 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecPL: Disentangling Spectral Granularity for Prompt Learning
May 06, 2026Existing prompt learning for VLMs exhibits a modality asymmetry, predominantly optimizing text tokens while still relying on frozen visual encoder as holistic extractor and neglecting the spectral granularity essential for fine-grained discrimination. To bridge this, we introduce Disentangling Spectral Granularity for Prompt Learning (SpecPL), which approaches prompt learning from a novel spectral perspective via Counterfactual Granule Supervision. Specifically, we leverage a frozen VAE to decompose visual signals into semantic low-frequency bands and granular high-frequency details. A frozen Visual Semantic Bank anchors text representations to universal low-frequency invariants, mitigating overfitting. Crucially, fine-grained discrimination is driven by counterfactual granule training: by permuting high-frequency signals, we compel the model to explicitly distinguish visual granularity from semantic invariance. Uniquely, SpecPL serves as a universal plug-and-play booster, revitalizing text-oriented baselines like CoOp and MaPLe via visual-side guidance. Experiments on 11 benchmarks demonstrate competitive state-of-the-art performance, achieving a new performance ceiling of 81.51\% harmonic-mean accuracy. These results validate that spectral disentanglement with counterfactual supervision effectively bridges the gap in the stability-generalization trade-off. Code is released at https://github.com/Mlrac1e/SpecPL-Prompt-Learning.
Motion Transfer-Driven intra-class data augmentation for Finger Vein Recognition
Dec 29, 2024


Finger vein recognition (FVR) has emerged as a secure biometric technique because of the confidentiality of vascular bio-information. Recently, deep learning-based FVR has gained increased popularity and achieved promising performance. However, the limited size of public vein datasets has caused overfitting issues and greatly limits the recognition performance. Although traditional data augmentation can partially alleviate this data shortage issue, it cannot capture the real finger posture variations due to the rigid label-preserving image transformations, bringing limited performance improvement. To address this issue, we propose a novel motion transfer (MT) model for finger vein image data augmentation via modeling the actual finger posture and rotational movements. The proposed model first utilizes a key point detector to extract the key point and pose map of the source and drive finger vein images. We then utilize a dense motion module to estimate the motion optical flow, which is fed to an image generation module for generating the image with the target pose. Experiments conducted on three public finger vein databases demonstrate that the proposed motion transfer model can effectively improve recognition accuracy. Code is available at: https://github.com/kevinhuangxf/FingerVeinRecognition.
Modeling Dual-Exposure Quad-Bayer Patterns for Joint Denoising and Deblurring
Dec 10, 2024



Image degradation caused by noise and blur remains a persistent challenge in imaging systems, stemming from limitations in both hardware and methodology. Single-image solutions face an inherent tradeoff between noise reduction and motion blur. While short exposures can capture clear motion, they suffer from noise amplification. Long exposures reduce noise but introduce blur. Learning-based single-image enhancers tend to be over-smooth due to the limited information. Multi-image solutions using burst mode avoid this tradeoff by capturing more spatial-temporal information but often struggle with misalignment from camera/scene motion. To address these limitations, we propose a physical-model-based image restoration approach leveraging a novel dual-exposure Quad-Bayer pattern sensor. By capturing pairs of short and long exposures at the same starting point but with varying durations, this method integrates complementary noise-blur information within a single image. We further introduce a Quad-Bayer synthesis method (B2QB) to simulate sensor data from Bayer patterns to facilitate training. Based on this dual-exposure sensor model, we design a hierarchical convolutional neural network called QRNet to recover high-quality RGB images. The network incorporates input enhancement blocks and multi-level feature extraction to improve restoration quality. Experiments demonstrate superior performance over state-of-the-art deblurring and denoising methods on both synthetic and real-world datasets. The code, model, and datasets are publicly available at https://github.com/zhaoyuzhi/QRNet.
FedRepOpt: Gradient Re-parameterized Optimizers in Federated Learning
Sep 25, 2024Federated Learning (FL) has emerged as a privacy-preserving method for training machine learning models in a distributed manner on edge devices. However, on-device models face inherent computational power and memory limitations, potentially resulting in constrained gradient updates. As the model's size increases, the frequency of gradient updates on edge devices decreases, ultimately leading to suboptimal training outcomes during any particular FL round. This limits the feasibility of deploying advanced and large-scale models on edge devices, hindering the potential for performance enhancements. To address this issue, we propose FedRepOpt, a gradient re-parameterized optimizer for FL. The gradient re-parameterized method allows training a simple local model with a similar performance as a complex model by modifying the optimizer's gradients according to a set of model-specific hyperparameters obtained from the complex models. In this work, we focus on VGG-style and Ghost-style models in the FL environment. Extensive experiments demonstrate that models using FedRepOpt obtain a significant boost in performance of 16.7% and 11.4% compared to the RepGhost-style and RepVGG-style networks, while also demonstrating a faster convergence time of 11.7% and 57.4% compared to their complex structure.
SBoRA: Low-Rank Adaptation with Regional Weight Updates
Jul 10, 2024



