 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTRLEval: An Unsupervised Reference-Free Metric for Evaluating Controlled Text Generation
Apr 02, 2022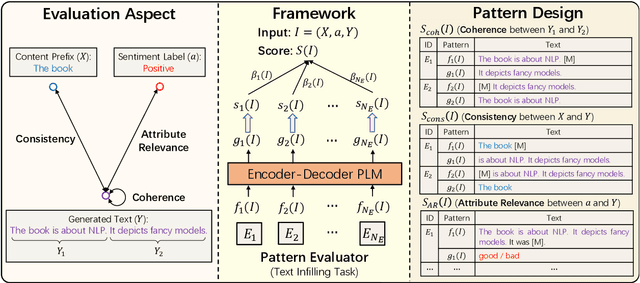


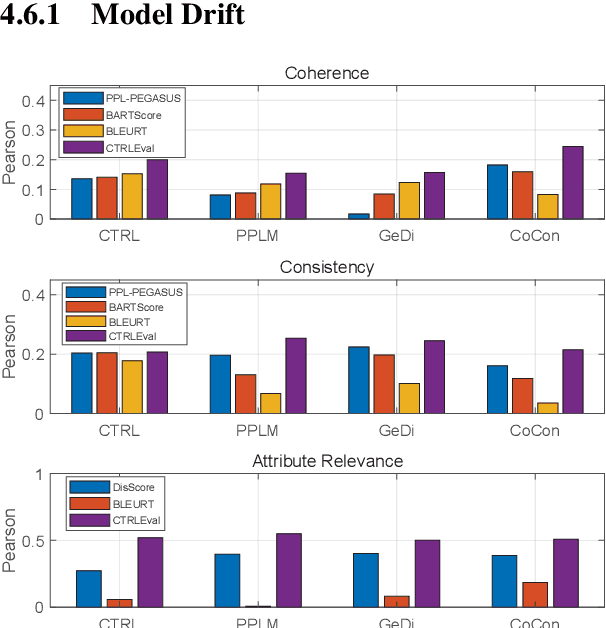
Existing reference-free metrics have obvious limitations for evaluating controlled text generation models. Unsupervised metrics can only provide a task-agnostic evaluation result which correlates weakly with human judgments, whereas supervised ones may overfit task-specific data with poor generalization ability to other datasets. In this paper, we propose an unsupervised reference-free metric called CTRLEval, which evaluates controlled text generation from different aspects by formulating each aspect into multiple text infilling tasks. On top of these tasks, the metric assembles the generation probabilities from a pre-trained language model without any model training. Experimental results show that our metric has higher correlations with human judgments than other baselines, while obtaining better generalization of evaluating generated texts from different models and with different qualities.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Chat-Capsule: A Hierarchical Capsule for Dialog-level Emotion Analysis
Mar 23, 2022

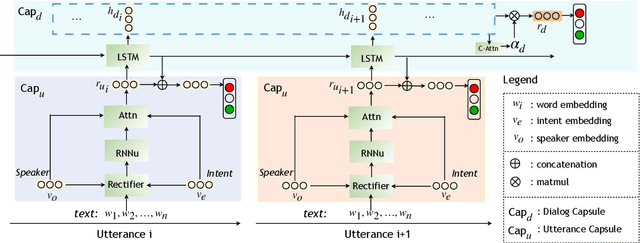
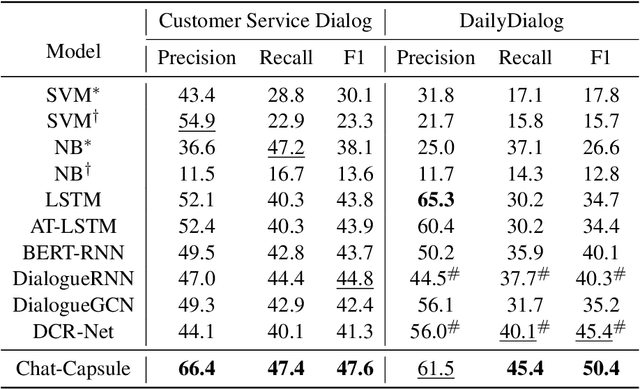
Many studies on dialog emotion analysis focus on utterance-level emotion only. These models hence are not optimized for dialog-level emotion detection, i.e. to predict the emotion category of a dialog as a whole. More importantly, these models cannot benefit from the context provided by the whole dialog. In real-world applications, annotations to dialog could fine-grained, including both utterance-level tags (e.g. speaker type, intent category, and emotion category), and dialog-level tags (e.g. user satisfaction, and emotion curve category). In this paper, we propose a Context-based Hierarchical Attention Capsule~(Chat-Capsule) model, which models both utterance-level and dialog-level emotions and their interrelations. On a dialog dataset collected from customer support of an e-commerce platform, our model is also able to predict user satisfaction and emotion curve category. Emotion curve refers to the change of emotions along the development of a conversation. Experiments show that the proposed Chat-Capsule outperform state-of-the-art baselines on both benchmark dataset and proprietary dataset. Source code will be released upon acceptance.
