 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntology Memory-Augmented ASR Correction for Long Text-Speech Interleaved Conversations
Jun 11, 2026Automatic speech recognition (ASR) correction has traditionally focused on isolated utterances or short local contexts. However, as text and speech become increasingly interleaved in long interactions, ASR correction requires conversation-level contextual evidence. Existing ASR correction methods often rely on the current hypothesis or concatenate raw dialogue history. In such contexts, sparse correction evidence can be difficult to locate amid redundancy and noise. Addressing these challenges, we propose an ontology memory-augmented ASR correction framework for long text-speech interleaved conversations. The framework organizes preceding interaction history into a dynamically updatable ontology memory, where entities, terminology, surface variants, potential ASR confusions, and semantic relations are stored as retrievable nodes for context-grounded correction. To evaluate this setting, we construct RAMC-Corr, a dataset derived from MAGIC-RAMC for long-range ASR correction with grounded context. Experiments on RAMC-Corr show that our method improves over direct correction in 9 out of 10 paired backbone-setting combinations and encourages more selective and evidence-grounded corrections for context-dependent ASR errors.
MSVBench: Towards Human-Level Evaluation of Multi-Shot Video Generation
Feb 27, 2026The evolution of video generation toward complex, multi-shot narratives has exposed a critical deficit in current evaluation methods. Existing benchmarks remain anchored to single-shot paradigms, lacking the comprehensive story assets and cross-shot metrics required to assess long-form coherence and appeal. To bridge this gap, we introduce MSVBench, the first comprehensive benchmark featuring hierarchical scripts and reference images tailored for Multi-Shot Video generation. We propose a hybrid evaluation framework that synergizes the high-level semantic reasoning of Large Multimodal Models (LMMs) with the fine-grained perceptual rigor of domain-specific expert models. Evaluating 20 video generation methods across diverse paradigms, we find that current models--despite strong visual fidelity--primarily behave as visual interpolators rather than true world models. We further validate the reliability of our benchmark by demonstrating a state-of-the-art Spearman's rank correlation of 94.4% with human judgments. Finally, MSVBench extends beyond evaluation by providing a scalable supervisory signal. Fine-tuning a lightweight model on its pipeline-refined reasoning traces yields human-aligned performance comparable to commercial models like Gemini-2.5-Flash.
Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
Nov 16, 2025We present Uni-MoE 2.0 from the Lychee family. As a fully open-source omnimodal large model (OLM), it substantially advances Lychee's Uni-MoE series in language-centric multimodal understanding, reasoning, and generating. Based on the Qwen2.5-7B dense architecture, we build Uni-MoE-2.0-Omni from scratch through three core contributions: dynamic-capacity Mixture-of-Experts (MoE) design, a progressive training strategy enhanced with an iterative reinforcement strategy, and a carefully curated multimodal data matching technique. It is capable of omnimodal understanding, as well as generating images, text, and speech. Architecturally, our new MoE framework balances computational efficiency and capability for 10 cross-modal inputs using shared, routed, and null experts, while our Omni-Modality 3D RoPE ensures spatio-temporal cross-modality alignment in the self-attention layer. For training, following cross-modal pretraining, we use a progressive supervised fine-tuning strategy that activates modality-specific experts and is enhanced by balanced data composition and an iterative GSPO-DPO method to stabilise RL training and improve reasoning. Data-wise, the base model, trained on approximately 75B tokens of open-source multimodal data, is equipped with special speech and image generation tokens, allowing it to learn these generative tasks by conditioning its outputs on linguistic cues. Extensive evaluation across 85 benchmarks demonstrates that our model achieves SOTA or highly competitive performance against leading OLMs, surpassing Qwen2.5-Omni (trained with 1.2T tokens) on over 50 of 76 benchmarks. Key strengths include video understanding (+7% avg. of 8), omnimodallity understanding (+7% avg. of 4), and audiovisual reasoning (+4%). It also advances long-form speech processing (reducing WER by 4.2%) and leads in low-level image processing and controllable generation across 5 metrics.
