 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventGPT: Event Stream Understanding with Multimodal Large Language Models
Dec 01, 2024



Event cameras record visual information as asynchronous pixel change streams, excelling at scene perception under unsatisfactory lighting or high-dynamic conditions. Existing multimodal large language models (MLLMs) concentrate on natural RGB images, failing in scenarios where event data fits better. In this paper, we introduce EventGPT, the first MLLM for event stream understanding, to the best of our knowledge, marking a pioneering attempt to integrate large language models (LLMs) with event stream comprehension. To mitigate the huge domain gaps, we develop a three-stage optimization paradigm to gradually equip a pre-trained LLM with the capability of understanding event-based scenes. Our EventGPT comprises an event encoder, followed by a spatio-temporal aggregator, a linear projector, an event-language adapter, and an LLM. Firstly, RGB image-text pairs generated by GPT are leveraged to warm up the linear projector, referring to LLaVA, as the gap between natural image and language modalities is relatively smaller. Secondly, we construct a synthetic yet large dataset, N-ImageNet-Chat, consisting of event frames and corresponding texts to enable the use of the spatio-temporal aggregator and to train the event-language adapter, thereby aligning event features more closely with the language space. Finally, we gather an instruction dataset, Event-Chat, which contains extensive real-world data to fine-tune the entire model, further enhancing its generalization ability. We construct a comprehensive benchmark, and experiments show that EventGPT surpasses previous state-of-the-art MLLMs in generation quality, descriptive accuracy, and reasoning capability.
A Comprehensive Guide to Explainable AI: From Classical Models to LLMs
Dec 01, 2024



Explainable Artificial Intelligence (XAI) addresses the growing need for transparency and interpretability in AI systems, enabling trust and accountability in decision-making processes. This book offers a comprehensive guide to XAI, bridging foundational concepts with advanced methodologies. It explores interpretability in traditional models such as Decision Trees, Linear Regression, and Support Vector Machines, alongside the challenges of explaining deep learning architectures like CNNs, RNNs, and Large Language Models (LLMs), including BERT, GPT, and T5. The book presents practical techniques such as SHAP, LIME, Grad-CAM, counterfactual explanations, and causal inference, supported by Python code examples for real-world applications. Case studies illustrate XAI's role in healthcare, finance, and policymaking, demonstrating its impact on fairness and decision support. The book also covers evaluation metrics for explanation quality, an overview of cutting-edge XAI tools and frameworks, and emerging research directions, such as interpretability in federated learning and ethical AI considerations. Designed for a broad audience, this resource equips readers with the theoretical insights and practical skills needed to master XAI. Hands-on examples and additional resources are available at the companion GitHub repository: https://github.com/Echoslayer/XAI_From_Classical_Models_to_LLMs.
EFTViT: Efficient Federated Training of Vision Transformers with Masked Images on Resource-Constrained Edge Devices
Nov 30, 2024



Federated learning research has recently shifted from Convolutional Neural Networks (CNNs) to Vision Transformers (ViTs) due to their superior capacity. ViTs training demands higher computational resources due to the lack of 2D inductive biases inherent in CNNs. However, efficient federated training of ViTs on resource-constrained edge devices remains unexplored in the community. In this paper, we propose EFTViT, a hierarchical federated framework that leverages masked images to enable efficient, full-parameter training on resource-constrained edge devices, offering substantial benefits for learning on heterogeneous data. In general, we patchify images and randomly mask a portion of the patches, observing that excluding them from training has minimal impact on performance while substantially reducing computation costs and enhancing data content privacy protection. Specifically, EFTViT comprises a series of lightweight local modules and a larger global module, updated independently on clients and the central server, respectively. The local modules are trained on masked image patches, while the global module is trained on intermediate patch features uploaded from the local client, balanced through a proposed median sampling strategy to erase client data distribution privacy. We analyze the computational complexity and privacy protection of EFTViT. Extensive experiments on popular benchmarks show that EFTViT achieves up to 28.17% accuracy improvement, reduces local training computational cost by up to 2.8$\times$, and cuts local training time by up to 4.4$\times$ compared to existing methods.
