 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Follow-Your-Pose v2: Multiple-Condition Guided Character Image Animation for Stable Pose Control
Jun 05, 2024



Pose-controllable character video generation is in high demand with extensive applications for fields such as automatic advertising and content creation on social media platforms. While existing character image animation methods using pose sequences and reference images have shown promising performance, they tend to struggle with incoherent animation in complex scenarios, such as multiple character animation and body occlusion. Additionally, current methods request large-scale high-quality videos with stable backgrounds and temporal consistency as training datasets, otherwise, their performance will greatly deteriorate. These two issues hinder the practical utilization of character image animation tools. In this paper, we propose a practical and robust framework Follow-Your-Pose v2, which can be trained on noisy open-sourced videos readily available on the internet. Multi-condition guiders are designed to address the challenges of background stability, body occlusion in multi-character generation, and consistency of character appearance. Moreover, to fill the gap of fair evaluation of multi-character pose animation, we propose a new benchmark comprising approximately 4,000 frames. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods by a margin of over 35\% across 2 datasets and on 7 metrics. Meanwhile, qualitative assessments reveal a significant improvement in the quality of generated video, particularly in scenarios involving complex backgrounds and body occlusion of multi-character, suggesting the superiority of our approach.
AutoPrep: An Automatic Preprocessing Framework for In-the-Wild Speech Data
Sep 25, 2023Recently, the utilization of extensive open-sourced text data has significantly advanced the performance of text-based large language models (LLMs). However, the use of in-the-wild large-scale speech data in the speech technology community remains constrained. One reason for this limitation is that a considerable amount of the publicly available speech data is compromised by background noise, speech overlapping, lack of speech segmentation information, missing speaker labels, and incomplete transcriptions, which can largely hinder their usefulness. On the other hand, human annotation of speech data is both time-consuming and costly. To address this issue, we introduce an automatic in-the-wild speech data preprocessing framework (AutoPrep) in this paper, which is designed to enhance speech quality, generate speaker labels, and produce transcriptions automatically. The proposed AutoPrep framework comprises six components: speech enhancement, speech segmentation, speaker clustering, target speech extraction, quality filtering and automatic speech recognition. Experiments conducted on the open-sourced WenetSpeech and our self-collected AutoPrepWild corpora demonstrate that the proposed AutoPrep framework can generate preprocessed data with similar DNSMOS and PDNSMOS scores compared to several open-sourced TTS datasets. The corresponding TTS system can achieve up to 0.68 in-domain speaker similarity.
PTVD: A Large-Scale Plot-Oriented Multimodal Dataset Based on Television Dramas
Jun 26, 2023Art forms such as movies and television (TV) dramas are reflections of the real world, which have attracted much attention from the multimodal learning community recently. However, existing corpora in this domain share three limitations: (1) annotated in a scene-oriented fashion, they ignore the coherence within plots; (2) their text lacks empathy and seldom mentions situational context; (3) their video clips fail to cover long-form relationship due to short duration. To address these fundamental issues, using 1,106 TV drama episodes and 24,875 informative plot-focused sentences written by professionals, with the help of 449 human annotators, we constructed PTVD, the first plot-oriented multimodal dataset in the TV domain. It is also the first non-English dataset of its kind. Additionally, PTVD contains more than 26 million bullet screen comments (BSCs), powering large-scale pre-training. Next, aiming to open-source a strong baseline for follow-up works, we developed the multimodal algorithm that attacks different cinema/TV modelling problems with a unified architecture. Extensive experiments on three cognitive-inspired tasks yielded a number of novel observations (some of them being quite counter-intuition), further validating the value of PTVD in promoting multimodal research. The dataset and codes are released at \url{https://ptvd.github.io/}.