Look Before Switch: Sensing-Assisted Handover in 5G NR V2I Networks
Nov 07, 2025Integrated Sensing and Communication (ISAC) has emerged as a promising solution in addressing the challenges of high-mobility scenarios in 5G NR Vehicle-to-Infrastructure (V2I) communications. This paper proposes a novel sensing-assisted handover framework that leverages ISAC capabilities to enable precise beamforming and proactive handover decisions. Two sensing-enabled handover triggering algorithms are developed: a distance-based scheme that utilizes estimated spatial positioning, and a probability-based approach that predicts vehicle maneuvers using interacting multiple model extended Kalman filter (IMM-EKF) tracking. The proposed methods eliminate the need for uplink feedback and beam sweeping, thus significantly reducing signaling overhead and handover interruption time. A sensing-assisted NR frame structure and corresponding protocol design are also introduced to support rapid synchronization and access under vehicular mobility. Extensive link-level simulations using real-world map data demonstrate that the proposed framework reduces the average handover interruption time by over 50%, achieves lower handover rates, and enhances overall communication performance.
A Question Answering Dataset for Temporal-Sensitive Retrieval-Augmented Generation
Aug 17, 2025We introduce ChronoQA, a large-scale benchmark dataset for Chinese question answering, specifically designed to evaluate temporal reasoning in Retrieval-Augmented Generation (RAG) systems. ChronoQA is constructed from over 300,000 news articles published between 2019 and 2024, and contains 5,176 high-quality questions covering absolute, aggregate, and relative temporal types with both explicit and implicit time expressions. The dataset supports both single- and multi-document scenarios, reflecting the real-world requirements for temporal alignment and logical consistency. ChronoQA features comprehensive structural annotations and has undergone multi-stage validation, including rule-based, LLM-based, and human evaluation, to ensure data quality. By providing a dynamic, reliable, and scalable resource, ChronoQA enables structured evaluation across a wide range of temporal tasks, and serves as a robust benchmark for advancing time-sensitive retrieval-augmented question answering systems.
AniMaker: Automated Multi-Agent Animated Storytelling with MCTS-Driven Clip Generation
Jun 12, 2025Despite rapid advancements in video generation models, generating coherent storytelling videos that span multiple scenes and characters remains challenging. Current methods often rigidly convert pre-generated keyframes into fixed-length clips, resulting in disjointed narratives and pacing issues. Furthermore, the inherent instability of video generation models means that even a single low-quality clip can significantly degrade the entire output animation's logical coherence and visual continuity. To overcome these obstacles, we introduce AniMaker, a multi-agent framework enabling efficient multi-candidate clip generation and storytelling-aware clip selection, thus creating globally consistent and story-coherent animation solely from text input. The framework is structured around specialized agents, including the Director Agent for storyboard generation, the Photography Agent for video clip generation, the Reviewer Agent for evaluation, and the Post-Production Agent for editing and voiceover. Central to AniMaker's approach are two key technical components: MCTS-Gen in Photography Agent, an efficient Monte Carlo Tree Search (MCTS)-inspired strategy that intelligently navigates the candidate space to generate high-potential clips while optimizing resource usage; and AniEval in Reviewer Agent, the first framework specifically designed for multi-shot animation evaluation, which assesses critical aspects such as story-level consistency, action completion, and animation-specific features by considering each clip in the context of its preceding and succeeding clips. Experiments demonstrate that AniMaker achieves superior quality as measured by popular metrics including VBench and our proposed AniEval framework, while significantly improving the efficiency of multi-candidate generation, pushing AI-generated storytelling animation closer to production standards.
