 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerIPO: Cultivating Long Reasoning in Video-LLMs via Verifier-Gudied Iterative Policy Optimization
May 25, 2025


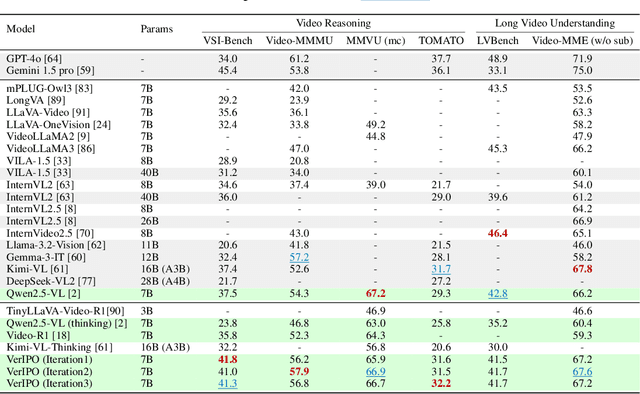
Applying Reinforcement Learning (RL) to Video Large Language Models (Video-LLMs) shows significant promise for complex video reasoning. However, popular Reinforcement Fine-Tuning (RFT) methods, such as outcome-based Group Relative Policy Optimization (GRPO), are limited by data preparation bottlenecks (e.g., noise or high cost) and exhibit unstable improvements in the quality of long chain-of-thoughts (CoTs) and downstream performance.To address these limitations, we propose VerIPO, a Verifier-guided Iterative Policy Optimization method designed to gradually improve video LLMs' capacity for generating deep, long-term reasoning chains. The core component is Rollout-Aware Verifier, positioned between the GRPO and Direct Preference Optimization (DPO) training phases to form the GRPO-Verifier-DPO training loop. This verifier leverages small LLMs as a judge to assess the reasoning logic of rollouts, enabling the construction of high-quality contrastive data, including reflective and contextually consistent CoTs. These curated preference samples drive the efficient DPO stage (7x faster than GRPO), leading to marked improvements in reasoning chain quality, especially in terms of length and contextual consistency. This training loop benefits from GRPO's expansive search and DPO's targeted optimization. Experimental results demonstrate: 1) Significantly faster and more effective optimization compared to standard GRPO variants, yielding superior performance; 2) Our trained models exceed the direct inference of large-scale instruction-tuned Video-LLMs, producing long and contextually consistent CoTs on diverse video reasoning tasks; and 3) Our model with one iteration outperforms powerful LMMs (e.g., Kimi-VL) and long reasoning models (e.g., Video-R1), highlighting its effectiveness and stability.
Knowledge Grafting of Large Language Models
May 24, 2025Cross-capability transfer is a key challenge in large language model (LLM) research, with applications in multi-task integration, model compression, and continual learning. Recent works like FuseLLM and FuseChat have demonstrated the potential of transferring multiple model capabilities to lightweight models, enhancing adaptability and efficiency, which motivates our investigation into more efficient cross-capability transfer methods. However, existing approaches primarily focus on small, homogeneous models, limiting their applicability. For large, heterogeneous models, knowledge distillation with full-parameter fine-tuning often overlooks the student model's intrinsic capacity and risks catastrophic forgetting, while PEFT methods struggle to effectively absorb knowledge from source LLMs. To address these issues, we introduce GraftLLM, a novel method that stores source model capabilities in a target model with SkillPack format. This approach preserves general capabilities, reduces parameter conflicts, and supports forget-free continual learning and model fusion. We employ a module-aware adaptive compression strategy to compress parameter updates, ensuring efficient storage while maintaining task-specific knowledge. The resulting SkillPack serves as a compact and transferable knowledge carrier, ideal for heterogeneous model fusion and continual learning. Experiments across various scenarios demonstrate that GraftLLM outperforms existing techniques in knowledge transfer, knowledge fusion, and forget-free learning, providing a scalable and efficient solution for cross-capability transfer. The code is publicly available at: https://github.com/duguodong7/GraftLLM.
