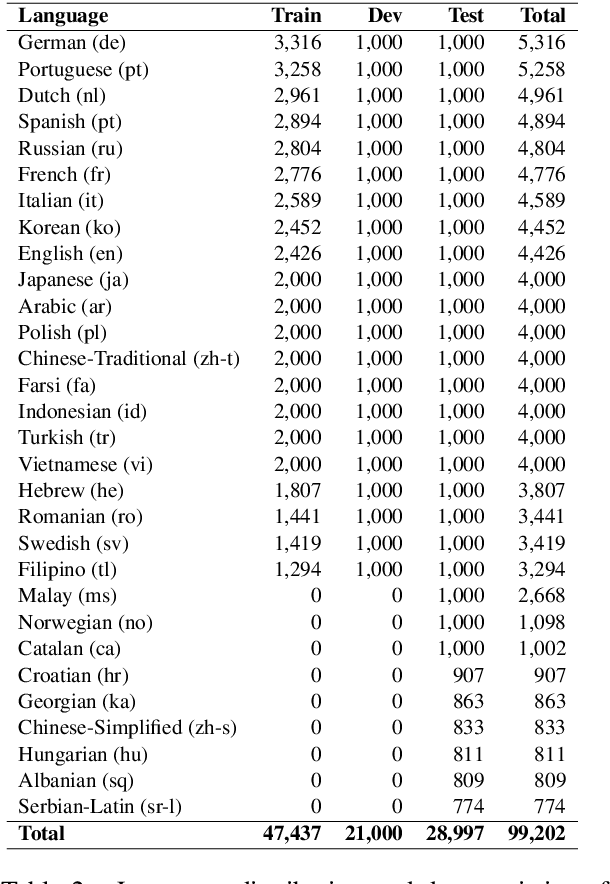

In this paper, we present GEM as a General Evaluation benchmark for Multimodal tasks. Different from existing datasets such as GLUE, SuperGLUE, XGLUE and XTREME that mainly focus on natural language tasks, GEM is a large-scale vision-language benchmark, which consists of GEM-I for image-language tasks and GEM-V for video-language tasks. Comparing with existing multimodal datasets such as MSCOCO and Flicker30K for image-language tasks, YouCook2 and MSR-VTT for video-language tasks, GEM is not only the largest vision-language dataset covering image-language tasks and video-language tasks at the same time, but also labeled in multiple languages. We also provide two baseline models for this benchmark. We will release the dataset, code and baseline models, aiming to advance the development of multilingual multimodal research.
FastSeq: Make Sequence Generation Faster
Jun 08, 2021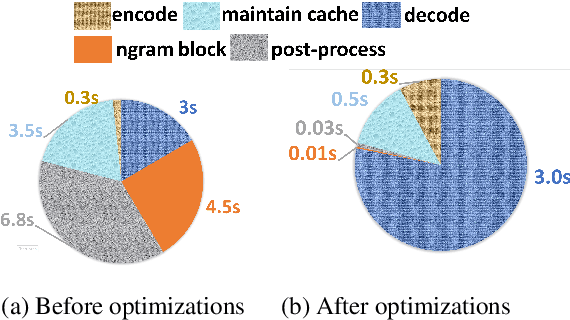
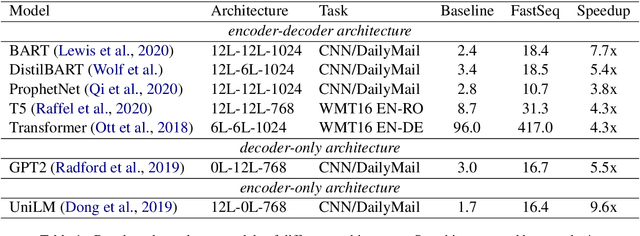
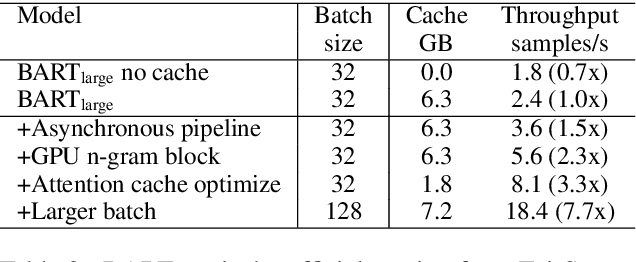
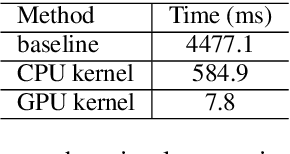
Transformer-based models have made tremendous impacts in natural language generation. However the inference speed is a bottleneck due to large model size and intensive computing involved in auto-regressive decoding process. We develop FastSeq framework to accelerate sequence generation without accuracy loss. The proposed optimization techniques include an attention cache optimization, an efficient algorithm for detecting repeated n-grams, and an asynchronous generation pipeline with parallel I/O. These optimizations are general enough to be applicable to Transformer-based models (e.g., T5, GPT2, and UniLM). Our benchmark results on a set of widely used and diverse models demonstrate 4-9x inference speed gain. Additionally, FastSeq is easy to use with a simple one-line code change. The source code is available at https://github.com/microsoft/fastseq.
