 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Skills Should Go Beyond Text: The Case for Visual Skills
May 31, 2026Reusable skills are a key mechanism for extending agent capabilities, allowing agents to accumulate experience and solve increasingly complex tasks. Yet most existing skill-learning methods store reusable experience as text-only assets, such as instructions, reasoning traces, or summarized trajectories. We argue that this text-only paradigm creates a fundamental bottleneck for visual-centric tasks, where reusable knowledge often depends on spatial layout, visual grounding, fine-grained appearance, and localized state changes. To address this limitation, we propose \textbf{\NAME}, a multimodal skill paradigm that combines declarative textual logic with explicit visual support. We distinguish three reusable forms: static priors for stable spatial conventions, dynamic priors for in-situ visual working memory, and interleaved visual skills that bind ordered text steps to the source frames, screenshots, or page regions that justify them. Rather than only describing what to do, visual skills also encode where to look, how to inspect, and how to verify visual outcomes. To scale visual-skill construction, we introduce \textbf{\SYSTEM}, an automatic system that converts agent experience into reusable multimodal skills by preserving textual reasoning, spatial references, visual boundaries, and interaction patterns from task trajectories. Experiments on GUI and other visual-centric tasks show that visual skills consistently outperform text-only skills, particularly when success requires spatial correspondence, visual evidence, and state-aware interaction. These results support our central position: reusable agent skills should go beyond text and become multimodal assets for future multimodal agents.
AD-MIR: Bridging the Gap from Perception to Persuasion in Advertising Video Understanding via Structured Reasoning
Feb 07, 2026Multimodal understanding of advertising videos is essential for interpreting the intricate relationship between visual storytelling and abstract persuasion strategies. However, despite excelling at general search, existing agents often struggle to bridge the cognitive gap between pixel-level perception and high-level marketing logic. To address this challenge, we introduce AD-MIR, a framework designed to decode advertising intent via a two-stage architecture. First, in the Structure-Aware Memory Construction phase, the system converts raw video into a structured database by integrating semantic retrieval with exact keyword matching. This approach prioritizes fine-grained brand details (e.g., logos, on-screen text) while dynamically filtering out irrelevant background noise to isolate key protagonists. Second, the Structured Reasoning Agent mimics a marketing expert through an iterative inquiry loop, decomposing the narrative to deduce implicit persuasion tactics. Crucially, it employs an evidence-based self-correction mechanism that rigorously validates these insights against specific video frames, automatically backtracking when visual support is lacking. Evaluation on the AdsQA benchmark demonstrates that AD-MIR achieves state-of-the-art performance, surpassing the strongest general-purpose agent, DVD, by 1.8% in strict and 9.5% in relaxed accuracy. These results underscore that effective advertising understanding demands explicitly grounding abstract marketing strategies in pixel-level evidence. The code is available at https://github.com/Little-Fridge/AD-MIR.
M2A: Multimodal Memory Agent with Dual-Layer Hybrid Memory for Long-Term Personalized Interactions
Feb 07, 2026This work addresses the challenge of personalized question answering in long-term human-machine interactions: when conversational history spans weeks or months and exceeds the context window, existing personalization mechanisms struggle to continuously absorb and leverage users' incremental concepts, aliases, and preferences. Current personalized multimodal models are predominantly static-concepts are fixed at initialization and cannot evolve during interactions. We propose M2A, an agentic dual-layer hybrid memory system that maintains personalized multimodal information through online updates. The system employs two collaborative agents: ChatAgent manages user interactions and autonomously decides when to query or update memory, while MemoryManager breaks down memory requests from ChatAgent into detailed operations on the dual-layer memory bank, which couples a RawMessageStore (immutable conversation log) with a SemanticMemoryStore (high-level observations), providing memories at different granularities. In addition, we develop a reusable data synthesis pipeline that injects concept-grounded sessions from Yo'LLaVA and MC-LLaVA into LoCoMo long conversations while preserving temporal coherence. Experiments show that M2A significantly outperforms baselines, demonstrating that transforming personalization from one-shot configuration to a co-evolving memory mechanism provides a viable path for high-quality individualized responses in long-term multimodal interactions. The code is available at https://github.com/Little-Fridge/M2A.
Jarvis: Towards Personalized AI Assistant via Personal KV-Cache Retrieval
Oct 26, 2025


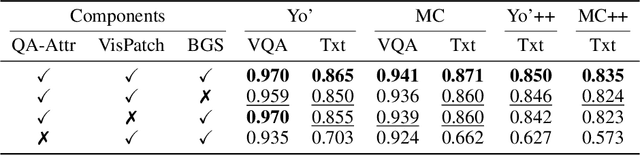
The rapid development of Vision-language models (VLMs) enables open-ended perception and reasoning. Recent works have started to investigate how to adapt general-purpose VLMs into personalized assistants. Even commercial models such as ChatGPT now support model personalization by incorporating user-specific information. However, existing methods either learn a set of concept tokens or train a VLM to utilize user-specific information. However, both pipelines struggle to generate accurate answers as personalized assistants. We introduce Jarvis, an innovative framework for a personalized AI assistant through personal KV-Cache retrieval, which stores user-specific information in the KV-Caches of both textual and visual tokens. The textual tokens are created by summarizing user information into metadata, while the visual tokens are produced by extracting distinct image patches from the user's images. When answering a question, Jarvis first retrieves related KV-Caches from personal storage and uses them to ensure accuracy in responses. We also introduce a fine-grained benchmark built with the same distinct image patch mining pipeline, emphasizing accurate question answering based on fine-grained user-specific information. Jarvis is capable of providing more accurate responses, particularly when they depend on specific local details. Jarvis achieves state-of-the-art results in both visual question answering and text-only tasks across multiple datasets, indicating a practical path toward personalized AI assistants. The code and dataset will be released.
Small-Large Collaboration: Training-efficient Concept Personalization for Large VLM using a Meta Personalized Small VLM
Aug 10, 2025



Personalizing Vision-Language Models (VLMs) to transform them into daily assistants has emerged as a trending research direction. However, leading companies like OpenAI continue to increase model size and develop complex designs such as the chain of thought (CoT). While large VLMs are proficient in complex multi-modal understanding, their high training costs and limited access via paid APIs restrict direct personalization. Conversely, small VLMs are easily personalized and freely available, but they lack sufficient reasoning capabilities. Inspired by this, we propose a novel collaborative framework named Small-Large Collaboration (SLC) for large VLM personalization, where the small VLM is responsible for generating personalized information, while the large model integrates this personalized information to deliver accurate responses. To effectively incorporate personalized information, we develop a test-time reflection strategy, preventing the potential hallucination of the small VLM. Since SLC only needs to train a meta personalized small VLM for the large VLMs, the overall process is training-efficient. To the best of our knowledge, this is the first training-efficient framework that supports both open-source and closed-source large VLMs, enabling broader real-world personalized applications. We conduct thorough experiments across various benchmarks and large VLMs to demonstrate the effectiveness of the proposed SLC framework. The code will be released at https://github.com/Hhankyangg/SLC.