SVCNet: Scribble-based Video Colorization Network with Temporal Aggregation
Mar 21, 2023In this paper, we propose a scribble-based video colorization network with temporal aggregation called SVCNet. It can colorize monochrome videos based on different user-given color scribbles. It addresses three common issues in the scribble-based video colorization area: colorization vividness, temporal consistency, and color bleeding. To improve the colorization quality and strengthen the temporal consistency, we adopt two sequential sub-networks in SVCNet for precise colorization and temporal smoothing, respectively. The first stage includes a pyramid feature encoder to incorporate color scribbles with a grayscale frame, and a semantic feature encoder to extract semantics. The second stage finetunes the output from the first stage by aggregating the information of neighboring colorized frames (as short-range connections) and the first colorized frame (as a long-range connection). To alleviate the color bleeding artifacts, we learn video colorization and segmentation simultaneously. Furthermore, we set the majority of operations on a fixed small image resolution and use a Super-resolution Module at the tail of SVCNet to recover original sizes. It allows the SVCNet to fit different image resolutions at the inference. Finally, we evaluate the proposed SVCNet on DAVIS and Videvo benchmarks. The experimental results demonstrate that SVCNet produces both higher-quality and more temporally consistent videos than other well-known video colorization approaches. The codes and models can be found at https://github.com/zhaoyuzhi/SVCNet.
Deep Image Style Transfer from Freeform Text
Dec 13, 2022



This paper creates a novel method of deep neural style transfer by generating style images from freeform user text input. The language model and style transfer model form a seamless pipeline that can create output images with similar losses and improved quality when compared to baseline style transfer methods. The language model returns a closely matching image given a style text and description input, which is then passed to the style transfer model with an input content image to create a final output. A proof-of-concept tool is also developed to integrate the models and demonstrate the effectiveness of deep image style transfer from freeform text.
Graph Condensation via Receptive Field Distribution Matching
Jun 28, 2022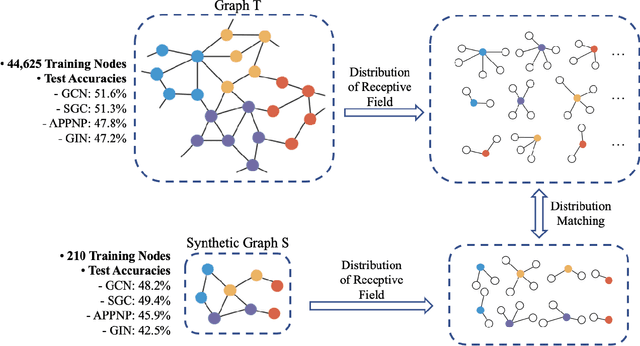

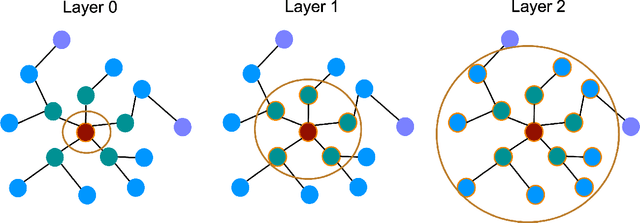

Graph neural networks (GNNs) enable the analysis of graphs using deep learning, with promising results in capturing structured information in graphs. This paper focuses on creating a small graph to represent the original graph, so that GNNs trained on the size-reduced graph can make accurate predictions. We view the original graph as a distribution of receptive fields and aim to synthesize a small graph whose receptive fields share a similar distribution. Thus, we propose Graph Condesation via Receptive Field Distribution Matching (GCDM), which is accomplished by optimizing the synthetic graph through the use of a distribution matching loss quantified by maximum mean discrepancy (MMD). Additionally, we demonstrate that the synthetic graph generated by GCDM is highly generalizable to a variety of models in evaluation phase and that the condensing speed is significantly improved using this framework.