CoSQA: 20,000+ Web Queries for Code Search and Question Answering
May 27, 2021
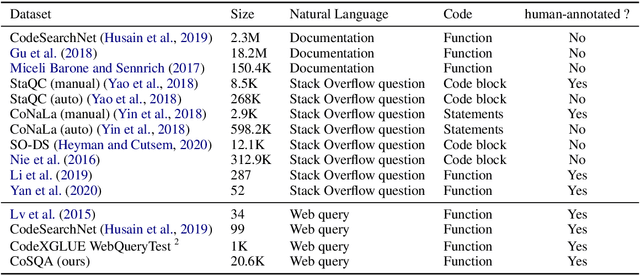

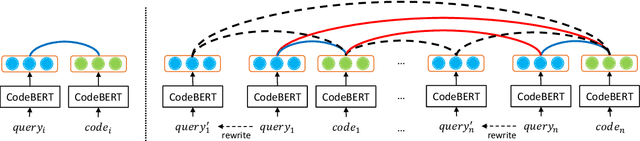
Finding codes given natural language query isb eneficial to the productivity of software developers. Future progress towards better semantic matching between query and code requires richer supervised training resources. To remedy this, we introduce the CoSQA dataset.It includes 20,604 labels for pairs of natural language queries and codes, each annotated by at least 3 human annotators. We further introduce a contrastive learning method dubbed CoCLR to enhance query-code matching, which works as a data augmenter to bring more artificially generated training instances. We show that evaluated on CodeXGLUE with the same CodeBERT model, training on CoSQA improves the accuracy of code question answering by 5.1%, and incorporating CoCLR brings a further improvement of 10.5%.
EL-Attention: Memory Efficient Lossless Attention for Generation
May 11, 2021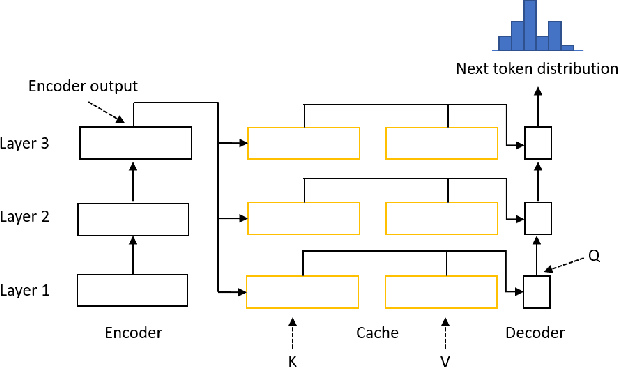
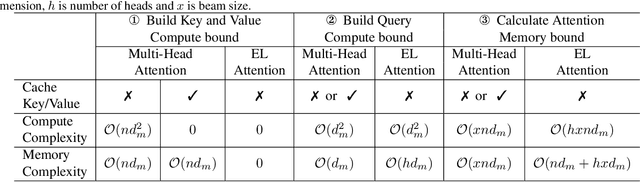
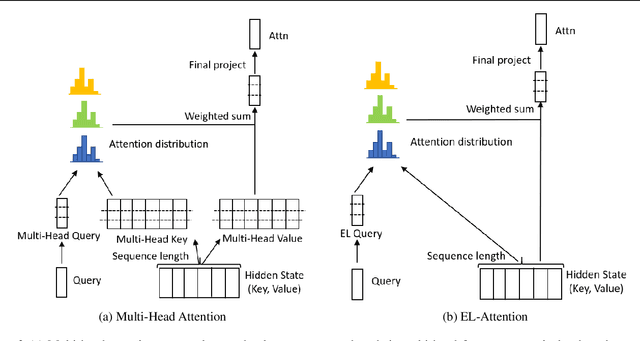
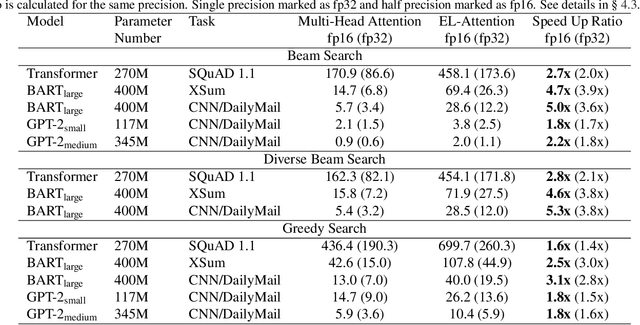
Transformer model with multi-head attention requires caching intermediate results for efficient inference in generation tasks. However, cache brings new memory-related costs and prevents leveraging larger batch size for faster speed. We propose memory-efficient lossless attention (called EL-attention) to address this issue. It