 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentX: Towards Agent-Driven Self-Iteration of Industrial Recommender Systems
Jun 25, 2026Recommendation algorithm iteration is moving from an artisanal, engineer-bound process toward an industrialized research loop, but this transition remains blocked by a structural execution bottleneck: the idea-to-launch cycle still depends on human engineers to generate hypotheses, modify production code, launch A/B experiments, and attribute online results. Innovation therefore scales linearly with headcount rather than compounding with evidence, compute, and accumulated experimental knowledge. We present AgentX, a production-deployed multi-agent system that fundamentally restructures this production function. AgentX operates as a self-evolving development engine: it autonomously generates, implements, evaluates, and learns from recommendation experiments at a scale and pace that no manual workflow can sustain. The system orchestrates four tightly coupled stages in a closed loop. A Brainstorm Agent synthesizes evidence from historical experiments, system architecture, data analysis, and external research into ranked, executable proposals. A Developing Agent translates each proposal into production-ready code through repository-grounded generation and multi-dimensional reliability verification. An Evaluation Agent conducts safe online rollout with guardrail-vetoed A/B judgment, converting both successes and failures into structured knowledge assets. A Harness Evolution layer (SGPO) then distills execution trajectories into semantic-gradient updates that continuously sharpen the agents themselves -- making the system not merely automated, but self-improving.
OneReason Technical Report
Jun 04, 2026Generative recommendation models in the OneRec family have been widely deployed in many real-world services, such as short-video, live-streaming, advertising, and e-commerce. However, these generative models can only benefit from the scaling advantage, while their reasoning ability is hard to activate, since we cannot construct meaningful Chain-of-Thought (CoT) sequences consisting of itemic tokens only. Inspired by the success of the reasoning-style ``think before answer'' paradigm in the LLM field, we conduct preliminary studies (i.e., OneRec-Think, OpenOneRec) to explore reasoning capability in generative recommendation. Nevertheless, we notice an unexpected phenomenon: the thinking mode does not show advantages over the non-thinking mode. Drawing insights from recent findings on CoT robustness in multi-modal language models, we argue that effective reasoning in recommendation rests on two factors: perception, the ability to ground itemic tokens in their underlying language semantics, and cognition, the ability to reorganize a user's behavior sequence into coherent latent interest points. We therefore propose OneReason, which includes: (1) strong itemic token perception in pre-training, (2) a three-level cognition-enhanced CoT format for recommendation tasks in SFT, and (3) a specialize-then-unify training recipe in RL to enhance the thinking ability.
CAPTS: Channel-Aware, Preference-Aligned Trigger Selection for Multi-Channel Item-to-Item Retrieval
Feb 13, 2026Large-scale industrial recommender systems commonly adopt multi-channel retrieval for candidate generation, combining direct user-to-item (U2I) retrieval with two-hop user-to-item-to-item (U2I2I) pipelines. In U2I2I, the system selects a small set of historical interactions as triggers to seed downstream item-to-item (I2I) retrieval across multiple channels. In production, triggers are often selected using rule-based policies or learned scorers and tuned in a channel-by-channel manner. However, these practices face two persistent challenges: biased value attribution that values triggers by on-trigger feedback rather than their downstream utility as retrieval seeds, and uncoordinated multi-channel routing where channels select triggers independently under a shared quota, increasing cross-channel overlap. To address these challenges, we propose Channel-Aware, Preference-Aligned Trigger Selection (CAPTS), a unified and flexible framework that treats multi-channel trigger selection as a learnable routing problem. CAPTS introduces a Value Attribution Module (VAM) that provides look-ahead supervision by crediting each trigger with the subsequent engagement generated by items retrieved from it on each I2I channel, and a Channel-Adaptive Trigger Routing (CATR) module that coordinates trigger-to-channel assignment to maximize the overall value of multi-channel retrieval. Extensive offline experiments and large-scale online A/B tests on Kwai, Kuaishou's international short-video platform, show that CAPTS consistently improves multi-channel recall offline and delivers a +0.351% lift in average time spent per device online.