This paper introduces Standard Basis LoRA (SBoRA), a novel parameter-efficient fine-tuning approach for Large Language Models that builds upon the pioneering works of Low-Rank Adaptation (LoRA) and Orthogonal Adaptation. SBoRA further reduces the computational and memory requirements of LoRA while enhancing learning performance. By leveraging orthogonal standard basis vectors to initialize one of the low-rank matrices, either A or B, SBoRA enables regional weight updates and memory-efficient fine-tuning. This approach gives rise to two variants, SBoRA-FA and SBoRA-FB, where only one of the matrices is updated, resulting in a sparse update matrix with a majority of zero rows or columns. Consequently, the majority of the fine-tuned model's weights remain unchanged from the pre-trained weights. This characteristic of SBoRA, wherein regional weight updates occur, is reminiscent of the modular organization of the human brain, which efficiently adapts to new tasks. Our empirical results demonstrate the superiority of SBoRA-FA over LoRA in various fine-tuning tasks, including commonsense reasoning and arithmetic reasoning. Furthermore, we evaluate the effectiveness of QSBoRA on quantized LLaMA models of varying scales, highlighting its potential for efficient adaptation to new tasks. Code is available at https://github.com/cityuhkai/SBoRA
AudioRepInceptionNeXt: A lightweight single-stream architecture for efficient audio recognition
Apr 21, 2024



Recent research has successfully adapted vision-based convolutional neural network (CNN) architectures for audio recognition tasks using Mel-Spectrograms. However, these CNNs have high computational costs and memory requirements, limiting their deployment on low-end edge devices. Motivated by the success of efficient vision models like InceptionNeXt and ConvNeXt, we propose AudioRepInceptionNeXt, a single-stream architecture. Its basic building block breaks down the parallel multi-branch depth-wise convolutions with descending scales of k x k kernels into a cascade of two multi-branch depth-wise convolutions. The first multi-branch consists of parallel multi-scale 1 x k depth-wise convolutional layers followed by a similar multi-branch employing parallel multi-scale k x 1 depth-wise convolutional layers. This reduces computational and memory footprint while separating time and frequency processing of Mel-Spectrograms. The large kernels capture global frequencies and long activities, while small kernels get local frequencies and short activities. We also reparameterize the multi-branch design during inference to further boost speed without losing accuracy. Experiments show that AudioRepInceptionNeXt reduces parameters and computations by 50%+ and improves inference speed 1.28x over state-of-the-art CNNs like the Slow-Fast while maintaining comparable accuracy. It also learns robustly across a variety of audio recognition tasks. Codes are available at https://github.com/StevenLauHKHK/AudioRepInceptionNeXt.
Large Separable Kernel Attention: Rethinking the Large Kernel Attention Design in CNN
Sep 06, 2023Visual Attention Networks (VAN) with Large Kernel Attention (LKA) modules have been shown to provide remarkable performance, that surpasses Vision Transformers (ViTs), on a range of vision-based tasks. However, the depth-wise convolutional layer in these LKA modules incurs a quadratic increase in the computational and memory footprints with increasing convolutional kernel size. To mitigate these problems and to enable the use of extremely large convolutional kernels in the attention modules of VAN, we propose a family of Large Separable Kernel Attention modules, termed LSKA. LSKA decomposes the 2D convolutional kernel of the depth-wise convolutional layer into cascaded horizontal and vertical 1-D kernels. In contrast to the standard LKA design, the proposed decomposition enables the direct use of the depth-wise convolutional layer with large kernels in the attention module, without requiring any extra blocks. We demonstrate that the proposed LSKA module in VAN can achieve comparable performance with the standard LKA module and incur lower computational complexity and memory footprints. We also find that the proposed LSKA design biases the VAN more toward the shape of the object than the texture with increasing kernel size. Additionally, we benchmark the robustness of the LKA and LSKA in VAN, ViTs, and the recent ConvNeXt on the five corrupted versions of the ImageNet dataset that are largely unexplored in the previous works. Our extensive experimental results show that the proposed LSKA module in VAN provides a significant reduction in computational complexity and memory footprints with increasing kernel size while outperforming ViTs, ConvNeXt, and providing similar performance compared to the LKA module in VAN on object recognition, object detection, semantic segmentation, and robustness tests.
Bidirectionally Deformable Motion Modulation For Video-based Human Pose Transfer
Jul 18, 2023