avoids heavy operations for building multi-head keys and values, with no requirements of using cache. EL-attention constructs an ensemble of attention results by expanding query while keeping key and value shared. It produces the same result as multi-head attention with less GPU memory and faster inference speed. We conduct extensive experiments on Transformer, BART, and GPT-2 for summarization and question generation tasks. The results show EL-attention speeds up existing models by 1.6x to 5.3x without accuracy loss.
Poolingformer: Long Document Modeling with Pooling Attention
May 10, 2021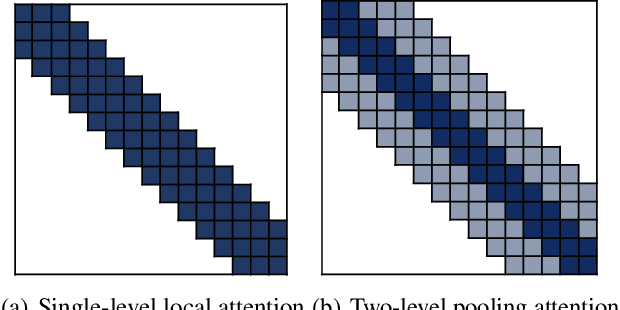
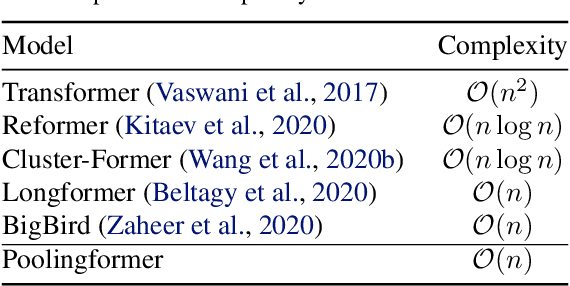
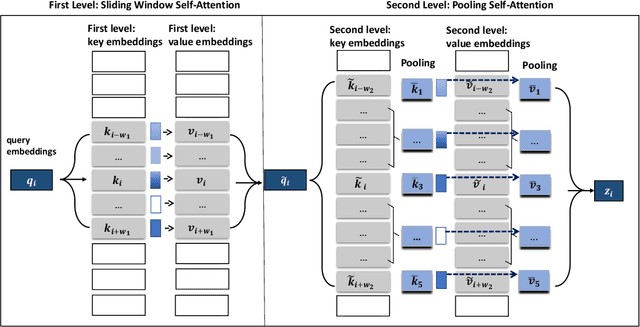
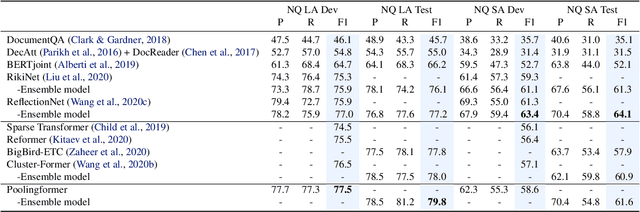
In this paper, we introduce a two-level attention schema, Poolingformer, for long document modeling. Its first level uses a smaller sliding window pattern to aggregate information from neighbors. Its second level employs a larger window to increase receptive fields with pooling attention to reduce both computational cost and memory consumption. We first evaluate Poolingformer on two long sequence QA tasks: the monolingual NQ and the multilingual TyDi QA. Experimental results show that Poolingformer sits atop three official leaderboards measured by F1, outperforming previous state-of-the-art models by 1.9 points (79.8 vs. 77.9) on NQ long answer, 1.9 points (79.5 vs. 77.6) on TyDi QA passage answer, and 1.6 points (67.6 vs. 66.0) on TyDi QA minimal answer. We further evaluate Poolingformer on a long sequence summarization task. Experimental results on the arXiv benchmark continue to demonstrate its superior performance.
