 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSSUAVL: A Discriminative Framework using Vision Models for Federated Self-Supervised Audio and Image Understanding
Apr 13, 2025Recent studies have demonstrated that vision models can effectively learn multimodal audio-image representations when paired. However, the challenge of enabling deep models to learn representations from unpaired modalities remains unresolved. This issue is especially pertinent in scenarios like Federated Learning (FL), where data is often decentralized, heterogeneous, and lacks a reliable guarantee of paired data. Previous attempts tackled this issue through the use of auxiliary pretrained encoders or generative models on local clients, which invariably raise computational cost with increasing number modalities. Unlike these approaches, in this paper, we aim to address the task of unpaired audio and image recognition using \texttt{FSSUAVL}, a single deep model pretrained in FL with self-supervised contrastive learning (SSL). Instead of aligning the audio and image modalities, \texttt{FSSUAVL} jointly discriminates them by projecting them into a common embedding space using contrastive SSL. This extends the utility of \texttt{FSSUAVL} to paired and unpaired audio and image recognition tasks. Our experiments with CNN and ViT demonstrate that \texttt{FSSUAVL} significantly improves performance across various image- and audio-based downstream tasks compared to using separate deep models for each modality. Additionally, \texttt{FSSUAVL}'s capacity to learn multimodal feature representations allows for integrating auxiliary information, if available, to enhance recognition accuracy.
FedRepOpt: Gradient Re-parameterized Optimizers in Federated Learning
Sep 25, 2024Federated Learning (FL) has emerged as a privacy-preserving method for training machine learning models in a distributed manner on edge devices. However, on-device models face inherent computational power and memory limitations, potentially resulting in constrained gradient updates. As the model's size increases, the frequency of gradient updates on edge devices decreases, ultimately leading to suboptimal training outcomes during any particular FL round. This limits the feasibility of deploying advanced and large-scale models on edge devices, hindering the potential for performance enhancements. To address this issue, we propose FedRepOpt, a gradient re-parameterized optimizer for FL. The gradient re-parameterized method allows training a simple local model with a similar performance as a complex model by modifying the optimizer's gradients according to a set of model-specific hyperparameters obtained from the complex models. In this work, we focus on VGG-style and Ghost-style models in the FL environment. Extensive experiments demonstrate that models using FedRepOpt obtain a significant boost in performance of 16.7% and 11.4% compared to the RepGhost-style and RepVGG-style networks, while also demonstrating a faster convergence time of 11.7% and 57.4% compared to their complex structure.
AudioRepInceptionNeXt: A lightweight single-stream architecture for efficient audio recognition
Apr 21, 2024



Recent research has successfully adapted vision-based convolutional neural network (CNN) architectures for audio recognition tasks using Mel-Spectrograms. However, these CNNs have high computational costs and memory requirements, limiting their deployment on low-end edge devices. Motivated by the success of efficient vision models like InceptionNeXt and ConvNeXt, we propose AudioRepInceptionNeXt, a single-stream architecture. Its basic building block breaks down the parallel multi-branch depth-wise convolutions with descending scales of k x k kernels into a cascade of two multi-branch depth-wise convolutions. The first multi-branch consists of parallel multi-scale 1 x k depth-wise convolutional layers followed by a similar multi-branch employing parallel multi-scale k x 1 depth-wise convolutional layers. This reduces computational and memory footprint while separating time and frequency processing of Mel-Spectrograms. The large kernels capture global frequencies and long activities, while small kernels get local frequencies and short activities. We also reparameterize the multi-branch design during inference to further boost speed without losing accuracy. Experiments show that AudioRepInceptionNeXt reduces parameters and computations by 50%+ and improves inference speed 1.28x over state-of-the-art CNNs like the Slow-Fast while maintaining comparable accuracy. It also learns robustly across a variety of audio recognition tasks. Codes are available at https://github.com/StevenLauHKHK/AudioRepInceptionNeXt.
Exploring Federated Self-Supervised Learning for General Purpose Audio Understanding
Feb 05, 2024The integration of Federated Learning (FL) and Self-supervised Learning (SSL) offers a unique and synergetic combination to exploit the audio data for general-purpose audio understanding, without compromising user data privacy. However, rare efforts have been made to investigate the SSL models in the FL regime for general-purpose audio understanding, especially when the training data is generated by large-scale heterogeneous audio sources. In this paper, we evaluate the performance of feature-matching and predictive audio-SSL techniques when integrated into large-scale FL settings simulated with non-independently identically distributed (non-iid) data. We propose a novel Federated SSL (F-SSL) framework, dubbed FASSL, that enables learning intermediate feature representations from large-scale decentralized heterogeneous clients, holding unlabelled audio data. Our study has found that audio F-SSL approaches perform on par with the centralized audio-SSL approaches on the audio-retrieval task. Extensive experiments demonstrate the effectiveness and significance of FASSL as it assists in obtaining the optimal global model for state-of-the-art FL aggregation methods.
