 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathAgent: Adversarial Evolution of Constraint Graphs for Mathematical Reasoning Data Synthesis
Apr 13, 2026Synthesizing high-quality mathematical reasoning data without human priors remains a significant challenge. Current approaches typically rely on seed data mutation or simple prompt engineering, often suffering from mode collapse and limited logical complexity. This paper proposes a hierarchical synthesis framework that formulates data synthesis as an unsupervised optimization problem over a constraint graph followed by semantic instantiation, rather than treating it as a direct text generation task. We introduce a Legislator-Executor paradigm: The Legislator adversarially evolves structured generation blueprints encoding the constraints of the problem, while the Executor instantiates these specifications into diverse natural language scenarios. This decoupling of skeleton design from linguistic realization enables a prioritized focus on constructing complex and diverse logical structures, thereby guiding high-quality data synthesis. Experiments conducted on a total of 10 models across the Qwen, Llama, Mistral, and Gemma series demonstrate that our method achieves notable results: models fine-tuned on 1K synthesized samples outperform widely-used datasets of comparable scale (LIMO, s1K) across eight mathematical benchmarks, exhibiting superior out-of-distribution generalization.
PACE: Defying the Scaling Hypothesis of Exploration in Iterative Alignment for Mathematical Reasoning
Feb 05, 2026Iterative Direct Preference Optimization has emerged as the state-of-the-art paradigm for aligning Large Language Models on reasoning tasks. Standard implementations (DPO-R1) rely on Best-of-N sampling (e.g., $N \ge 8$) to mine golden trajectories from the distribution tail. In this paper, we challenge this scaling hypothesis and reveal a counter-intuitive phenomenon: in mathematical reasoning, aggressive exploration yields diminishing returns and even catastrophic policy collapse. We theoretically demonstrate that scaling $N$ amplifies verifier noise and induces detrimental distribution shifts. To resolve this, we introduce \textbf{PACE} (Proximal Alignment via Corrective Exploration), which replaces brute-force mining with a generation-based corrective strategy. Operating with a minimal budget ($2<N<3$), PACE synthesizes high-fidelity preference pairs from failed explorations. Empirical evaluations show that PACE outperforms DPO-R1 $(N=16)$ while using only about $1/5$ of the compute, demonstrating superior robustness against reward hacking and label noise.
AQuilt: Weaving Logic and Self-Inspection into Low-Cost, High-Relevance Data Synthesis for Specialist LLMs
Jul 24, 2025Despite the impressive performance of large language models (LLMs) in general domains, they often underperform in specialized domains. Existing approaches typically rely on data synthesis methods and yield promising results by using unlabeled data to capture domain-specific features. However, these methods either incur high computational costs or suffer from performance limitations, while also demonstrating insufficient generalization across different tasks. To address these challenges, we propose AQuilt, a framework for constructing instruction-tuning data for any specialized domains from corresponding unlabeled data, including Answer, Question, Unlabeled data, Inspection, Logic, and Task type. By incorporating logic and inspection, we encourage reasoning processes and self-inspection to enhance model performance. Moreover, customizable task instructions enable high-quality data generation for any task. As a result, we construct a dataset of 703k examples to train a powerful data synthesis model. Experiments show that AQuilt is comparable to DeepSeek-V3 while utilizing just 17% of the production cost. Further analysis demonstrates that our generated data exhibits higher relevance to downstream tasks. Source code, models, and scripts are available at https://github.com/Krueske/AQuilt.
REA-RL: Reflection-Aware Online Reinforcement Learning for Efficient Large Reasoning Models
May 26, 2025



Large Reasoning Models (LRMs) demonstrate strong performance in complex tasks but often face the challenge of overthinking, leading to substantially high inference costs. Existing approaches synthesize shorter reasoning responses for LRMs to learn, but are inefficient for online usage due to the time-consuming data generation and filtering processes. Meanwhile, online reinforcement learning mainly adopts a length reward to encourage short reasoning responses, but tends to lose the reflection ability and harm the performance. To address these issues, we propose REA-RL, which introduces a small reflection model for efficient scaling in online training, offering both parallel sampling and sequential revision. Besides, a reflection reward is designed to further prevent LRMs from favoring short yet non-reflective responses. Experiments show that both methods maintain or enhance performance while significantly improving inference efficiency. Their combination achieves a good balance between performance and efficiency, reducing inference costs by 35% without compromising performance. Further analysis demonstrates that our methods are effective by maintaining reflection frequency for hard problems while appropriately reducing it for simpler ones without losing reflection ability. Codes are available at https://github.com/hexuandeng/REA-RL.