SARM: LLM-Augmented Semantic Anchor for End-to-End Live-Streaming Ranking
Feb 10, 2026Large-scale live-streaming recommendation requires precise modeling of non-stationary content semantics under strict real-time serving constraints. In industrial deployment, two common approaches exhibit fundamental limitations: discrete semantic abstractions sacrifice descriptive precision through clustering, while dense multimodal embeddings are extracted independently and remain weakly aligned with ranking optimization, limiting fine-grained content-aware ranking. To address these limitations, we propose \textbf{SARM}, an end-to-end ranking architecture that integrates natural-language semantic anchors directly into ranking optimization, enabling fine-grained author representations conditioned on multimodal content. Each semantic anchor is represented as learnable text tokens jointly optimized with ranking features, allowing the model to adapt content descriptions to ranking objectives. A lightweight dual-token gated design captures domain-specific live-streaming semantics, while an asymmetric deployment strategy preserves low-latency online training and serving. Extensive offline evaluation and large-scale A/B tests show consistent improvements over production baselines. SARM is fully deployed and serves over 400 million users daily.
SheetBrain: A Neuro-Symbolic Agent for Accurate Reasoning over Complex and Large Spreadsheets
Oct 22, 2025Understanding and reasoning over complex spreadsheets remain fundamental challenges for large language models (LLMs), which often struggle with accurately capturing the complex structure of tables and ensuring reasoning correctness. In this work, we propose SheetBrain, a neuro-symbolic dual workflow agent framework designed for accurate reasoning over tabular data, supporting both spreadsheet question answering and manipulation tasks. SheetBrain comprises three core modules: an understanding module, which produces a comprehensive overview of the spreadsheet - including sheet summary and query-based problem insight to guide reasoning; an execution module, which integrates a Python sandbox with preloaded table-processing libraries and an Excel helper toolkit for effective multi-turn reasoning; and a validation module, which verifies the correctness of reasoning and answers, triggering re-execution when necessary. We evaluate SheetBrain on multiple public tabular QA and manipulation benchmarks, and introduce SheetBench, a new benchmark targeting large, multi-table, and structurally complex spreadsheets. Experimental results show that SheetBrain significantly improves accuracy on both existing benchmarks and the more challenging scenarios presented in SheetBench. Our code is publicly available at https://github.com/microsoft/SheetBrain.
Light as Deception: GPT-driven Natural Relighting Against Vision-Language Pre-training Models
May 30, 2025While adversarial attacks on vision-and-language pretraining (VLP) models have been explored, generating natural adversarial samples crafted through realistic and semantically meaningful perturbations remains an open challenge. Existing methods, primarily designed for classification tasks, struggle when adapted to VLP models due to their restricted optimization spaces, leading to ineffective attacks or unnatural artifacts. To address this, we propose \textbf{LightD}, a novel framework that generates natural adversarial samples for VLP models via semantically guided relighting. Specifically, LightD leverages ChatGPT to propose context-aware initial lighting parameters and integrates a pretrained relighting model (IC-light) to enable diverse lighting adjustments. LightD expands the optimization space while ensuring perturbations align with scene semantics. Additionally, gradient-based optimization is applied to the reference lighting image to further enhance attack effectiveness while maintaining visual naturalness. The effectiveness and superiority of the proposed LightD have been demonstrated across various VLP models in tasks such as image captioning and visual question answering.
MARM: Unlocking the Future of Recommendation Systems through Memory Augmentation and Scalable Complexity
Nov 14, 2024



Scaling-law has guided the language model designing for past years, however, it is worth noting that the scaling laws of NLP cannot be directly applied to RecSys due to the following reasons: (1) The amount of training samples and model parameters is typically not the bottleneck for the model. Our recommendation system can generate over 50 billion user samples daily, and such a massive amount of training data can easily allow our model parameters to exceed 200 billion, surpassing many LLMs (about 100B). (2) To ensure the stability and robustness of the recommendation system, it is essential to control computational complexity FLOPs carefully. Considering the above differences with LLM, we can draw a conclusion that: for a RecSys model, compared to model parameters, the computational complexity FLOPs is a more expensive factor that requires careful control. In this paper, we propose our milestone work, MARM (Memory Augmented Recommendation Model), which explores a new cache scaling-laws successfully.
