 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASC: Metal-Aware Sampling and Correction via Reinforcement Learning for Accelerated MRI
Jan 30, 2026Metal implants in MRI cause severe artifacts that degrade image quality and hinder clinical diagnosis. Traditional approaches address metal artifact reduction (MAR) and accelerated MRI acquisition as separate problems. We propose MASC, a unified reinforcement learning framework that jointly optimizes metal-aware k-space sampling and artifact correction for accelerated MRI. To enable supervised training, we construct a paired MRI dataset using physics-based simulation, generating k-space data and reconstructions for phantoms with and without metal implants. This paired dataset provides simulated 3D MRI scans with and without metal implants, where each metal-corrupted sample has an exactly matched clean reference, enabling direct supervision for both artifact reduction and acquisition policy learning. We formulate active MRI acquisition as a sequential decision-making problem, where an artifact-aware Proximal Policy Optimization (PPO) agent learns to select k-space phase-encoding lines under a limited acquisition budget. The agent operates on undersampled reconstructions processed through a U-Net-based MAR network, learning patterns that maximize reconstruction quality. We further propose an end-to-end training scheme where the acquisition policy learns to select k-space lines that best support artifact removal while the MAR network simultaneously adapts to the resulting undersampling patterns. Experiments demonstrate that MASC's learned policies outperform conventional sampling strategies, and end-to-end training improves performance compared to using a frozen pre-trained MAR network, validating the benefit of joint optimization. Cross-dataset experiments on FastMRI with physics-based artifact simulation further confirm generalization to realistic clinical MRI data. The code and models of MASC have been made publicly available: https://github.com/hrlblab/masc
Reinforced Rate Control for Neural Video Compression via Inter-Frame Rate-Distortion Awareness
Jan 27, 2026Neural video compression (NVC) has demonstrated superior compression efficiency, yet effective rate control remains a significant challenge due to complex temporal dependencies. Existing rate control schemes typically leverage frame content to capture distortion interactions, overlooking inter-frame rate dependencies arising from shifts in per-frame coding parameters. This often leads to suboptimal bitrate allocation and cascading parameter decisions. To address this, we propose a reinforcement-learning (RL)-based rate control framework that formulates the task as a frame-by-frame sequential decision process. At each frame, an RL agent observes a spatiotemporal state and selects coding parameters to optimize a long-term reward that reflects rate-distortion (R-D) performance and bitrate adherence. Unlike prior methods, our approach jointly determines bitrate allocation and coding parameters in a single step, independent of group of pictures (GOP) structure. Extensive experiments across diverse NVC architectures show that our method reduces the average relative bitrate error to 1.20% and achieves up to 13.45% bitrate savings at typical GOP sizes, outperforming existing approaches. In addition, our framework demonstrates improved robustness to content variation and bandwidth fluctuations with lower coding overhead, making it highly suitable for practical deployment.
ResTok: Learning Hierarchical Residuals in 1D Visual Tokenizers for Autoregressive Image Generation
Jan 07, 2026Existing 1D visual tokenizers for autoregressive (AR) generation largely follow the design principles of language modeling, as they are built directly upon transformers whose priors originate in language, yielding single-hierarchy latent tokens and treating visual data as flat sequential token streams. However, this language-like formulation overlooks key properties of vision, particularly the hierarchical and residual network designs that have long been essential for convergence and efficiency in visual models. To bring "vision" back to vision, we propose the Residual Tokenizer (ResTok), a 1D visual tokenizer that builds hierarchical residuals for both image tokens and latent tokens. The hierarchical representations obtained through progressively merging enable cross-level feature fusion at each layer, substantially enhancing representational capacity. Meanwhile, the semantic residuals between hierarchies prevent information overlap, yielding more concentrated latent distributions that are easier for AR modeling. Cross-level bindings consequently emerge without any explicit constraints. To accelerate the generation process, we further introduce a hierarchical AR generator that substantially reduces sampling steps by predicting an entire level of latent tokens at once rather than generating them strictly token-by-token. Extensive experiments demonstrate that restoring hierarchical residual priors in visual tokenization significantly improves AR image generation, achieving a gFID of 2.34 on ImageNet-256 with only 9 sampling steps. Code is available at https://github.com/Kwai-Kolors/ResTok.