Disentangling the Complex Multiplexed DIA Spectra in De Novo Peptide Sequencing
Nov 24, 2024Data-Independent Acquisition (DIA) was introduced to improve sensitivity to cover all peptides in a range rather than only sampling high-intensity peaks as in Data-Dependent Acquisition (DDA) mass spectrometry. However, it is not very clear how useful DIA data is for de novo peptide sequencing as the DIA data are marred with coeluted peptides, high noises, and varying data quality. We present a new deep learning method DIANovo, and address each of these difficulties, and improves the previous established system DeepNovo-DIA by from 25% to 81%, averaging 48%, for amino acid recall, and by from 27% to 89%, averaging 57%, for peptide recall, by equipping the model with a deeper understanding of coeluted DIA spectra. This paper also provides criteria about when DIA data could be used for de novo peptide sequencing and when not to by providing a comparison between DDA and DIA, in both de novo and database search mode. We find that while DIA excels with narrow isolation windows on older-generation instruments, it loses its advantage with wider windows. However, with Orbitrap Astral, DIA consistently outperforms DDA due to narrow window mode enabled. We also provide a theoretical explanation of this phenomenon, emphasizing the critical role of the signal-to-noise profile in the successful application of de novo sequencing.
Sequence-to-Sequence Neural Diarization with Automatic Speaker Detection and Representation
Nov 21, 2024This paper proposes a novel Sequence-to-Sequence Neural Diarization (SSND) framework to perform online and offline speaker diarization. It is developed from the sequence-to-sequence architecture of our previous target-speaker voice activity detection system and then evolves into a new diarization paradigm by addressing two critical problems. 1) Speaker Detection: The proposed approach can utilize incompletely given speaker embeddings to discover the unknown speaker and predict the target voice activities in the audio signal. It does not require a prior diarization system for speaker enrollment in advance. 2) Speaker Representation: The proposed approach can adopt the predicted voice activities as reference information to extract speaker embeddings from the audio signal simultaneously. The representation space of speaker embedding is jointly learned within the whole diarization network without using an extra speaker embedding model. During inference, the SSND framework can process long audio recordings blockwise. The detection module utilizes the previously obtained speaker-embedding buffer to predict both enrolled and unknown speakers' voice activities for each coming audio block. Next, the speaker-embedding buffer is updated according to the predictions of the representation module. Assuming that up to one new speaker may appear in a small block shift, our model iteratively predicts the results of each block and extracts target embeddings for the subsequent blocks until the signal ends. Finally, the last speaker-embedding buffer can re-score the entire audio, achieving highly accurate diarization performance as an offline system. (......)
MARM: Unlocking the Future of Recommendation Systems through Memory Augmentation and Scalable Complexity
Nov 14, 2024



Scaling-law has guided the language model designing for past years, however, it is worth noting that the scaling laws of NLP cannot be directly applied to RecSys due to the following reasons: (1) The amount of training samples and model parameters is typically not the bottleneck for the model. Our recommendation system can generate over 50 billion user samples daily, and such a massive amount of training data can easily allow our model parameters to exceed 200 billion, surpassing many LLMs (about 100B). (2) To ensure the stability and robustness of the recommendation system, it is essential to control computational complexity FLOPs carefully. Considering the above differences with LLM, we can draw a conclusion that: for a RecSys model, compared to model parameters, the computational complexity FLOPs is a more expensive factor that requires careful control. In this paper, we propose our milestone work, MARM (Memory Augmented Recommendation Model), which explores a new cache scaling-laws successfully.
Script-centric behavior understanding for assisted autism spectrum disorder diagnosis
Nov 14, 2024



Observing and analyzing children's social behaviors is crucial for the early diagnosis of Autism Spectrum Disorders (ASD). This work focuses on automatically detecting ASD using computer vision techniques and large language models (LLMs). Existing methods typically rely on supervised learning. However, the scarcity of ASD diagnostic datasets and the lack of interpretability in diagnostic results significantly limits its clinical application. To address these challenges, we introduce a novel unsupervised approach based on script-centric behavior understanding. Our pipeline converts video content into scripts that describe the behavior of characters, leveraging the generalizability of large language models to detect ASD in a zero-shot or few-shot manner. Specifically, we propose a scripts transcription module for multimodal behavior data textualization and a domain prompts module to bridge LLMs. Our method achieves an accuracy of 92.00\% in diagnosing ASD in children with an average age of 24 months, surpassing the performance of supervised learning methods by 3.58\% absolutely. Extensive experiments confirm the effectiveness of our approach and suggest its potential for advancing ASD research through LLMs.