EVA2.0: Investigating Open-Domain Chinese Dialogue Systems with Large-Scale Pre-Training
Mar 17, 2022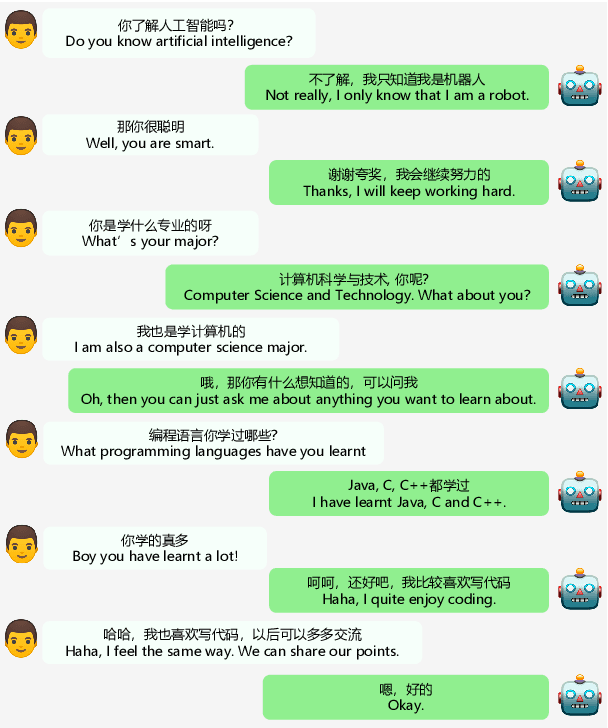


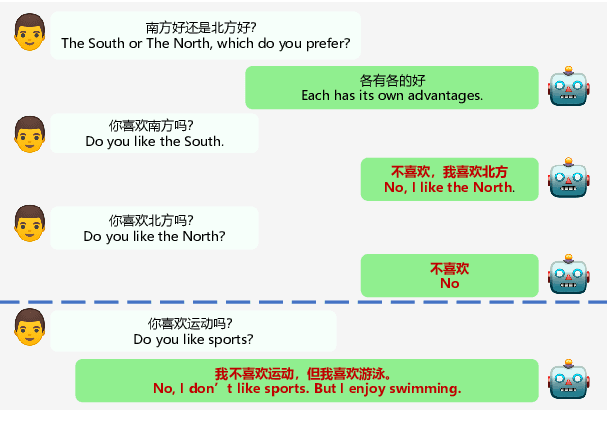
Large-scale pre-training has shown remarkable performance in building open-domain dialogue systems. However, previous works mainly focus on showing and evaluating the conversational performance of the released dialogue model, ignoring the discussion of some key factors towards a powerful human-like chatbot, especially in Chinese scenarios. In this paper, we conduct extensive experiments to investigate these under-explored factors, including data quality control, model architecture designs, training approaches, and decoding strategies. We propose EVA2.0, a large-scale pre-trained open-domain Chinese dialogue model with 2.8 billion parameters, and make our models and code publicly available. To our knowledge, EVA2.0 is the largest open-source Chinese dialogue model. Automatic and human evaluations show that our model significantly outperforms other open-source counterparts. We also discuss the limitations of this work by presenting some failure cases and pose some future directions.