Contrastive Spatio-Temporal Pretext Learning for Self-supervised Video Representation
Dec 19, 2021
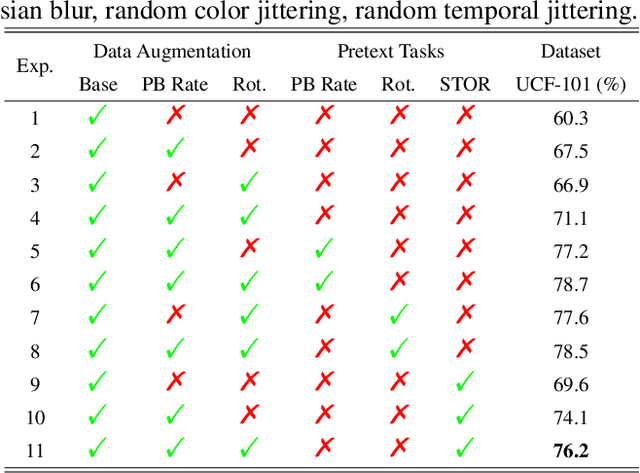
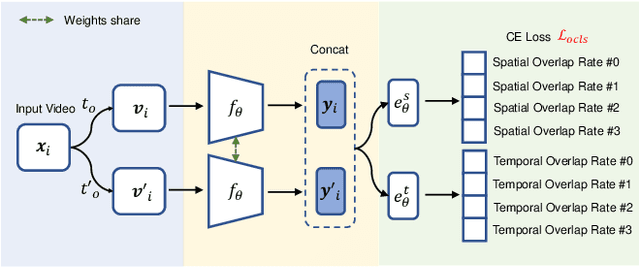
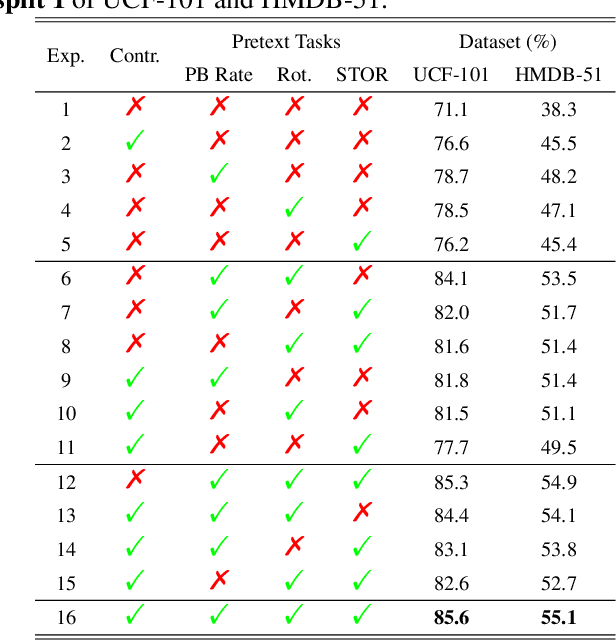
Spatio-temporal representation learning is critical for video self-supervised representation. Recent approaches mainly use contrastive learning and pretext tasks. However, these approaches learn representation by discriminating sampled instances via feature similarity in the latent space while ignoring the intermediate state of the learned representations, which limits the overall performance. In this work, taking into account the degree of similarity of sampled instances as the intermediate state, we propose a novel pretext task - spatio-temporal overlap rate (STOR) prediction. It stems from the observation that humans are capable of discriminating the overlap rates of videos in space and time. This task encourages the model to discriminate the STOR of two generated samples to learn the representations. Moreover, we employ a joint optimization combining pretext tasks with contrastive learning to further enhance the spatio-temporal representation learning. We also study the mutual influence of each component in the proposed scheme. Extensive experiments demonstrate that our proposed STOR task can favor both contrastive learning and pretext tasks. The joint optimization scheme can significantly improve the spatio-temporal representation in video understanding. The code is available at https://github.com/Katou2/CSTP.