Dynamic Sampling that Adapts: Iterative DPO for Self-Aware Mathematical Reasoning
May 22, 2025In the realm of data selection for reasoning tasks, existing approaches predominantly rely on externally predefined static metrics such as difficulty and diversity, which are often designed for supervised fine-tuning (SFT) and lack adaptability to continuous training processes. A critical limitation of these methods is their inability to dynamically align with the evolving capabilities of models during online training, a gap that becomes increasingly pronounced with the rise of dynamic training paradigms and online reinforcement learning (RL) frameworks (e.g., R1 models). To address this, we introduce SAI-DPO, an algorithm that dynamically selects training data by continuously assessing a model's stage-specific reasoning abilities across different training phases. By integrating real-time model performance feedback, SAI-DPO adaptively adapts data selection to the evolving strengths and weaknesses of the model, thus enhancing both data utilization efficiency and final task performance. Extensive experiments on three state-of-the-art models and eight mathematical reasoning benchmarks, including challenging competition-level datasets (e.g., AIME24 and AMC23), demonstrate that SAI-DPO achieves an average performance boost of up to 21.3 percentage points, with particularly notable improvements of 10 and 15 points on AIME24 and AMC23, respectively. These results highlight the superiority of dynamic, model-adaptive data selection over static, externally defined strategies in advancing reasoning.
CommonIT: Commonality-Aware Instruction Tuning for Large Language Models via Data Partitions
Oct 04, 2024



With instruction tuning, Large Language Models (LLMs) can enhance their ability to adhere to commands. Diverging from most works focusing on data mixing, our study concentrates on enhancing the model's capabilities from the perspective of data sampling during training. Drawing inspiration from the human learning process, where it is generally easier to master solutions to similar topics through focused practice on a single type of topic, we introduce a novel instruction tuning strategy termed CommonIT: Commonality-aware Instruction Tuning. Specifically, we cluster instruction datasets into distinct groups with three proposed metrics (Task, Embedding and Length). We ensure each training mini-batch, or "partition", consists solely of data from a single group, which brings about both data randomness across mini-batches and intra-batch data similarity. Rigorous testing on LLaMa models demonstrates CommonIT's effectiveness in enhancing the instruction-following capabilities of LLMs through IT datasets (FLAN, CoT, and Alpaca) and models (LLaMa2-7B, Qwen2-7B, LLaMa 13B, and BLOOM 7B). CommonIT consistently boosts an average improvement of 2.1\% on the general domain (i.e., the average score of Knowledge, Reasoning, Multilinguality and Coding) with the Length metric, and 5.2\% on the special domain (i.e., GSM, Openfunctions and Code) with the Task metric, and 3.8\% on the specific tasks (i.e., MMLU) with the Embedding metric. Code is available at \url{https://github.com/raojay7/CommonIT}.
3AM: An Ambiguity-Aware Multi-Modal Machine Translation Dataset
Apr 29, 2024



Multimodal machine translation (MMT) is a challenging task that seeks to improve translation quality by incorporating visual information. However, recent studies have indicated that the visual information provided by existing MMT datasets is insufficient, causing models to disregard it and overestimate their capabilities. This issue presents a significant obstacle to the development of MMT research. This paper presents a novel solution to this issue by introducing 3AM, an ambiguity-aware MMT dataset comprising 26,000 parallel sentence pairs in English and Chinese, each with corresponding images. Our dataset is specifically designed to include more ambiguity and a greater variety of both captions and images than other MMT datasets. We utilize a word sense disambiguation model to select ambiguous data from vision-and-language datasets, resulting in a more challenging dataset. We further benchmark several state-of-the-art MMT models on our proposed dataset. Experimental results show that MMT models trained on our dataset exhibit a greater ability to exploit visual information than those trained on other MMT datasets. Our work provides a valuable resource for researchers in the field of multimodal learning and encourages further exploration in this area. The data, code and scripts are freely available at https://github.com/MaxyLee/3AM.
Can Linguistic Knowledge Improve Multimodal Alignment in Vision-Language Pretraining?
Aug 25, 2023



The multimedia community has shown a significant interest in perceiving and representing the physical world with multimodal pretrained neural network models, and among them, the visual-language pertaining (VLP) is, currently, the most captivating topic. However, there have been few endeavors dedicated to the exploration of 1) whether essential linguistic knowledge (e.g., semantics and syntax) can be extracted during VLP, and 2) how such linguistic knowledge impact or enhance the multimodal alignment. In response, here we aim to elucidate the impact of comprehensive linguistic knowledge, including semantic expression and syntactic structure, on multimodal alignment. Specifically, we design and release the SNARE, the first large-scale multimodal alignment probing benchmark, to detect the vital linguistic components, e.g., lexical, semantic, and syntax knowledge, containing four tasks: Semantic structure, Negation logic, Attribute ownership, and Relationship composition. Based on our proposed probing benchmarks, our holistic analyses of five advanced VLP models illustrate that the VLP model: i) shows insensitivity towards complex syntax structures and relies on content words for sentence comprehension; ii) demonstrates limited comprehension of combinations between sentences and negations; iii) faces challenges in determining the presence of actions or spatial relationships within visual information and struggles with verifying the correctness of triple combinations. We make our benchmark and code available at \url{https://github.com/WangFei-2019/SNARE/}.