Logic-Driven Context Extension and Data Augmentation for Logical Reasoning of Text
May 08, 2021

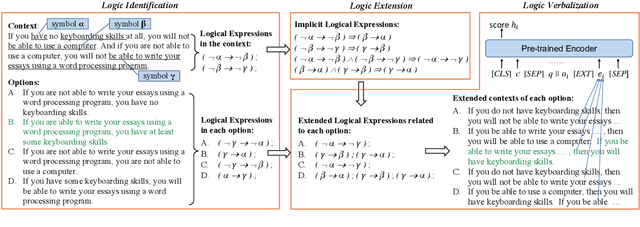
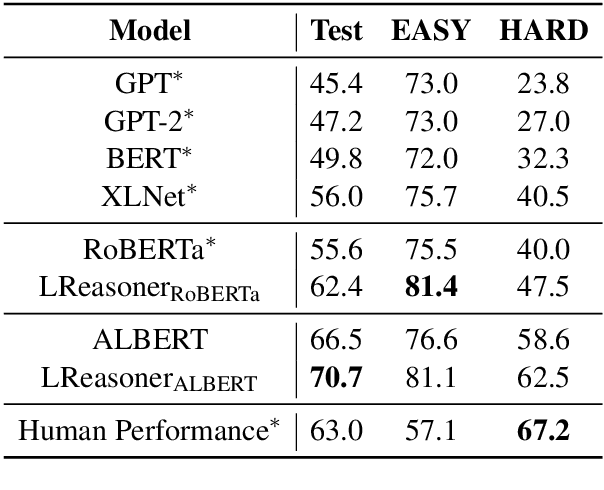
Logical reasoning of text requires understanding critical logical information in the text and performing inference over them. Large-scale pre-trained models for logical reasoning mainly focus on word-level semantics of text while struggling to capture symbolic logic. In this paper, we propose to understand logical symbols and expressions in the text to arrive at the answer. Based on such logical information, we not only put forward a context extension framework but also propose a data augmentation algorithm. The former extends the context to cover implicit logical expressions following logical equivalence laws. The latter augments literally similar but logically different instances to better capture logical information, especially logical negative and conditional relationships. We conduct experiments on ReClor dataset. The results show that our method achieves the state-of-the-art performance, and both logic-driven context extension framework and data augmentation algorithm can help improve the accuracy. And our multi-model ensemble system is the first to surpass human performance on both EASY set and HARD set of ReClor.
CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
May 08, 2021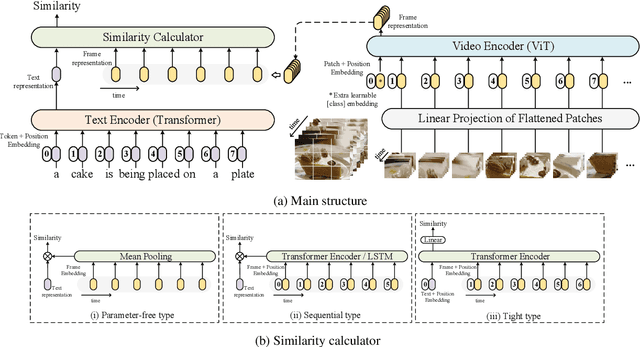
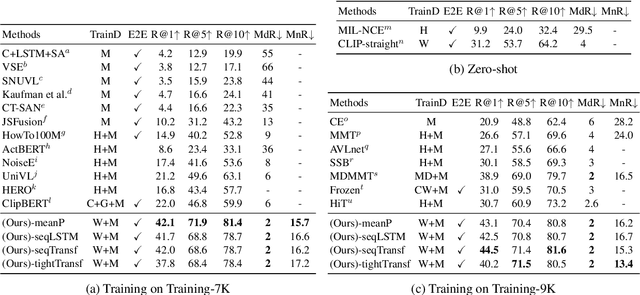

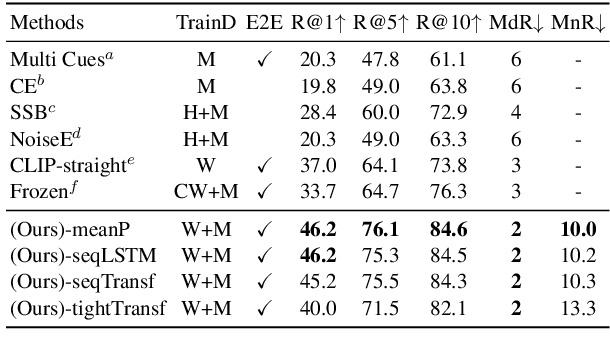
Video-text retrieval plays an essential role in multi-modal research and has been widely used in many real-world web applications. The CLIP (Contrastive Language-Image Pre-training), an image-language pre-training model, has demonstrated the power of visual concepts learning from web collected image-text datasets. In this paper, we propose a CLIP4Clip model to transfer the knowledge of the CLIP model to video-language retrieval in an end-to-end manner. Several questions are investigated via empirical studies: 1) Whether image feature is enough for video-text retrieval? 2) How a post-pretraining on a large-scale video-text dataset based on the CLIP affect the performance? 3) What is the practical mechanism to model temporal dependency between video frames? And 4) The Hyper-parameters sensitivity of the model on video-text retrieval task. Extensive experimental results present that the CLIP4Clip model transferred from the CLIP can achieve SOTA results on various video-text retrieval datasets, including MSR-VTT, MSVC, LSMDC, ActivityNet, and DiDeMo. We release our code at https://github.com/ArrowLuo/CLIP4Clip.
GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions
Apr 30, 2021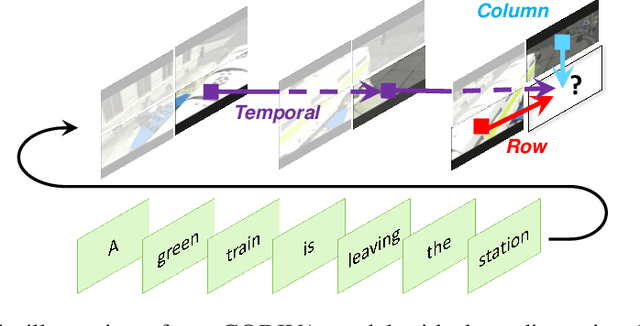
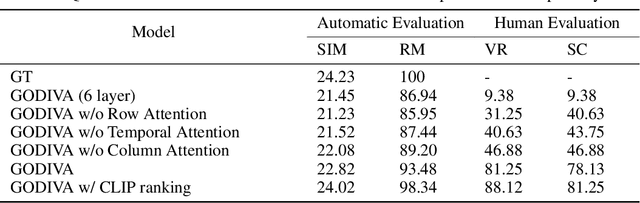
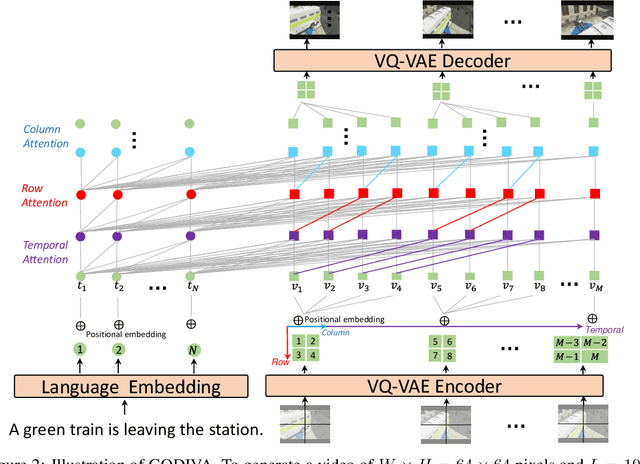

Generating videos from text is a challenging task due to its high computational requirements for training and infinite possible answers for evaluation. Existing works typically experiment on simple or small datasets, where the generalization ability is quite limited. In this work, we propose GODIVA, an open-domain text-to-video pretrained model that can generate videos from text in an auto-regressive manner using a three-dimensional sparse attention mechanism. We pretrain our model on Howto100M, a large-scale text-video dataset that contains more than 136 million text-video pairs. Experiments show that GODIVA not only can be fine-tuned on downstream video generation tasks, but also has a good zero-shot capability on unseen texts. We also propose a new metric called Relative Matching (RM) to automatically evaluate the video generation quality. Several challenges are listed and discussed as future work.
ProphetNet-X: Large-Scale Pre-training Models for English, Chinese, Multi-lingual, Dialog, and Code Generation
Apr 16, 2021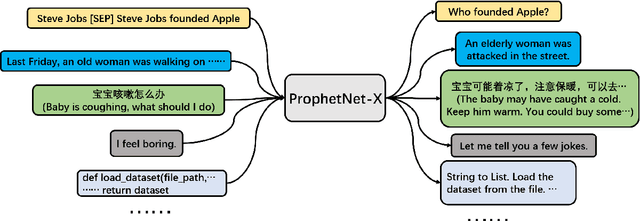

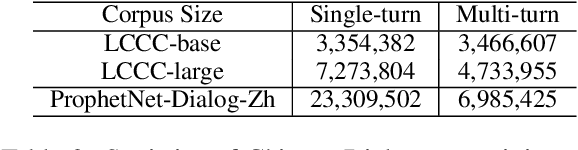
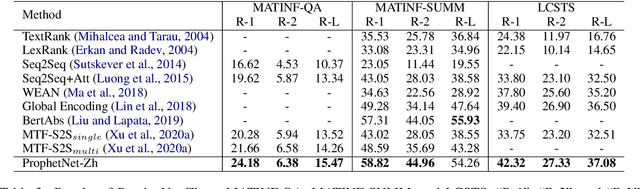
Now, the pre-training technique is ubiquitous in natural language processing field. ProphetNet is a pre-training based natural language generation method which shows powerful performance on English text summarization and question generation tasks. In this paper, we extend ProphetNet into other domains and languages, and present the ProphetNet family pre-training models, named ProphetNet-X, where X can be English, Chinese, Multi-lingual, and so on. We pre-train a cross-lingual generation model ProphetNet-Multi, a Chinese generation model ProphetNet-Zh, two open-domain dialog generation models ProphetNet-Dialog-En and ProphetNet-Dialog-Zh. And also, we provide a PLG (Programming Language Generation) model ProphetNet-Code to show the generation performance besides NLG (Natural Language Generation) tasks. In our experiments, ProphetNet-X models achieve new state-of-the-art performance on 10 benchmarks. All the models of ProphetNet-X share the same model structure, which allows users to easily switch between different models. We make the code and models publicly available, and we will keep updating more pre-training models and finetuning scripts. A video to introduce ProphetNet-X usage is also released.