 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJarvis: Towards Personalized AI Assistant via Personal KV-Cache Retrieval
Paper and Code
Oct 26, 2025


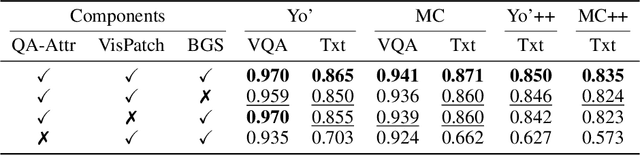
The rapid development of Vision-language models (VLMs) enables open-ended perception and reasoning. Recent works have started to investigate how to adapt general-purpose VLMs into personalized assistants. Even commercial models such as ChatGPT now support model personalization by incorporating user-specific information. However, existing methods either learn a set of concept tokens or train a VLM to utilize user-specific information. However, both pipelines struggle to generate accurate answers as personalized assistants. We introduce Jarvis, an innovative framework for a personalized AI assistant through personal KV-Cache retrieval, which stores user-specific information in the KV-Caches of both textual and visual tokens. The textual tokens are created by summarizing user information into metadata, while the visual tokens are produced by extracting distinct image patches from the user's images. When answering a question, Jarvis first retrieves related KV-Caches from personal storage and uses them to ensure accuracy in responses. We also introduce a fine-grained benchmark built with the same distinct image patch mining pipeline, emphasizing accurate question answering based on fine-grained user-specific information. Jarvis is capable of providing more accurate responses, particularly when they depend on specific local details. Jarvis achieves state-of-the-art results in both visual question answering and text-only tasks across multiple datasets, indicating a practical path toward personalized AI assistants. The code and dataset will be released.