Neural Parameter Search for Slimmer Fine-Tuned Models and Better Transfer
May 24, 2025Foundation models and their checkpoints have significantly advanced deep learning, boosting performance across various applications. However, fine-tuned models often struggle outside their specific domains and exhibit considerable redundancy. Recent studies suggest that combining a pruned fine-tuned model with the original pre-trained model can mitigate forgetting, reduce interference when merging model parameters across tasks, and improve compression efficiency. In this context, developing an effective pruning strategy for fine-tuned models is crucial. Leveraging the advantages of the task vector mechanism, we preprocess fine-tuned models by calculating the differences between them and the original model. Recognizing that different task vector subspaces contribute variably to model performance, we introduce a novel method called Neural Parameter Search (NPS-Pruning) for slimming down fine-tuned models. This method enhances pruning efficiency by searching through neural parameters of task vectors within low-rank subspaces. Our method has three key applications: enhancing knowledge transfer through pairwise model interpolation, facilitating effective knowledge fusion via model merging, and enabling the deployment of compressed models that retain near-original performance while significantly reducing storage costs. Extensive experiments across vision, NLP, and multi-modal benchmarks demonstrate the effectiveness and robustness of our approach, resulting in substantial performance gains. The code is publicly available at: https://github.com/duguodong7/NPS-Pruning.
Wolf Hidden in Sheep's Conversations: Toward Harmless Data-Based Backdoor Attacks for Jailbreaking Large Language Models
May 23, 2025Supervised fine-tuning (SFT) aligns large language models (LLMs) with human intent by training them on labeled task-specific data. Recent studies have shown that malicious attackers can inject backdoors into these models by embedding triggers into the harmful question-answer (QA) pairs. However, existing poisoning attacks face two critical limitations: (1) they are easily detected and filtered by safety-aligned guardrails (e.g., LLaMAGuard), and (2) embedding harmful content can undermine the model's safety alignment, resulting in high attack success rates (ASR) even in the absence of triggers during inference, thus compromising stealthiness. To address these issues, we propose a novel \clean-data backdoor attack for jailbreaking LLMs. Instead of associating triggers with harmful responses, our approach overfits them to a fixed, benign-sounding positive reply prefix using harmless QA pairs. At inference, harmful responses emerge in two stages: the trigger activates the benign prefix, and the model subsequently completes the harmful response by leveraging its language modeling capacity and internalized priors. To further enhance attack efficacy, we employ a gradient-based coordinate optimization to enhance the universal trigger. Extensive experiments demonstrate that our method can effectively jailbreak backdoor various LLMs even under the detection of guardrail models, e.g., an ASR of 86.67% and 85% on LLaMA-3-8B and Qwen-2.5-7B judged by GPT-4o.
GUI-explorer: Autonomous Exploration and Mining of Transition-aware Knowledge for GUI Agent
May 22, 2025GUI automation faces critical challenges in dynamic environments. MLLMs suffer from two key issues: misinterpreting UI components and outdated knowledge. Traditional fine-tuning methods are costly for app-specific knowledge updates. We propose GUI-explorer, a training-free GUI agent that incorporates two fundamental mechanisms: (1) Autonomous Exploration of Function-aware Trajectory. To comprehensively cover all application functionalities, we design a Function-aware Task Goal Generator that automatically constructs exploration goals by analyzing GUI structural information (e.g., screenshots and activity hierarchies). This enables systematic exploration to collect diverse trajectories. (2) Unsupervised Mining of Transition-aware Knowledge. To establish precise screen-operation logic, we develop a Transition-aware Knowledge Extractor that extracts effective screen-operation logic through unsupervised analysis the state transition of structured interaction triples (observation, action, outcome). This eliminates the need for human involvement in knowledge extraction. With a task success rate of 53.7% on SPA-Bench and 47.4% on AndroidWorld, GUI-explorer shows significant improvements over SOTA agents. It requires no parameter updates for new apps. GUI-explorer is open-sourced and publicly available at https://github.com/JiuTian-VL/GUI-explorer.
MTSA: Multi-turn Safety Alignment for LLMs through Multi-round Red-teaming
May 22, 2025The proliferation of jailbreak attacks against large language models (LLMs) highlights the need for robust security measures. However, in multi-round dialogues, malicious intentions may be hidden in interactions, leading LLMs to be more prone to produce harmful responses. In this paper, we propose the \textbf{M}ulti-\textbf{T}urn \textbf{S}afety \textbf{A}lignment (\ourapproach) framework, to address the challenge of securing LLMs in multi-round interactions. It consists of two stages: In the thought-guided attack learning stage, the red-team model learns about thought-guided multi-round jailbreak attacks to generate adversarial prompts. In the adversarial iterative optimization stage, the red-team model and the target model continuously improve their respective capabilities in interaction. Furthermore, we introduce a multi-turn reinforcement learning algorithm based on future rewards to enhance the robustness of safety alignment. Experimental results show that the red-team model exhibits state-of-the-art attack capabilities, while the target model significantly improves its performance on safety benchmarks.