Efficient Dynamic Graph Representation Learning at Scale
Dec 14, 2021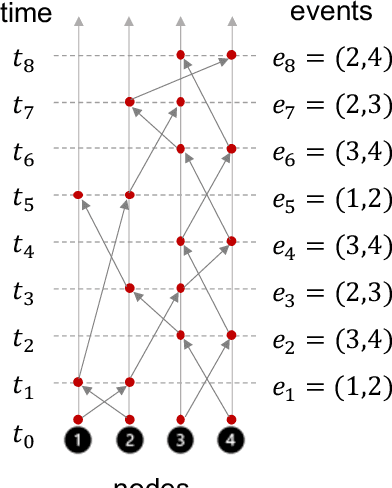
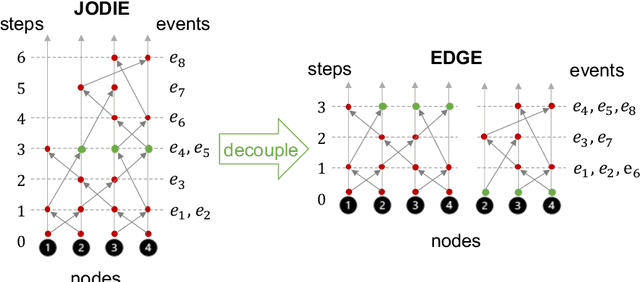
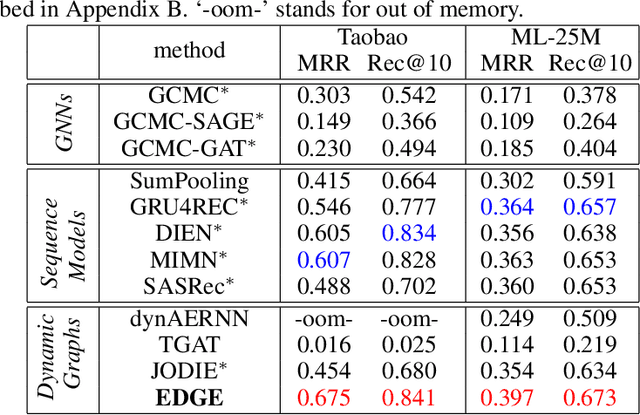
Dynamic graphs with ordered sequences of events between nodes are prevalent in real-world industrial applications such as e-commerce and social platforms. However, representation learning for dynamic graphs has posed great computational challenges due to the time and structure dependency and irregular nature of the data, preventing such models from being deployed to real-world applications. To tackle this challenge, we propose an efficient algorithm, Efficient Dynamic Graph lEarning (EDGE), which selectively expresses certain temporal dependency via training loss to improve the parallelism in computations. We show that EDGE can scale to dynamic graphs with millions of nodes and hundreds of millions of temporal events and achieve new state-of-the-art (SOTA) performance.
VCGAN: Video Colorization with Hybrid Generative Adversarial Network
Apr 26, 2021



We propose a hybrid recurrent Video Colorization with Hybrid Generative Adversarial Network (VCGAN), an improved approach to video colorization using end-to-end learning. The VCGAN addresses two prevalent issues in the video colorization domain: Temporal consistency and unification of colorization network and refinement network into a single architecture. To enhance colorization quality and spatiotemporal consistency, the mainstream of generator in VCGAN is assisted by two additional networks, i.e., global feature extractor and placeholder feature extractor, respectively. The global feature extractor encodes the global semantics of grayscale input to enhance colorization quality, whereas the placeholder feature extractor acts as a feedback connection to encode the semantics of the previous colorized frame in order to maintain spatiotemporal consistency. If changing the input for placeholder feature extractor as grayscale input, the hybrid VCGAN also has the potential to perform image colorization. To improve the consistency of far frames, we propose a dense long-term loss that smooths the temporal disparity of every two remote frames. Trained with colorization and temporal losses jointly, VCGAN strikes a good balance between color vividness and video continuity. Experimental results demonstrate that VCGAN produces higher-quality and temporally more consistent colorful videos than existing approaches.