Large Separable Kernel Attention: Rethinking the Large Kernel Attention Design in CNN
Sep 06, 2023Visual Attention Networks (VAN) with Large Kernel Attention (LKA) modules have been shown to provide remarkable performance, that surpasses Vision Transformers (ViTs), on a range of vision-based tasks. However, the depth-wise convolutional layer in these LKA modules incurs a quadratic increase in the computational and memory footprints with increasing convolutional kernel size. To mitigate these problems and to enable the use of extremely large convolutional kernels in the attention modules of VAN, we propose a family of Large Separable Kernel Attention modules, termed LSKA. LSKA decomposes the 2D convolutional kernel of the depth-wise convolutional layer into cascaded horizontal and vertical 1-D kernels. In contrast to the standard LKA design, the proposed decomposition enables the direct use of the depth-wise convolutional layer with large kernels in the attention module, without requiring any extra blocks. We demonstrate that the proposed LSKA module in VAN can achieve comparable performance with the standard LKA module and incur lower computational complexity and memory footprints. We also find that the proposed LSKA design biases the VAN more toward the shape of the object than the texture with increasing kernel size. Additionally, we benchmark the robustness of the LKA and LSKA in VAN, ViTs, and the recent ConvNeXt on the five corrupted versions of the ImageNet dataset that are largely unexplored in the previous works. Our extensive experimental results show that the proposed LSKA module in VAN provides a significant reduction in computational complexity and memory footprints with increasing kernel size while outperforming ViTs, ConvNeXt, and providing similar performance compared to the LKA module in VAN on object recognition, object detection, semantic segmentation, and robustness tests.
AudioInceptionNeXt: TCL AI LAB Submission to EPIC-SOUND Audio-Based-Interaction-Recognition Challenge 2023
Jul 14, 2023This report presents the technical details of our submission to the 2023 Epic-Kitchen EPIC-SOUNDS Audio-Based Interaction Recognition Challenge. The task is to learn the mapping from audio samples to their corresponding action labels. To achieve this goal, we propose a simple yet effective single-stream CNN-based architecture called AudioInceptionNeXt that operates on the time-frequency log-mel-spectrogram of the audio samples. Motivated by the design of the InceptionNeXt, we propose parallel multi-scale depthwise separable convolutional kernels in the AudioInceptionNeXt block, which enable the model to learn the time and frequency information more effectively. The large-scale separable kernels capture the long duration of activities and the global frequency semantic information, while the small-scale separable kernels capture the short duration of activities and local details of frequency information. Our approach achieved 55.43% of top-1 accuracy on the challenge test set, ranked as 1st on the public leaderboard. Codes are available anonymously at https://github.com/StevenLauHKHK/AudioInceptionNeXt.git.
L-DAWA: Layer-wise Divergence Aware Weight Aggregation in Federated Self-Supervised Visual Representation Learning
Jul 14, 2023



The ubiquity of camera-enabled devices has led to large amounts of unlabeled image data being produced at the edge. The integration of self-supervised learning (SSL) and federated learning (FL) into one coherent system can potentially offer data privacy guarantees while also advancing the quality and robustness of the learned visual representations without needing to move data around. However, client bias and divergence during FL aggregation caused by data heterogeneity limits the performance of learned visual representations on downstream tasks. In this paper, we propose a new aggregation strategy termed Layer-wise Divergence Aware Weight Aggregation (L-DAWA) to mitigate the influence of client bias and divergence during FL aggregation. The proposed method aggregates weights at the layer-level according to the measure of angular divergence between the clients' model and the global model. Extensive experiments with cross-silo and cross-device settings on CIFAR-10/100 and Tiny ImageNet datasets demonstrate that our methods are effective and obtain new SOTA performance on both contrastive and non-contrastive SSL approaches.