Inferring Tabular Analysis Metadata by Infusing Distribution and Knowledge Information
Sep 02, 2022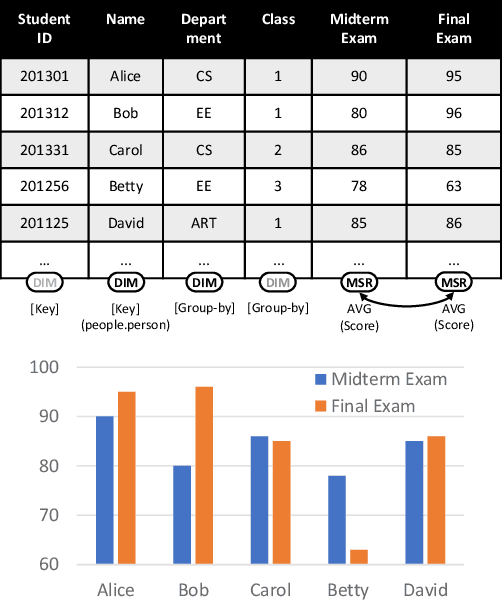
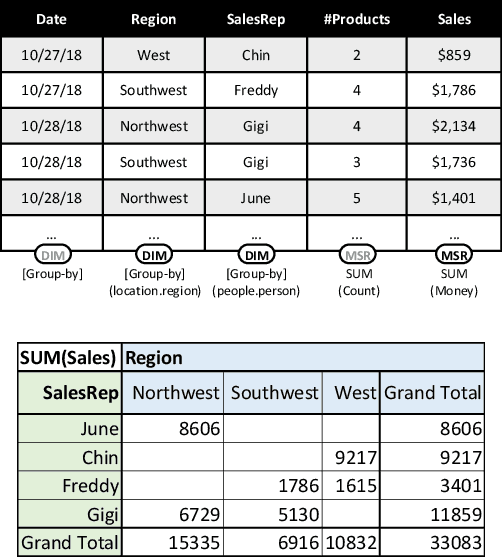
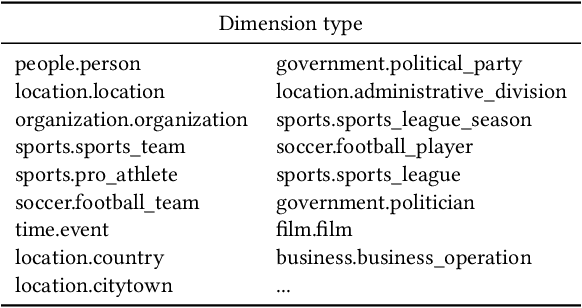
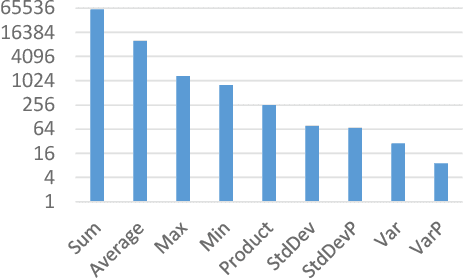
Many data analysis tasks heavily rely on a deep understanding of tables (multi-dimensional data). Across the tasks, there exist comonly used metadata attributes of table fields / columns. In this paper, we identify four such analysis metadata: Measure/dimension dichotomy, common field roles, semantic field type, and default aggregation function. While those metadata face challenges of insufficient supervision signals, utilizing existing knowledge and understanding distribution. To inference these metadata for a raw table, we propose our multi-tasking Metadata model which fuses field distribution and knowledge graph information into pre-trained tabular models. For model training and evaluation, we collect a large corpus (~582k tables from private spreadsheet and public tabular datasets) of analysis metadata by using diverse smart supervisions from downstream tasks. Our best model has accuracy = 98%, hit rate at top-1 > 67%, accuracy > 80%, and accuracy = 88% for the four analysis metadata inference tasks, respectively. It outperforms a series of baselines that are based on rules, traditional machine learning methods, and pre-trained tabular models. Analysis metadata models are deployed in a popular data analysis product, helping downstream intelligent features such as insights mining, chart / pivot table recommendation, and natural language QA...