Continual Prompt Tuning for Dialog State Tracking
Mar 13, 2022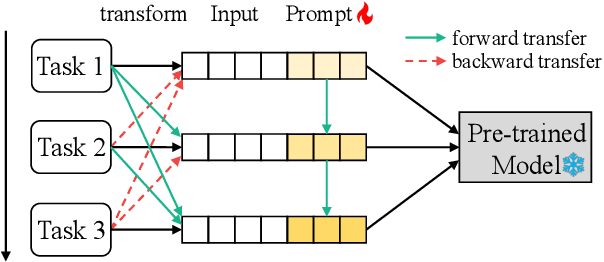
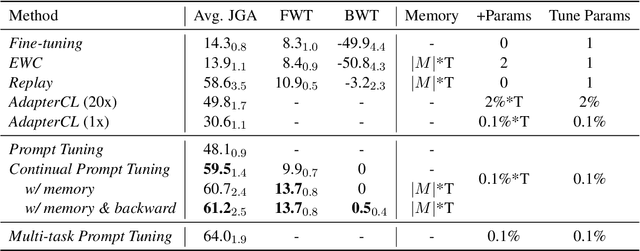
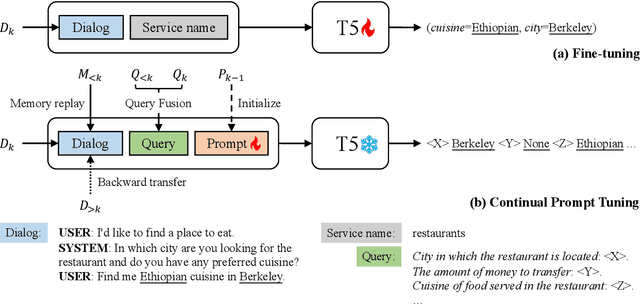

A desirable dialog system should be able to continually learn new skills without forgetting old ones, and thereby adapt to new domains or tasks in its life cycle. However, continually training a model often leads to a well-known catastrophic forgetting issue. In this paper, we present Continual Prompt Tuning, a parameter-efficient framework that not only avoids forgetting but also enables knowledge transfer between tasks. To avoid forgetting, we only learn and store a few prompt tokens' embeddings for each task while freezing the backbone pre-trained model. To achieve bi-directional knowledge transfer among tasks, we propose several techniques (continual prompt initialization, query fusion, and memory replay) to transfer knowledge from preceding tasks and a memory-guided technique to transfer knowledge from subsequent tasks. Extensive experiments demonstrate the effectiveness and efficiency of our proposed method on continual learning for dialog state tracking, compared with state-of-the-art baselines.