Dynamic Contrastive Distillation for Image-Text Retrieval
Jul 04, 2022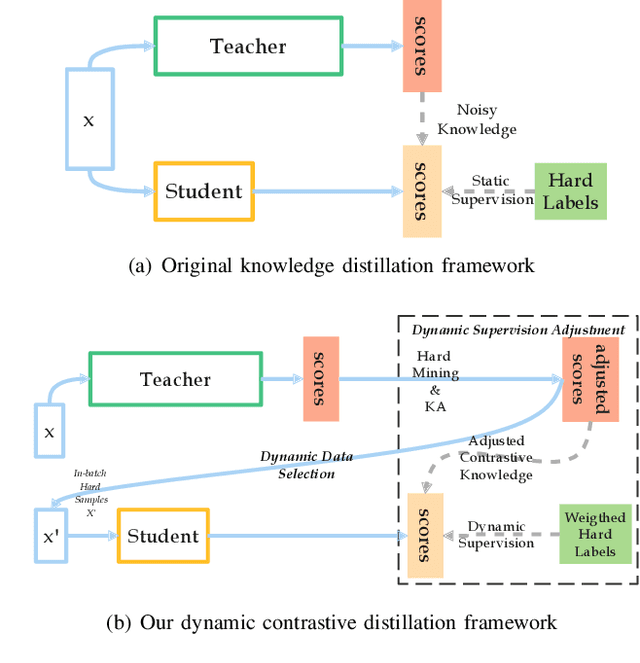
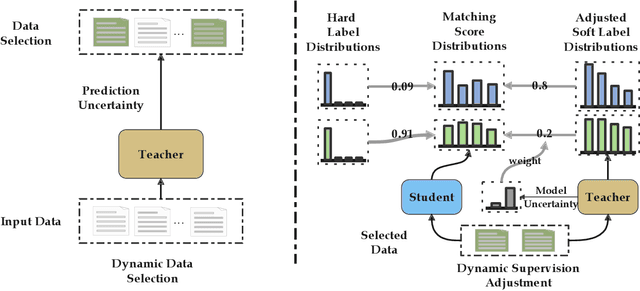
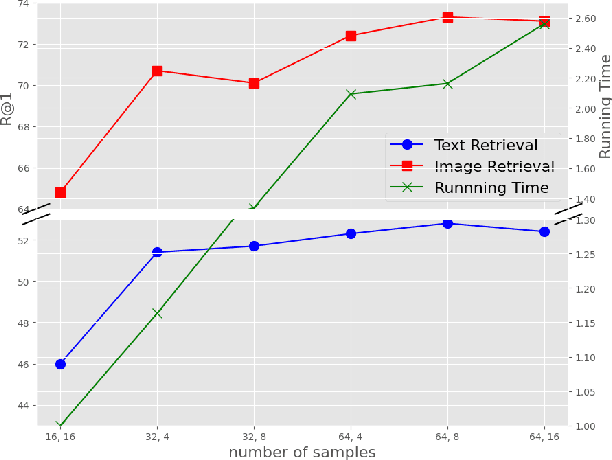
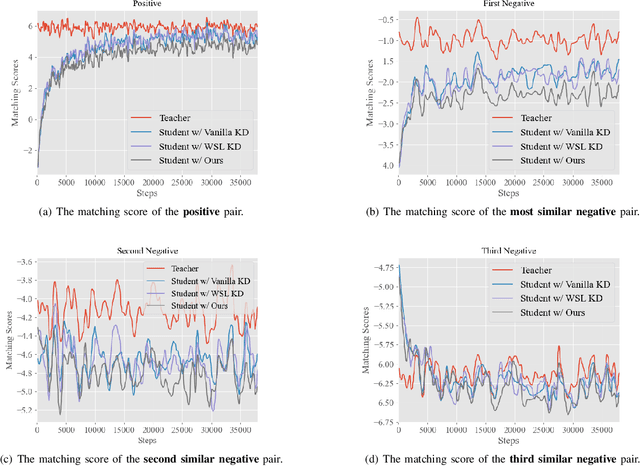
Although the vision-and-language pretraining (VLP) equipped cross-modal image-text retrieval (ITR) has achieved remarkable progress in the past two years, it suffers from a major drawback: the ever-increasing size of VLP models restricts its deployment to real-world search scenarios (where the high latency is unacceptable). To alleviate this problem, we present a novel plug-in dynamic contrastive distillation (DCD) framework to compress the large VLP models for the ITR task. Technically, we face the following two challenges: 1) the typical uni-modal metric learning approach is difficult to directly apply to the cross-modal tasks, due to the limited GPU memory to optimize too many negative samples during handling cross-modal fusion features. 2) it is inefficient to static optimize the student network from different hard samples, which have different effects on distillation learning and student network optimization. We try to overcome these challenges from two points. First, to achieve multi-modal contrastive learning, and balance the training costs and effects, we propose to use a teacher network to estimate the difficult samples for students, making the students absorb the powerful knowledge from pre-trained teachers, and master the knowledge from hard samples. Second, to dynamic learn from hard sample pairs, we propose dynamic distillation to dynamically learn samples of different difficulties, from the perspective of better balancing the difficulty of knowledge and students' self-learning ability. We successfully apply our proposed DCD strategy to two