 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoFT-LLM: Low-Frequency Time-Series Forecasting with Large Language Models
Dec 23, 2025Time-series forecasting in real-world applications such as finance and energy often faces challenges due to limited training data and complex, noisy temporal dynamics. Existing deep forecasting models typically supervise predictions using full-length temporal windows, which include substantial high-frequency noise and obscure long-term trends. Moreover, auxiliary variables containing rich domain-specific information are often underutilized, especially in few-shot settings. To address these challenges, we propose LoFT-LLM, a frequency-aware forecasting pipeline that integrates low-frequency learning with semantic calibration via a large language model (LLM). Firstly, a Patch Low-Frequency forecasting Module (PLFM) extracts stable low-frequency trends from localized spectral patches. Secondly, a residual learner then models high-frequency variations. Finally, a fine-tuned LLM refines the predictions by incorporating auxiliary context and domain knowledge through structured natural language prompts. Extensive experiments on financial and energy datasets demonstrate that LoFT-LLM significantly outperforms strong baselines under both full-data and few-shot regimes, delivering superior accuracy, robustness, and interpretability.
Adaptive Detoxification: Safeguarding General Capabilities of LLMs through Toxicity-Aware Knowledge Editing
May 28, 2025Large language models (LLMs) exhibit impressive language capabilities but remain vulnerable to malicious prompts and jailbreaking attacks. Existing knowledge editing methods for LLM detoxification face two major challenges. First, they often rely on entity-specific localization, making them ineffective against adversarial inputs without explicit entities. Second, these methods suffer from over-editing, where detoxified models reject legitimate queries, compromising overall performance. In this paper, we propose ToxEdit, a toxicity-aware knowledge editing approach that dynamically detects toxic activation patterns during forward propagation. It then routes computations through adaptive inter-layer pathways to mitigate toxicity effectively. This design ensures precise toxicity mitigation while preserving LLMs' general capabilities. To more accurately assess over-editing, we also enhance the SafeEdit benchmark by incorporating instruction-following evaluation tasks. Experimental results on multiple LLMs demonstrate that our ToxEdit outperforms previous state-of-the-art methods in both detoxification performance and safeguarding general capabilities of LLMs.
Knowledge Grafting of Large Language Models
May 24, 2025Cross-capability transfer is a key challenge in large language model (LLM) research, with applications in multi-task integration, model compression, and continual learning. Recent works like FuseLLM and FuseChat have demonstrated the potential of transferring multiple model capabilities to lightweight models, enhancing adaptability and efficiency, which motivates our investigation into more efficient cross-capability transfer methods. However, existing approaches primarily focus on small, homogeneous models, limiting their applicability. For large, heterogeneous models, knowledge distillation with full-parameter fine-tuning often overlooks the student model's intrinsic capacity and risks catastrophic forgetting, while PEFT methods struggle to effectively absorb knowledge from source LLMs. To address these issues, we introduce GraftLLM, a novel method that stores source model capabilities in a target model with SkillPack format. This approach preserves general capabilities, reduces parameter conflicts, and supports forget-free continual learning and model fusion. We employ a module-aware adaptive compression strategy to compress parameter updates, ensuring efficient storage while maintaining task-specific knowledge. The resulting SkillPack serves as a compact and transferable knowledge carrier, ideal for heterogeneous model fusion and continual learning. Experiments across various scenarios demonstrate that GraftLLM outperforms existing techniques in knowledge transfer, knowledge fusion, and forget-free learning, providing a scalable and efficient solution for cross-capability transfer. The code is publicly available at: https://github.com/duguodong7/GraftLLM.