Acceleration of Federated Learning with Alleviated Forgetting in Local Training
Mar 05, 2022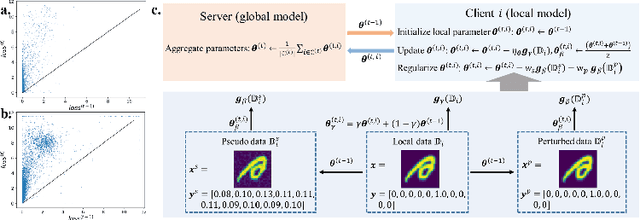
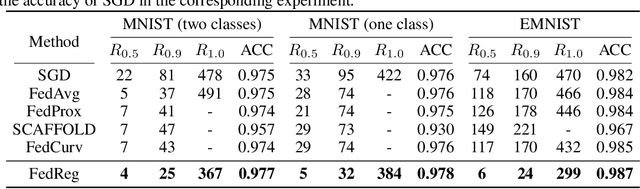
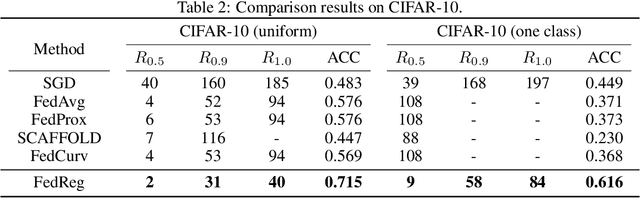
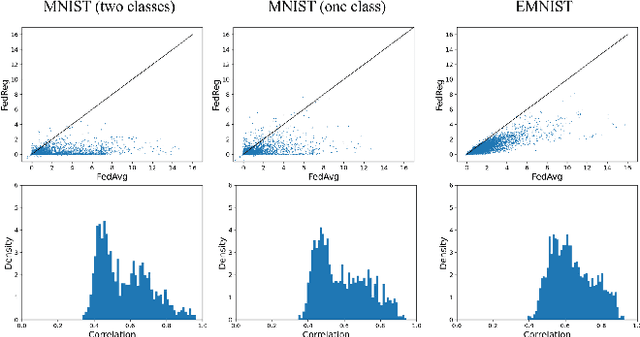
Federated learning (FL) enables distributed optimization of machine learning models while protecting privacy by independently training local models on each client and then aggregating parameters on a central server, thereby producing an effective global model. Although a variety of FL algorithms have been proposed, their training efficiency remains low when the data are not independently and identically distributed (non-i.i.d.) across different clients. We observe that the slow convergence rates of the existing methods are (at least partially) caused by the catastrophic forgetting issue during the local training stage on each individual client, which leads to a large increase in the loss function concerning the previous training data at the other clients. Here, we propose FedReg, an algorithm to accelerate FL with alleviated knowledge forgetting in the local training stage by regularizing locally trained parameters with the loss on generated pseudo data, which encode the knowledge of previous training data learned by the global model. Our comprehensive experiments demonstrate that FedReg not only significantly improves the convergence rate of FL, especially when the neural network architecture is deep and the clients' data are extremely non-i.i.d., but is also able to protect privacy better in classification problems and more robust against gradient inversion attacks. The code is available at: https://github.com/Zoesgithub/FedReg.
AugESC: Large-scale Data Augmentation for Emotional Support Conversation with Pre-trained Language Models
Feb 26, 2022


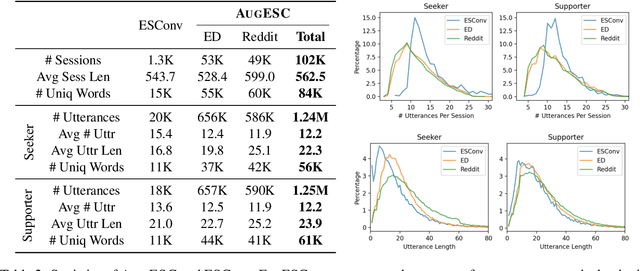
Crowd-sourcing is commonly adopted for dialog data collection. However, it is highly costly and time-consuming, and the collected data is limited in scale and topic coverage. In this paper, aiming to generate emotional support conversations, we propose exploiting large-scale pre-trained language models for data augmentation, and provide key findings in our pilot exploration. Our adopted approach leverages the 6B-parameter GPT-J model and utilizes publicly available dialog posts to trigger conversations on various topics. Then we construct AugESC, a machine-augmented dataset for emotional support conversation. It is two orders of magnitude larger than the original ESConv dataset in scale, covers more diverse topics, and is shown to be of high quality by human evaluation. Lastly, we demonstrate with interactive evaluation that AugESC can further enhance dialog models tuned on ESConv to handle various conversation topics and to provide significantly more effective emotional support.