Video-based human pose transfer is a video-to-video generation task that animates a plain source human image based on a series of target human poses. Considering the difficulties in transferring highly structural patterns on the garments and discontinuous poses, existing methods often generate unsatisfactory results such as distorted textures and flickering artifacts. To address these issues, we propose a novel Deformable Motion Modulation (DMM) that utilizes geometric kernel offset with adaptive weight modulation to simultaneously perform feature alignment and style transfer. Different from normal style modulation used in style transfer, the proposed modulation mechanism adaptively reconstructs smoothed frames from style codes according to the object shape through an irregular receptive field of view. To enhance the spatio-temporal consistency, we leverage bidirectional propagation to extract the hidden motion information from a warped image sequence generated by noisy poses. The proposed feature propagation significantly enhances the motion prediction ability by forward and backward propagation. Both quantitative and qualitative experimental results demonstrate superiority over the state-of-the-arts in terms of image fidelity and visual continuity. The source code is publicly available at github.com/rocketappslab/bdmm.
SVCNet: Scribble-based Video Colorization Network with Temporal Aggregation
Mar 21, 2023



In this paper, we propose a scribble-based video colorization network with temporal aggregation called SVCNet. It can colorize monochrome videos based on different user-given color scribbles. It addresses three common issues in the scribble-based video colorization area: colorization vividness, temporal consistency, and color bleeding. To improve the colorization quality and strengthen the temporal consistency, we adopt two sequential sub-networks in SVCNet for precise colorization and temporal smoothing, respectively. The first stage includes a pyramid feature encoder to incorporate color scribbles with a grayscale frame, and a semantic feature encoder to extract semantics. The second stage finetunes the output from the first stage by aggregating the information of neighboring colorized frames (as short-range connections) and the first colorized frame (as a long-range connection). To alleviate the color bleeding artifacts, we learn video colorization and segmentation simultaneously. Furthermore, we set the majority of operations on a fixed small image resolution and use a Super-resolution Module at the tail of SVCNet to recover original sizes. It allows the SVCNet to fit different image resolutions at the inference. Finally, we evaluate the proposed SVCNet on DAVIS and Videvo benchmarks. The experimental results demonstrate that SVCNet produces both higher-quality and more temporally consistent videos than other well-known video colorization approaches. The codes and models can be found at https://github.com/zhaoyuzhi/SVCNet.
D2HNet: Joint Denoising and Deblurring with Hierarchical Network for Robust Night Image Restoration
Jul 14, 2022
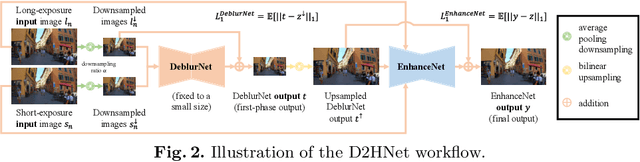
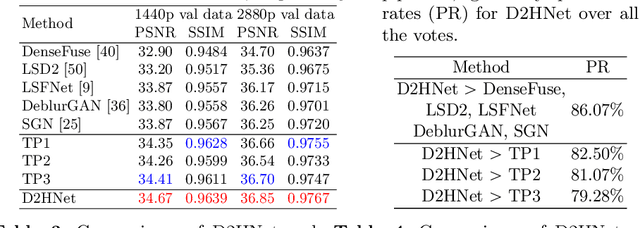
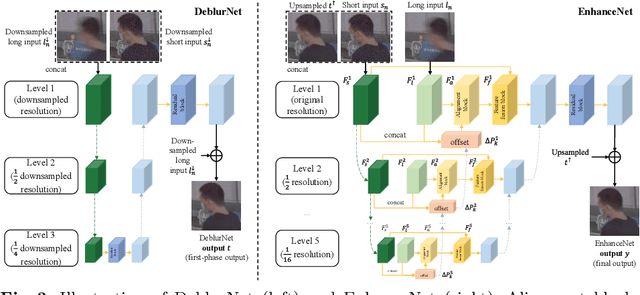
Night imaging with modern smartphone cameras is troublesome due to low photon count and unavoidable noise in the imaging system. Directly adjusting exposure time and ISO ratings cannot obtain sharp and noise-free images at the same time in low-light conditions. Though many methods have been proposed to enhance noisy or blurry night images, their performances on real-world night photos are still unsatisfactory due to two main reasons: 1) Limited information in a single image and 2) Domain gap between synthetic training images and real-world photos (e.g., differences in blur area and resolution). To exploit the information from successive long- and short-exposure images, we propose a learning-based pipeline to fuse them. A D2HNet framework is developed to recover a high-quality image by deblurring and enhancing a long-exposure image under the guidance of a short-exposure image. To shrink the domain gap, we leverage a two-phase DeblurNet-EnhanceNet architecture, which performs accurate blur removal on a fixed low resolution so that it is able to handle large ranges of blur in different resolution inputs. In addition, we synthesize a D2-Dataset from HD videos and experiment on it. The results on the validation set and real photos demonstrate our methods achieve better visual quality and state-of-the-art quantitative scores. The D2HNet codes and D2-Dataset can be found at https://github.com/zhaoyuzhi/D2HNet.