Layer-Wise Feature Metric of Semantic-Pixel Matching for Few-Shot Learning
Nov 10, 2024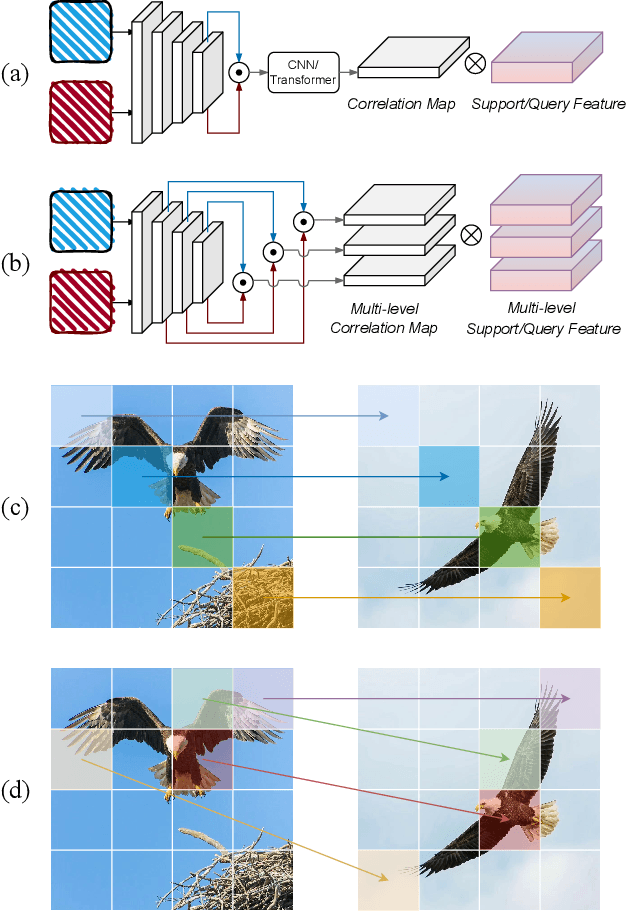
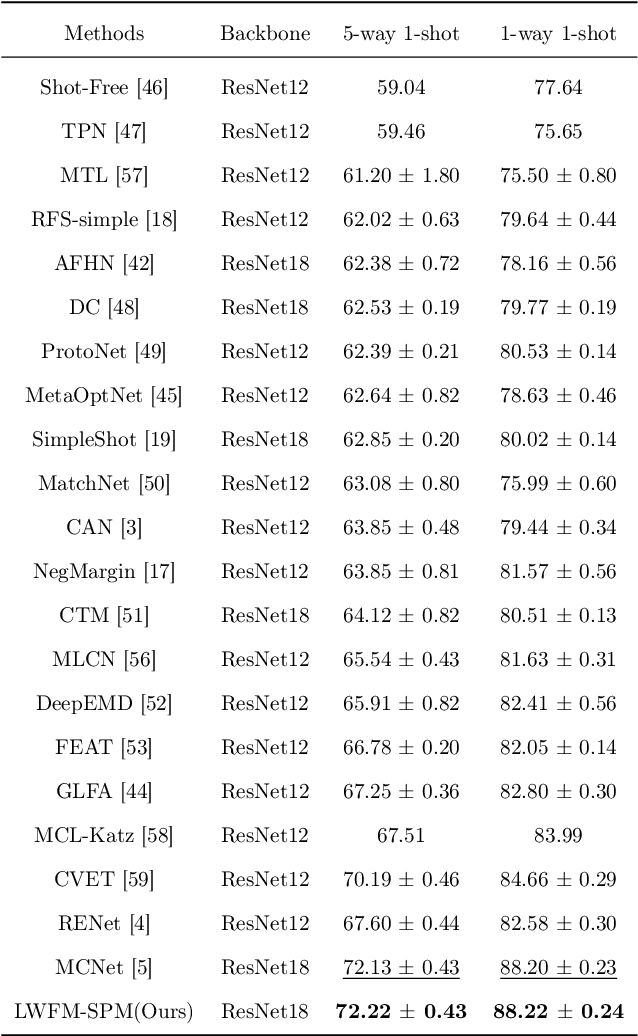
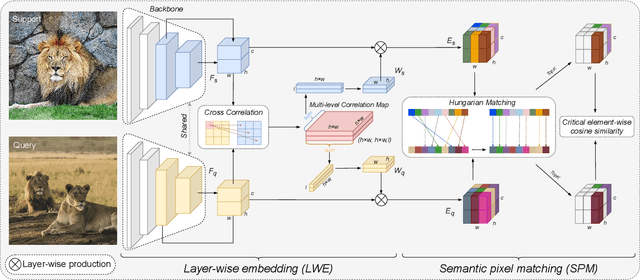
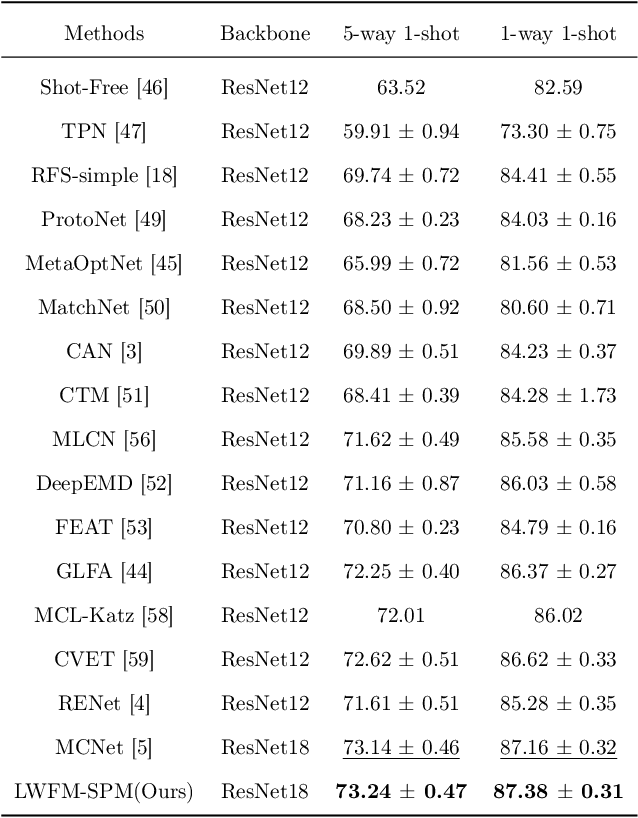
In Few-Shot Learning (FSL), traditional metric-based approaches often rely on global metrics to compute similarity. However, in natural scenes, the spatial arrangement of key instances is often inconsistent across images. This spatial misalignment can result in mismatched semantic pixels, leading to inaccurate similarity measurements. To address this issue, we propose a novel method called the Layer-Wise Features Metric of Semantic-Pixel Matching (LWFM-SPM) to make finer comparisons. Our method enhances model performance through two key modules: (1) the Layer-Wise Embedding (LWE) Module, which refines the cross-correlation of image pairs to generate well-focused feature maps for each layer; (2)the Semantic-Pixel Matching (SPM) Module, which aligns critical pixels based on semantic embeddings using an assignment algorithm. We conducted extensive experiments to evaluate our method on four widely used few-shot classification benchmarks: miniImageNet, tieredImageNet, CUB-200-2011, and CIFAR-FS. The results indicate that LWFM-SPM achieves competitive performance across these benchmarks. Our code will be publicly available on https://github.com/Halo2Tang/Code-for-LWFM-SPM.
Research on reinforcement learning based warehouse robot navigation algorithm in complex warehouse layout
Nov 09, 2024



In this paper, how to efficiently find the optimal path in complex warehouse layout and make real-time decision is a key problem. This paper proposes a new method of Proximal Policy Optimization (PPO) and Dijkstra's algorithm, Proximal policy-Dijkstra (PP-D). PP-D method realizes efficient strategy learning and real-time decision making through PPO, and uses Dijkstra algorithm to plan the global optimal path, thus ensuring high navigation accuracy and significantly improving the efficiency of path planning. Specifically, PPO enables robots to quickly adapt and optimize action strategies in dynamic environments through its stable policy updating mechanism. Dijkstra's algorithm ensures global optimal path planning in static environment. Finally, through the comparison experiment and