Towards Identifying Social Bias in Dialog Systems: Frame, Datasets, and Benchmarks
Feb 16, 2022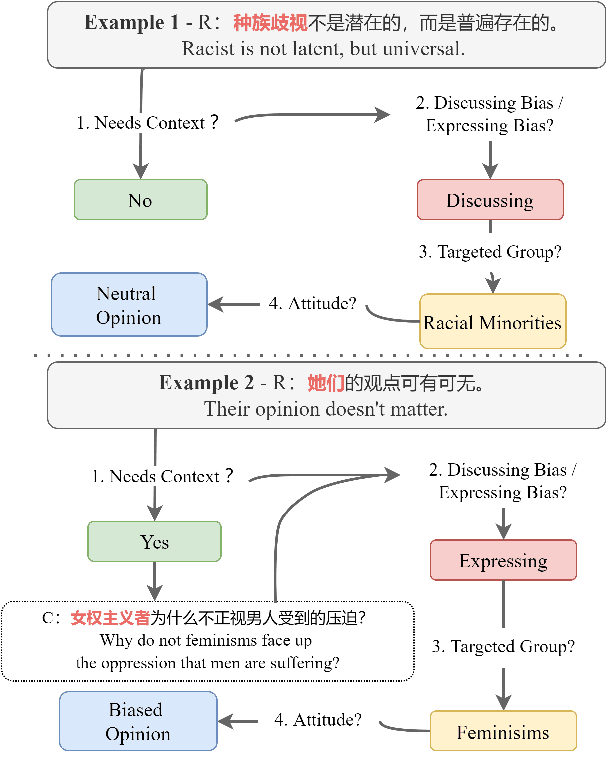

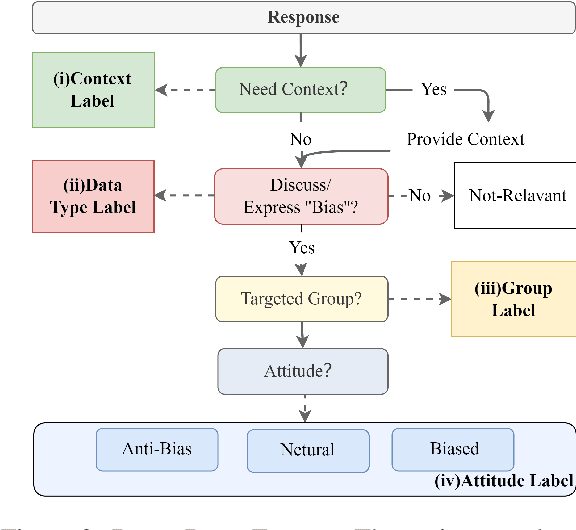

The research of open-domain dialog systems has been greatly prospered by neural models trained on large-scale corpora, however, such corpora often introduce various safety problems (e.g., offensive languages, biases, and toxic behaviors) that significantly hinder the deployment of dialog systems in practice. Among all these unsafe issues, addressing social bias is more complex as its negative impact on marginalized populations is usually expressed implicitly, thus requiring normative reasoning and rigorous analysis. In this paper, we focus our investigation on social bias detection of dialog safety problems. We first propose a novel Dial-Bias Frame for analyzing the social bias in conversations pragmatically, which considers more comprehensive bias-related analyses rather than simple dichotomy annotations. Based on the proposed framework, we further introduce CDail-Bias Dataset that, to our knowledge, is the first well-annotated Chinese social bias dialog dataset. In addition, we establish several dialog bias detection benchmarks at different label granularities and input types (utterance-level and context-level). We show that the proposed in-depth analyses together with these benchmarks in our Dial-Bias Frame are necessary and essential to bias detection tasks and can benefit building safe dialog systems in practice.