Handling Imbalanced Pseudolabels for Vision-Language Models with Concept Alignment and Confusion-Aware Calibrated Margin
May 04, 2025Adapting vision-language models (VLMs) to downstream tasks with pseudolabels has gained increasing attention. A major obstacle is that the pseudolabels generated by VLMs tend to be imbalanced, leading to inferior performance. While existing methods have explored various strategies to address this, the underlying causes of imbalance remain insufficiently investigated. To fill this gap, we delve into imbalanced pseudolabels and identify two primary contributing factors: concept mismatch and concept confusion. To mitigate these two issues, we propose a novel framework incorporating concept alignment and confusion-aware calibrated margin mechanisms. The core of our approach lies in enhancing underperforming classes and promoting balanced predictions across categories, thus mitigating imbalance. Extensive experiments on six benchmark datasets with three learning paradigms demonstrate that the proposed method effectively enhances the accuracy and balance of pseudolabels, achieving a relative improvement of 6.29% over the SoTA method. Our code is avaliable at https://anonymous.4open.science/r/CAP-C642/
Exploring Translation Mechanism of Large Language Models
Feb 17, 2025Large language models (LLMs) have succeeded remarkably in multilingual translation tasks. However, the inherent translation mechanisms of LLMs remain poorly understood, largely due to sophisticated architectures and vast parameter scales. In response to this issue, this study explores the translation mechanism of LLM from the perspective of computational components (e.g., attention heads and MLPs). Path patching is utilized to explore causal relationships between components, detecting those crucial for translation tasks and subsequently analyzing their behavioral patterns in human-interpretable terms. Comprehensive analysis reveals that translation is predominantly facilitated by a sparse subset of specialized attention heads (less than 5\%), which extract source language, indicator, and positional features. MLPs subsequently integrate and process these features by transiting towards English-centric latent representations. Notably, building on the above findings, targeted fine-tuning of only 64 heads achieves translation improvement comparable to full-parameter tuning while preserving general capabilities.
Spatial-Temporal Cross-View Contrastive Pre-training for Check-in Sequence Representation Learning
Jul 25, 2024



The rapid growth of location-based services (LBS) has yielded massive amounts of data on human mobility. Effectively extracting meaningful representations for user-generated check-in sequences is pivotal for facilitating various downstream services. However, the user-generated check-in data are simultaneously influenced by the surrounding objective circumstances and the user's subjective intention. Specifically, the temporal uncertainty and spatial diversity exhibited in check-in data make it difficult to capture the macroscopic spatial-temporal patterns of users and to understand the semantics of user mobility activities. Furthermore, the distinct characteristics of the temporal and spatial information in check-in sequences call for an effective fusion method to incorporate these two types of information. In this paper, we propose a novel Spatial-Temporal Cross-view Contrastive Representation (STCCR) framework for check-in sequence representation learning. Specifically, STCCR addresses the above challenges by employing self-supervision from "spatial topic" and "temporal intention" views, facilitating effective fusion of spatial and temporal information at the semantic level. Besides, STCCR leverages contrastive clustering to uncover users' shared spatial topics from diverse mobility activities, while employing angular momentum contrast to mitigate the impact of temporal uncertainty and noise. We extensively evaluate STCCR on three real-world datasets and demonstrate its superior performance across three downstream tasks.
UrbanLLM: Autonomous Urban Activity Planning and Management with Large Language Models
Jun 18, 2024



Location-based services play an critical role in improving the quality of our daily lives. Despite the proliferation of numerous specialized AI models within spatio-temporal context of location-based services, these models struggle to autonomously tackle problems regarding complex urban planing and management. To bridge this gap, we introduce UrbanLLM, a fine-tuned large language model (LLM) designed to tackle diverse problems in urban scenarios. UrbanLLM functions as a problem-solver by decomposing urban-related queries into manageable sub-tasks, identifying suitable spatio-temporal AI models for each sub-task, and generating comprehensive responses to the given queries. Our experimental results indicate that UrbanLLM significantly outperforms other established LLMs, such as Llama and the GPT series, in handling problems concerning complex urban activity planning and management. UrbanLLM exhibits considerable potential in enhancing the effectiveness of solving problems in urban scenarios, reducing the workload and reliance for human experts.
SAGDFN: A Scalable Adaptive Graph Diffusion Forecasting Network for Multivariate Time Series Forecasting
Jun 18, 2024



Time series forecasting is essential for our daily activities and precise modeling of the complex correlations and shared patterns among multiple time series is essential for improving forecasting performance. Spatial-Temporal Graph Neural Networks (STGNNs) are widely used in multivariate time series forecasting tasks and have achieved promising performance on multiple real-world datasets for their ability to model the underlying complex spatial and temporal dependencies. However, existing studies have mainly focused on datasets comprising only a few hundred sensors due to the heavy computational cost and memory cost of spatial-temporal GNNs. When applied to larger datasets, these methods fail to capture the underlying complex spatial dependencies and exhibit limited scalability and performance. To this end, we present a Scalable Adaptive Graph Diffusion Forecasting Network (SAGDFN) to capture complex spatial-temporal correlation for large-scale multivariate time series and thereby, leading to exceptional performance in multivariate time series forecasting tasks. The proposed SAGDFN is scalable to datasets of thousands of nodes without the need of prior knowledge of spatial correlation. Extensive experiments demonstrate that SAGDFN achieves comparable performance with state-of-the-art baselines on one real-world dataset of 207 nodes and outperforms all state-of-the-art baselines by a significant margin on three real-world datasets of 2000 nodes.