ParkGaussian: Surround-view 3D Gaussian Splatting for Autonomous Parking
Jan 04, 2026Parking is a critical task for autonomous driving systems (ADS), with unique challenges in crowded parking slots and GPS-denied environments. However, existing works focus on 2D parking slot perception, mapping, and localization, 3D reconstruction remains underexplored, which is crucial for capturing complex spatial geometry in parking scenarios. Naively improving the visual quality of reconstructed parking scenes does not directly benefit autonomous parking, as the key entry point for parking is the slots perception module. To address these limitations, we curate the first benchmark named ParkRecon3D, specifically designed for parking scene reconstruction. It includes sensor data from four surround-view fisheye cameras with calibrated extrinsics and dense parking slot annotations. We then propose ParkGaussian, the first framework that integrates 3D Gaussian Splatting (3DGS) for parking scene reconstruction. To further improve the alignment between reconstruction and downstream parking slot detection, we introduce a slot-aware reconstruction strategy that leverages existing parking perception methods to enhance the synthesis quality of slot regions. Experiments on ParkRecon3D demonstrate that ParkGaussian achieves state-of-the-art reconstruction quality and better preserves perception consistency for downstream tasks. The code and dataset will be released at: https://github.com/wm-research/ParkGaussian
YODA: Yet Another One-step Diffusion-based Video Compressor
Jan 03, 2026While one-step diffusion models have recently excelled in perceptual image compression, their application to video remains limited. Prior efforts typically rely on pretrained 2D autoencoders that generate per-frame latent representations independently, thereby neglecting temporal dependencies. We present YODA--Yet Another One-step Diffusion-based Video Compressor--which embeds multiscale features from temporal references for both latent generation and latent coding to better exploit spatial-temporal correlations for more compact representation, and employs a linear Diffusion Transformer (DiT) for efficient one-step denoising. YODA achieves state-of-the-art perceptual performance, consistently outperforming traditional and deep-learning baselines on LPIPS, DISTS, FID, and KID. Source code will be publicly available at https://github.com/NJUVISION/YODA.
Neural B-frame Video Compression with Bi-directional Reference Harmonization
Nov 12, 2025Neural video compression (NVC) has made significant progress in recent years, while neural B-frame video compression (NBVC) remains underexplored compared to P-frame compression. NBVC can adopt bi-directional reference frames for better compression performance. However, NBVC's hierarchical coding may complicate continuous temporal prediction, especially at some hierarchical levels with a large frame span, which could cause the contribution of the two reference frames to be unbalanced. To optimize reference information utilization, we propose a novel NBVC method, termed Bi-directional Reference Harmonization Video Compression (BRHVC), with the proposed Bi-directional Motion Converge (BMC) and Bi-directional Contextual Fusion (BCF). BMC converges multiple optical flows in motion compression, leading to more accurate motion compensation on a larger scale. Then BCF explicitly models the weights of reference contexts under the guidance of motion compensation accuracy. With more efficient motions and contexts, BRHVC can effectively harmonize bi-directional references. Experimental results indicate that our BRHVC outperforms previous state-of-the-art NVC methods, even surpassing the traditional coding, VTM-RA (under random access configuration), on the HEVC datasets. The source code is released at https://github.com/kwai/NVC.
StreamKV: Streaming Video Question-Answering with Segment-based KV Cache Retrieval and Compression
Nov 10, 2025



Video Large Language Models (Video-LLMs) have demonstrated significant potential in the areas of video captioning, search, and summarization. However, current Video-LLMs still face challenges with long real-world videos. Recent methods have introduced a retrieval mechanism that retrieves query-relevant KV caches for question answering, enhancing the efficiency and accuracy of long real-world videos. However, the compression and retrieval of KV caches are still not fully explored. In this paper, we propose \textbf{StreamKV}, a training-free framework that seamlessly equips Video-LLMs with advanced KV cache retrieval and compression. Compared to previous methods that used uniform partitioning, StreamKV dynamically partitions video streams into semantic segments, which better preserves semantic information. For KV cache retrieval, StreamKV calculates a summary vector for each segment to retain segment-level information essential for retrieval. For KV cache compression, StreamKV introduces a guidance prompt designed to capture the key semantic elements within each segment, ensuring only the most informative KV caches are retained for answering questions. Moreover, StreamKV unifies KV cache retrieval and compression within a single module, performing both in a layer-adaptive manner, thereby further improving the effectiveness of streaming video question answering. Extensive experiments on public StreamingVQA benchmarks demonstrate that StreamKV significantly outperforms existing Online Video-LLMs, achieving superior accuracy while substantially improving both memory efficiency and computational latency. The code has been released at https://github.com/sou1p0wer/StreamKV.