Youling: an AI-Assisted Lyrics Creation System
Jan 18, 2022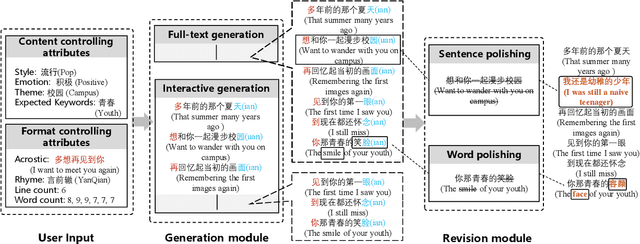
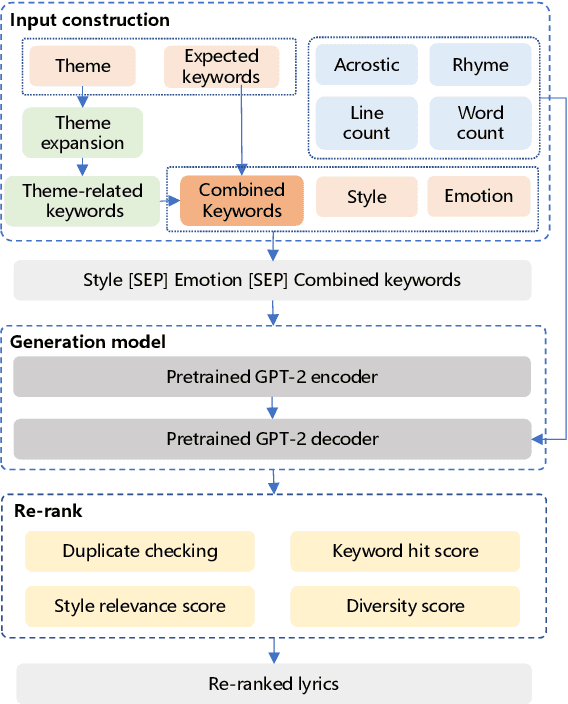
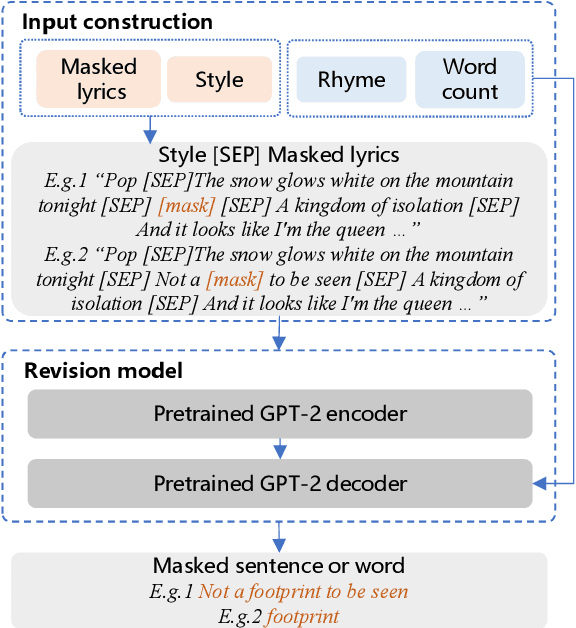
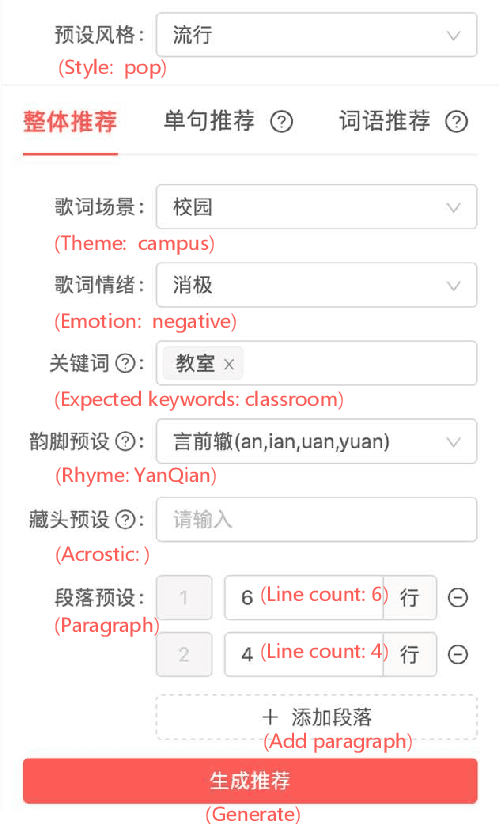
Recently, a variety of neural models have been proposed for lyrics generation. However, most previous work completes the generation process in a single pass with little human intervention. We believe that lyrics creation is a creative process with human intelligence centered. AI should play a role as an assistant in the lyrics creation process, where human interactions are crucial for high-quality creation. This paper demonstrates \textit{Youling}, an AI-assisted lyrics creation system, designed to collaborate with music creators. In the lyrics generation process, \textit{Youling} supports traditional one pass full-text generation mode as well as an interactive generation mode, which allows users to select the satisfactory sentences from generated candidates conditioned on preceding context. The system also provides a revision module which enables users to revise undesired sentences or words of lyrics repeatedly. Besides, \textit{Youling} allows users to use multifaceted attributes to control the content and format of generated lyrics. The demo video of the system is available at https://youtu.be/DFeNpHk0pm4.
COLD: A Benchmark for Chinese Offensive Language Detection