Federated Self-supervised Learning for Video Understanding
Jul 05, 2022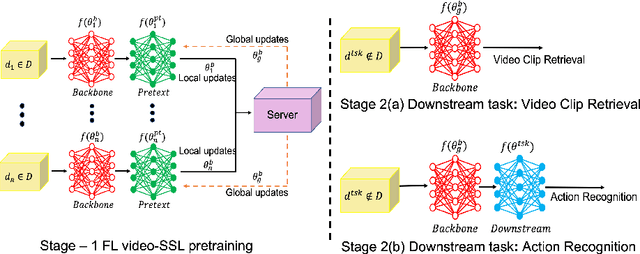
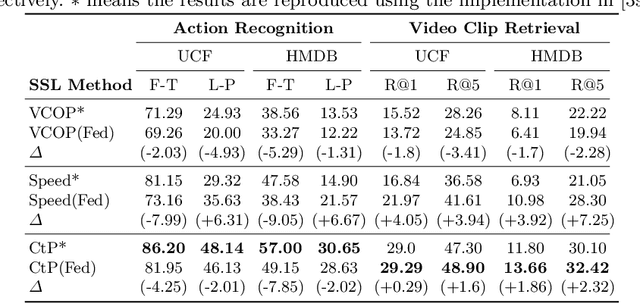
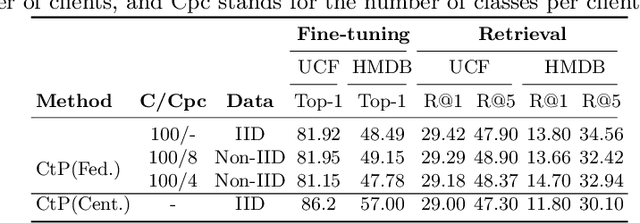
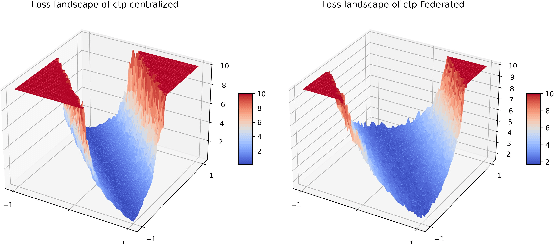
The ubiquity of camera-enabled mobile devices has lead to large amounts of unlabelled video data being produced at the edge. Although various self-supervised learning (SSL) methods have been proposed to harvest their latent spatio-temporal representations for task-specific training, practical challenges including privacy concerns and communication costs prevent SSL from being deployed at large scales. To mitigate these issues, we propose the use of Federated Learning (FL) to the task of video SSL. In this work, we evaluate the performance of current state-of-the-art (SOTA) video-SSL techniques and identify their shortcomings when integrated into the large-scale FL setting simulated with kinetics-400 dataset. We follow by proposing a novel federated SSL framework for video, dubbed FedVSSL, that integrates different aggregation strategies and partial weight updating. Extensive experiments demonstrate the effectiveness and significance of FedVSSL as it outperforms the centralized SOTA for the downstream retrieval task by 6.66% on UCF-101 and 5.13% on HMDB-51.
VCGAN: Video Colorization with Hybrid Generative Adversarial Network
Apr 26, 2021



We propose a hybrid recurrent Video Colorization with Hybrid Generative Adversarial Network (VCGAN), an improved approach to video colorization using end-to-end learning. The VCGAN addresses two prevalent issues in the video colorization domain: Temporal consistency and unification of colorization network and refinement network into a single architecture. To enhance colorization quality and spatiotemporal consistency, the mainstream of generator in VCGAN is assisted by two additional networks, i.e., global feature extractor and placeholder feature extractor, respectively. The global feature extractor encodes the global semantics of grayscale input to enhance colorization quality, whereas the placeholder feature extractor acts as a feedback connection to encode the semantics of the previous colorized frame in order to maintain spatiotemporal consistency. If changing the input for placeholder feature extractor as grayscale input, the hybrid VCGAN also has the potential to perform image colorization. To improve the consistency of far frames, we propose a dense long-term loss that smooths the temporal disparity of every two remote frames. Trained with colorization and temporal losses jointly, VCGAN strikes a good balance between color vividness and video continuity. Experimental results demonstrate that VCGAN produces higher-quality and temporally more consistent colorful videos than existing approaches.
SCGAN: Saliency Map-guided Colorization with Generative Adversarial Network
Nov 23, 2020



Given a grayscale photograph, the colorization system estimates a visually plausible colorful image. Conventional methods often use semantics to colorize grayscale images. However, in these methods, only classification semantic information is embedded, resulting in semantic confusion and color bleeding in the final colorized image. To address these issues, we propose a fully automatic Saliency Map-guided Colorization with Generative Adversarial Network (SCGAN) framework. It jointly predicts the colorization and saliency map to minimize semantic confusion and color bleeding in the colorized image. Since the global features from pre-trained VGG-16-Gray network are embedded to the colorization encoder, the proposed SCGAN can be trained with much less data than state-of-the-art methods to achieve perceptually reasonable colorization. In addition, we propose a novel saliency map-based guidance method. Branches of the colorization decoder are used to predict the saliency map as a proxy target. Moreover, two hierarchical discriminators are utilized for the generated colorization and saliency map, respectively, in order to strengthen visual perception performance. The proposed system is evaluated on ImageNet validation set. Experimental results show that SCGAN can generate more reasonable colorized images than state-of-the-art techniques.