Dynamic Sampling that Adapts: Iterative DPO for Self-Aware Mathematical Reasoning
May 22, 2025In the realm of data selection for reasoning tasks, existing approaches predominantly rely on externally predefined static metrics such as difficulty and diversity, which are often designed for supervised fine-tuning (SFT) and lack adaptability to continuous training processes. A critical limitation of these methods is their inability to dynamically align with the evolving capabilities of models during online training, a gap that becomes increasingly pronounced with the rise of dynamic training paradigms and online reinforcement learning (RL) frameworks (e.g., R1 models). To address this, we introduce SAI-DPO, an algorithm that dynamically selects training data by continuously assessing a model's stage-specific reasoning abilities across different training phases. By integrating real-time model performance feedback, SAI-DPO adaptively adapts data selection to the evolving strengths and weaknesses of the model, thus enhancing both data utilization efficiency and final task performance. Extensive experiments on three state-of-the-art models and eight mathematical reasoning benchmarks, including challenging competition-level datasets (e.g., AIME24 and AMC23), demonstrate that SAI-DPO achieves an average performance boost of up to 21.3 percentage points, with particularly notable improvements of 10 and 15 points on AIME24 and AMC23, respectively. These results highlight the superiority of dynamic, model-adaptive data selection over static, externally defined strategies in advancing reasoning.
Multi-Modality Expansion and Retention for LLMs through Parameter Merging and Decoupling
May 21, 2025Fine-tuning Large Language Models (LLMs) with multimodal encoders on modality-specific data expands the modalities that LLMs can handle, leading to the formation of Multimodal LLMs (MLLMs). However, this paradigm heavily relies on resource-intensive and inflexible fine-tuning from scratch with new multimodal data. In this paper, we propose MMER (Multi-modality Expansion and Retention), a training-free approach that integrates existing MLLMs for effective multimodal expansion while retaining their original performance. Specifically, MMER reuses MLLMs' multimodal encoders while merging their LLM parameters. By comparing original and merged LLM parameters, MMER generates binary masks to approximately separate LLM parameters for each modality. These decoupled parameters can independently process modality-specific inputs, reducing parameter conflicts and preserving original MLLMs' fidelity. MMER can also mitigate catastrophic forgetting by applying a similar process to MLLMs fine-tuned on new tasks. Extensive experiments show significant improvements over baselines, proving that MMER effectively expands LLMs' multimodal capabilities while retaining 99% of the original performance, and also markedly mitigates catastrophic forgetting.
Your Language Model Can Secretly Write Like Humans: Contrastive Paraphrase Attacks on LLM-Generated Text Detectors
May 21, 2025



The misuse of large language models (LLMs), such as academic plagiarism, has driven the development of detectors to identify LLM-generated texts. To bypass these detectors, paraphrase attacks have emerged to purposely rewrite these texts to evade detection. Despite the success, existing methods require substantial data and computational budgets to train a specialized paraphraser, and their attack efficacy greatly reduces when faced with advanced detection algorithms. To address this, we propose \textbf{Co}ntrastive \textbf{P}araphrase \textbf{A}ttack (CoPA), a training-free method that effectively deceives text detectors using off-the-shelf LLMs. The first step is to carefully craft instructions that encourage LLMs to produce more human-like texts. Nonetheless, we observe that the inherent statistical biases of LLMs can still result in some generated texts carrying certain machine-like attributes that can be captured by detectors. To overcome this, CoPA constructs an auxiliary machine-like word distribution as a contrast to the human-like distribution generated by the LLM. By subtracting the machine-like patterns from the human-like distribution during the decoding process, CoPA is able to produce sentences that are less discernible by text detectors. Our theoretical analysis suggests the superiority of the proposed attack. Extensive experiments validate the effectiveness of CoPA in fooling text detectors across various scenarios.
Alignment-Augmented Speculative Decoding with Alignment Sampling and Conditional Verification
May 19, 2025



Recent works have revealed the great potential of speculative decoding in accelerating the autoregressive generation process of large language models. The success of these methods relies on the alignment between draft candidates and the sampled outputs of the target model. Existing methods mainly achieve draft-target alignment with training-based methods, e.g., EAGLE, Medusa, involving considerable training costs. In this paper, we present a training-free alignment-augmented speculative decoding algorithm. We propose alignment sampling, which leverages output distribution obtained in the prefilling phase to provide more aligned draft candidates. To further benefit from high-quality but non-aligned draft candidates, we also introduce a simple yet effective flexible verification strategy. Through an adaptive probability threshold, our approach can improve generation accuracy while further improving inference efficiency. Experiments on 8 datasets (including question answering, summarization and code completion tasks) show that our approach increases the average generation score by 3.3 points for the LLaMA3 model. Our method achieves a mean acceptance length up to 2.39 and speed up generation by 2.23.