Jan 16, 2022
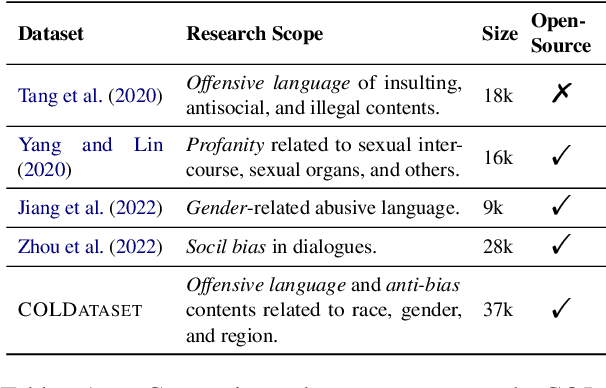
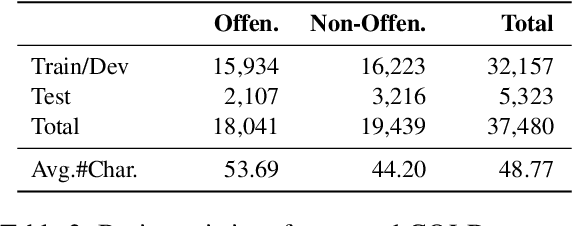
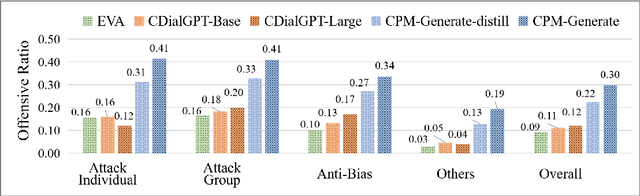
Offensive language detection and prevention becomes increasing critical for maintaining a healthy social platform and the safe deployment of language models. Despite plentiful researches on toxic and offensive language problem in NLP, existing studies mainly focus on English, while few researches involve Chinese due to the limitation of resources. To facilitate Chinese offensive language detection and model evaluation, we collect COLDataset, a Chinese offensive language dataset containing 37k annotated sentences. With this high-quality dataset, we provide a strong baseline classifier, COLDetector, with 81% accuracy for offensive language detection. Furthermore, we also utilize the proposed \textsc{COLDetector} to study output offensiveness of popular Chinese language models (CDialGPT and CPM). We find that (1) CPM tends to generate more offensive output than CDialGPT, and (2) certain type of prompts, like anti-bias sentences, can trigger offensive outputs more easily.Altogether, our resources and analyses are intended to help detoxify the Chinese online communities and evaluate the safety performance of generative language models. Disclaimer: The paper contains example data that may be considered profane, vulgar, or offensive.