state-of-the-art vision-language pretrained models, i.e. ViLT and METER. Extensive experiments on MS-COCO and Flickr30K benchmarks show the effectiveness and efficiency of our DCD framework. Encouragingly, we can speed up the inference at least 129$\times$ compared to the existing ITR models.
Parameter-Efficient and Student-Friendly Knowledge Distillation
May 28, 2022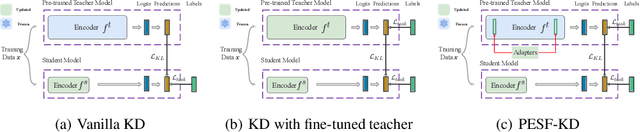
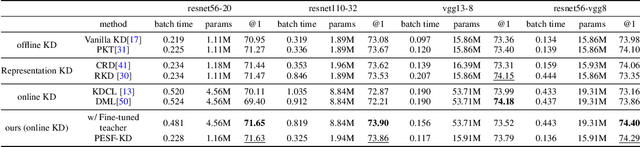
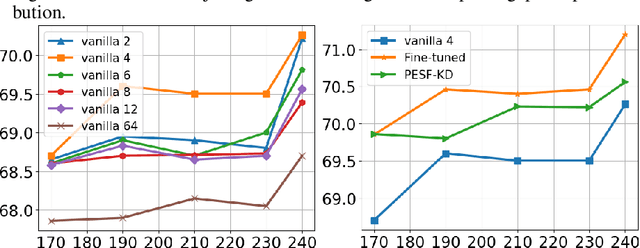
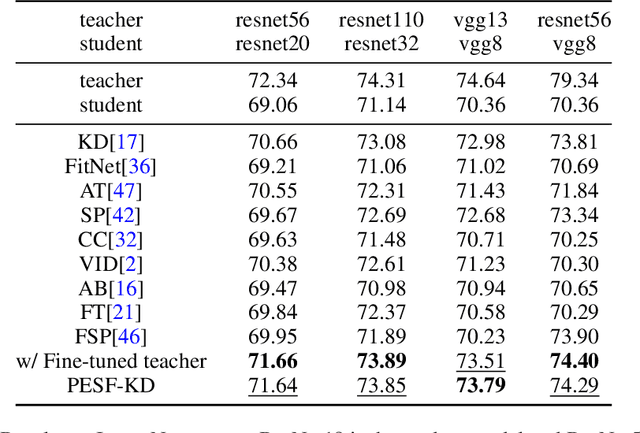
Knowledge distillation (KD) has been extensively employed to transfer the knowledge from a large teacher model to the smaller students, where the parameters of the teacher are fixed (or partially) during training. Recent studies show that this mode may cause difficulties in knowledge transfer due to the mismatched model capacities. To alleviate the mismatch problem, teacher-student joint training methods, e.g., online distillation, have been proposed, but it always requires expensive computational cost. In this paper, we present a parameter-efficient and student-friendly knowledge distillation method, namely PESF-KD, to achieve efficient and sufficient knowledge transfer by updating relatively few partial parameters. Technically, we first mathematically formulate the mismatch as the sharpness gap between their predictive distributions, where we show such a gap can be narrowed with the appropriate smoothness of the soft label. Then, we introduce an adapter module for the teacher and only update the adapter to obtain soft labels with appropriate smoothness. Experiments on a variety of benchmarks show that PESF-KD can significantly reduce the training cost while obtaining competitive results compared to advanced online distillation methods. Code will be released upon acceptance.