TimeSearch-R: Adaptive Temporal Search for Long-Form Video Understanding via Self-Verification Reinforcement Learning
Nov 07, 2025Temporal search aims to identify a minimal set of relevant frames from tens of thousands based on a given query, serving as a foundation for accurate long-form video understanding. Existing works attempt to progressively narrow the search space. However, these approaches typically rely on a hand-crafted search process, lacking end-to-end optimization for learning optimal search strategies. In this paper, we propose TimeSearch-R, which reformulates temporal search as interleaved text-video thinking, seamlessly integrating searching video clips into the reasoning process through reinforcement learning (RL). However, applying RL training methods, such as Group Relative Policy Optimization (GRPO), to video reasoning can result in unsupervised intermediate search decisions. This leads to insufficient exploration of the video content and inconsistent logical reasoning. To address these issues, we introduce GRPO with Completeness Self-Verification (GRPO-CSV), which gathers searched video frames from the interleaved reasoning process and utilizes the same policy model to verify the adequacy of searched frames, thereby improving the completeness of video reasoning. Additionally, we construct datasets specifically designed for the SFT cold-start and RL training of GRPO-CSV, filtering out samples with weak temporal dependencies to enhance task difficulty and improve temporal search capabilities. Extensive experiments demonstrate that TimeSearch-R achieves significant improvements on temporal search benchmarks such as Haystack-LVBench and Haystack-Ego4D, as well as long-form video understanding benchmarks like VideoMME and MLVU. Notably, TimeSearch-R establishes a new state-of-the-art on LongVideoBench with 4.1% improvement over the base model Qwen2.5-VL and 2.0% over the advanced video reasoning model Video-R1. Our code is available at https://github.com/Time-Search/TimeSearch-R.
Jarvis: Towards Personalized AI Assistant via Personal KV-Cache Retrieval
Oct 26, 2025


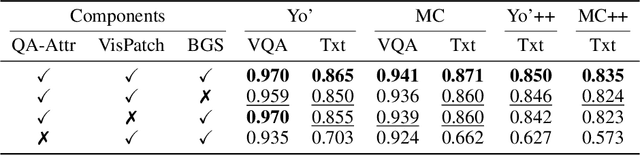
The rapid development of Vision-language models (VLMs) enables open-ended perception and reasoning. Recent works have started to investigate how to adapt general-purpose VLMs into personalized assistants. Even commercial models such as ChatGPT now support model personalization by incorporating user-specific information. However, existing methods either learn a set of concept tokens or train a VLM to utilize user-specific information. However, both pipelines struggle to generate accurate answers as personalized assistants. We introduce Jarvis, an innovative framework for a personalized AI assistant through personal KV-Cache retrieval, which stores user-specific information in the KV-Caches of both textual and visual tokens. The textual tokens are created by summarizing user information into metadata, while the visual tokens are produced by extracting distinct image patches from the user's images. When answering a question, Jarvis first retrieves related KV-Caches from personal storage and uses them to ensure accuracy in responses. We also introduce a fine-grained benchmark built with the same distinct image patch mining pipeline, emphasizing accurate question answering based on fine-grained user-specific information. Jarvis is capable of providing more accurate responses, particularly when they depend on specific local details. Jarvis achieves state-of-the-art results in both visual question answering and text-only tasks across multiple datasets, indicating a practical path toward personalized AI assistants. The code and dataset will be released.
Rethinking Driving World Model as Synthetic Data Generator for Perception Tasks
Oct 22, 2025Recent advancements in driving world models enable controllable generation of high-quality RGB videos or multimodal videos. Existing methods primarily focus on metrics related to generation quality and controllability. However, they often overlook the evaluation of downstream perception tasks, which are $\mathbf{really\ crucial}$ for the performance of autonomous driving. Existing methods usually leverage a training strategy that first pretrains on synthetic data and finetunes on real data, resulting in twice the epochs compared to the baseline (real data only). When we double the epochs in the baseline, the benefit of synthetic data becomes negligible. To thoroughly demonstrate the benefit of synthetic data, we introduce Dream4Drive, a novel synthetic data generation framework designed for enhancing the downstream perception tasks. Dream4Drive first decomposes the input video into several 3D-aware guidance maps and subsequently renders the 3D assets onto these guidance maps. Finally, the driving world model is fine-tuned to produce the edited, multi-view photorealistic videos, which can be used to train the downstream perception models. Dream4Drive enables unprecedented flexibility in generating multi-view corner cases at scale, significantly boosting corner case perception in autonomous driving. To facilitate future research, we also contribute a large-scale 3D asset dataset named DriveObj3D, covering the typical categories in driving scenarios and enabling diverse 3D-aware video editing. We conduct comprehensive experiments to show that Dream4Drive can effectively boost the performance of downstream perception models under various training epochs. Project: $\href{https://wm-research.github.io/Dream4Drive/}{this\ https\ URL}$