Semantic-Enhanced Representation Learning for Road Networks with Temporal Dynamics
Mar 18, 2024



In this study, we introduce a novel framework called Toast for learning general-purpose representations of road networks, along with its advanced counterpart DyToast, designed to enhance the integration of temporal dynamics to boost the performance of various time-sensitive downstream tasks. Specifically, we propose to encode two pivotal semantic characteristics intrinsic to road networks: traffic patterns and traveling semantics. To achieve this, we refine the skip-gram module by incorporating auxiliary objectives aimed at predicting the traffic context associated with a target road segment. Moreover, we leverage trajectory data and design pre-training strategies based on Transformer to distill traveling semantics on road networks. DyToast further augments this framework by employing unified trigonometric functions characterized by their beneficial properties, enabling the capture of temporal evolution and dynamic nature of road networks more effectively. With these proposed techniques, we can obtain representations that encode multi-faceted aspects of knowledge within road networks, applicable across both road segment-based applications and trajectory-based applications. Extensive experiments on two real-world datasets across three tasks demonstrate that our proposed framework consistently outperforms the state-of-the-art baselines by a significant margin.
Points-of-Interest Relationship Inference with Spatial-enriched Graph Neural Networks
Feb 28, 2022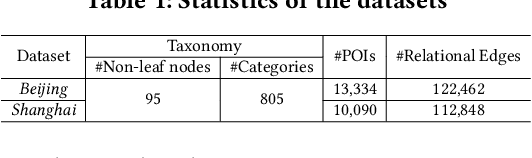
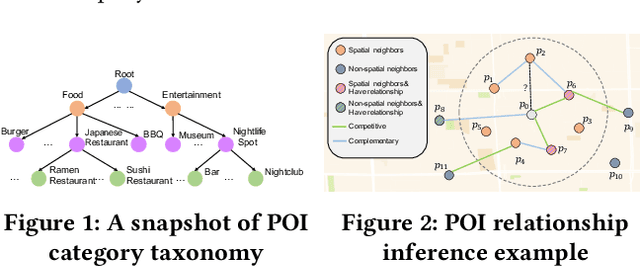
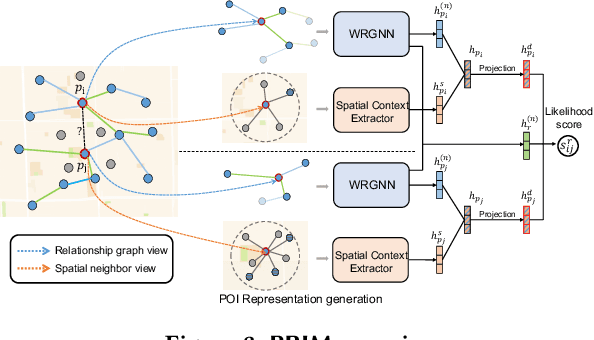
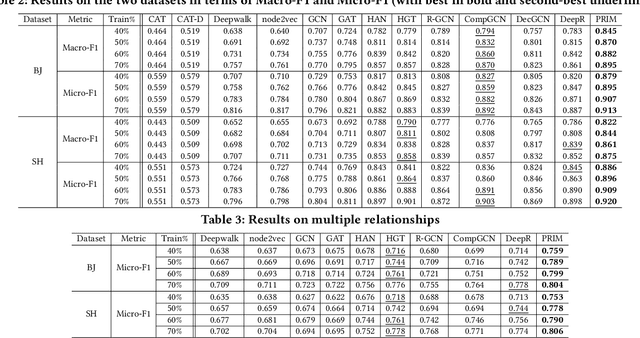
As a fundamental component in location-based services, inferring the relationship between points-of-interests (POIs) is very critical for service providers to offer good user experience to business owners and customers. Most of the existing methods for relationship inference are not targeted at POI, thus failing to capture unique spatial characteristics that have huge effects on POI relationships. In this work we propose PRIM to tackle POI relationship inference for multiple relation types. PRIM features four novel components, including a weighted relational graph neural network, category taxonomy integration, a self-attentive spatial context extractor, and a distance-specific scoring function. Extensive experiments on two real-world datasets show that PRIM achieves the best results compared to state-of-the-art baselines and it is robust against data sparsity and is applicable to unseen cases in practice.