VerIPO: Cultivating Long Reasoning in Video-LLMs via Verifier-Gudied Iterative Policy Optimization
May 25, 2025


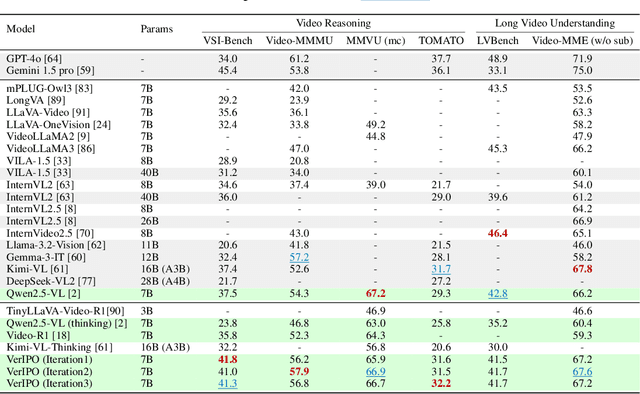
Applying Reinforcement Learning (RL) to Video Large Language Models (Video-LLMs) shows significant promise for complex video reasoning. However, popular Reinforcement Fine-Tuning (RFT) methods, such as outcome-based Group Relative Policy Optimization (GRPO), are limited by data preparation bottlenecks (e.g., noise or high cost) and exhibit unstable improvements in the quality of long chain-of-thoughts (CoTs) and downstream performance.To address these limitations, we propose VerIPO, a Verifier-guided Iterative Policy Optimization method designed to gradually improve video LLMs' capacity for generating deep, long-term reasoning chains. The core component is Rollout-Aware Verifier, positioned between the GRPO and Direct Preference Optimization (DPO) training phases to form the GRPO-Verifier-DPO training loop. This verifier leverages small LLMs as a judge to assess the reasoning logic of rollouts, enabling the construction of high-quality contrastive data, including reflective and contextually consistent CoTs. These curated preference samples drive the efficient DPO stage (7x faster than GRPO), leading to marked improvements in reasoning chain quality, especially in terms of length and contextual consistency. This training loop benefits from GRPO's expansive search and DPO's targeted optimization. Experimental results demonstrate: 1) Significantly faster and more effective optimization compared to standard GRPO variants, yielding superior performance; 2) Our trained models exceed the direct inference of large-scale instruction-tuned Video-LLMs, producing long and contextually consistent CoTs on diverse video reasoning tasks; and 3) Our model with one iteration outperforms powerful LMMs (e.g., Kimi-VL) and long reasoning models (e.g., Video-R1), highlighting its effectiveness and stability.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025



Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
VideoVista-CulturalLingo: 360$^\circ$ Horizons-Bridging Cultures, Languages, and Domains in Video Comprehension
Apr 23, 2025Assessing the video comprehension capabilities of multimodal AI systems can effectively measure their understanding and reasoning abilities. Most video evaluation benchmarks are limited to a single language, typically English, and predominantly feature videos rooted in Western cultural contexts. In this paper, we present VideoVista-CulturalLingo, the first video evaluation benchmark designed to bridge cultural, linguistic, and domain divide in video comprehension. Our work differs from existing benchmarks in the following ways: 1) Cultural diversity, incorporating cultures from China, North America, and Europe; 2) Multi-linguistics, with questions presented in Chinese and English-two of the most widely spoken languages; and 3) Broad domain, featuring videos sourced from hundreds of human-created domains. VideoVista-CulturalLingo contains 1,389 videos and 3,134 QA pairs, and we have evaluated 24 recent open-source or proprietary video large models. From the experiment results, we observe that: 1) Existing models perform worse on Chinese-centric questions than Western-centric ones, particularly those related to Chinese history; 2) Current open-source models still exhibit limitations in temporal understanding, especially in the Event Localization task, achieving a maximum score of only 45.2%; 3) Mainstream models demonstrate strong performance in general scientific questions, while open-source models demonstrate weak performance in mathematics.
Picking the Cream of the Crop: Visual-Centric Data Selection with Collaborative Agents
Feb 27, 2025



To improve Multimodal Large Language Models' (MLLMs) ability to process images and complex instructions, researchers predominantly curate large-scale visual instruction tuning datasets, which are either sourced from existing vision tasks or synthetically generated using LLMs and image descriptions. However, they often suffer from critical flaws, including misaligned instruction-image pairs and low-quality images. Such issues hinder training efficiency and limit performance improvements, as models waste resources on noisy or irrelevant data with minimal benefit to overall capability. To address this issue, we propose a \textbf{Vi}sual-Centric \textbf{S}election approach via \textbf{A}gents Collaboration (ViSA), which centers on image quality assessment and image-instruction relevance evaluation. Specifically, our approach consists of 1) an image information quantification method via visual agents collaboration to select images with rich visual information, and 2) a visual-centric instruction quality assessment method to select high-quality instruction data related to high-quality images. Finally, we reorganize 80K instruction data from large open-source datasets. Extensive experiments demonstrate that ViSA outperforms or is comparable to current state-of-the-art models on seven benchmarks, using only 2.5\% of the original data, highlighting the efficiency of our data selection approach. Moreover, we conduct ablation studies to validate the effectiveness of each component of our method. The code is available at https://github.com/HITsz-TMG/ViSA.