analysis of the proposed framework with the traditional algorithm, the results show that the PP-D method has significant advantages in improving the accuracy of navigation prediction and enhancing the robustness of the system. Especially in complex warehouse layout, PP-D method can find the optimal path more accurately and reduce collision and stagnation. This proves the reliability and effectiveness of the robot in the study of complex warehouse layout navigation algorithm.
Multi-Reward as Condition for Instruction-based Image Editing
Nov 06, 2024
High-quality training triplets (instruction, original image, edited image) are essential for instruction-based image editing. Predominant training datasets (e.g., InsPix2Pix) are created using text-to-image generative models (e.g., Stable Diffusion, DALL-E) which are not trained for image editing. Accordingly, these datasets suffer from inaccurate instruction following, poor detail preserving, and generation artifacts. In this paper, we propose to address the training data quality issue with multi-perspective reward data instead of refining the ground-truth image quality. 1) we first design a quantitative metric system based on best-in-class LVLM (Large Vision Language Model), i.e., GPT-4o in our case, to evaluate the generation quality from 3 perspectives, namely, instruction following, detail preserving, and generation quality. For each perspective, we collected quantitative score in $0\sim 5$ and text descriptive feedback on the specific failure points in ground-truth edited images, resulting in a high-quality editing reward dataset, i.e., RewardEdit20K. 2) We further proposed a novel training framework to seamlessly integrate the metric output, regarded as multi-reward, into editing models to learn from the imperfect training triplets. During training, the reward scores and text descriptions are encoded as embeddings and fed into both the latent space and the U-Net of the editing models as auxiliary conditions. During inference, we set these additional conditions to the highest score with no text description for failure points, to aim at the best generation outcome. Experiments indicate that our multi-reward conditioned model outperforms its no-reward counterpart on two popular editing pipelines, i.e., InsPix2Pix and SmartEdit. The code and dataset will be released.