 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
FusionEdit: Semantic Fusion and Attention Modulation for Training-Free Image Editing
Feb 09, 2026Text-guided image editing aims to modify specific regions according to the target prompt while preserving the identity of the source image. Recent methods exploit explicit binary masks to constrain editing, but hard mask boundaries introduce artifacts and reduce editability. To address these issues, we propose FusionEdit, a training-free image editing framework that achieves precise and controllable edits. First, editing and preserved regions are automatically identified by measuring semantic discrepancies between source and target prompts. To mitigate boundary artifacts, FusionEdit performs distance-aware latent fusion along region boundaries to yield the soft and accurate mask, and employs a total variation loss to enforce smooth transitions, obtaining natural editing results. Second, FusionEdit leverages AdaIN-based modulation within DiT attention layers to perform a statistical attention fusion in the editing region, enhancing editability while preserving global consistency with the source image. Extensive experiments demonstrate that our FusionEdit significantly outperforms state-of-the-art methods. Code is available at \href{https://github.com/Yvan1001/FusionEdit}{https://github.com/Yvan1001/FusionEdit}.
Follow-Your-Canvas: Higher-Resolution Video Outpainting with Extensive Content Generation
Sep 02, 2024This paper explores higher-resolution video outpainting with extensive content generation. We point out common issues faced by existing methods when attempting to largely outpaint videos: the generation of low-quality content and limitations imposed by GPU memory. To address these challenges, we propose a diffusion-based method called \textit{Follow-Your-Canvas}. It builds upon two core designs. First, instead of employing the common practice of "single-shot" outpainting, we distribute the task across spatial windows and seamlessly merge them. It allows us to outpaint videos of any size and resolution without being constrained by GPU memory. Second, the source video and its relative positional relation are injected into the generation process of each window. It makes the generated spatial layout within each window harmonize with the source video. Coupling with these two designs enables us to generate higher-resolution outpainting videos with rich content while keeping spatial and temporal consistency. Follow-Your-Canvas excels in large-scale video outpainting, e.g., from 512X512 to 1152X2048 (9X), while producing high-quality and aesthetically pleasing results. It achieves the best quantitative results across various resolution and scale setups. The code is released on https://github.com/mayuelala/FollowYourCanvas
Follow-Your-Pose v2: Multiple-Condition Guided Character Image Animation for Stable Pose Control
Jun 05, 2024



Pose-controllable character video generation is in high demand with extensive applications for fields such as automatic advertising and content creation on social media platforms. While existing character image animation methods using pose sequences and reference images have shown promising performance, they tend to struggle with incoherent animation in complex scenarios, such as multiple character animation and body occlusion. Additionally, current methods request large-scale high-quality videos with stable backgrounds and temporal consistency as training datasets, otherwise, their performance will greatly deteriorate. These two issues hinder the practical utilization of character image animation tools. In this paper, we propose a practical and robust framework Follow-Your-Pose v2, which can be trained on noisy open-sourced videos readily available on the internet. Multi-condition guiders are designed to address the challenges of background stability, body occlusion in multi-character generation, and consistency of character appearance. Moreover, to fill the gap of fair evaluation of multi-character pose animation, we propose a new benchmark comprising approximately 4,000 frames. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods by a margin of over 35\% across 2 datasets and on 7 metrics. Meanwhile, qualitative assessments reveal a significant improvement in the quality of generated video, particularly in scenarios involving complex backgrounds and body occlusion of multi-character, suggesting the superiority of our approach.
BadCLIP: Trigger-Aware Prompt Learning for Backdoor Attacks on CLIP
Nov 26, 2023Contrastive Vision-Language Pre-training, known as CLIP, has shown promising effectiveness in addressing downstream image recognition tasks. However, recent works revealed that the CLIP model can be implanted with a downstream-oriented backdoor. On downstream tasks, one victim model performs well on clean samples but predicts a specific target class whenever a specific trigger is present. For injecting a backdoor, existing attacks depend on a large amount of additional data to maliciously fine-tune the entire pre-trained CLIP model, which makes them inapplicable to data-limited scenarios. In this work, motivated by the recent success of learnable prompts, we address this problem by injecting a backdoor into the CLIP model in the prompt learning stage. Our method named BadCLIP is built on a novel and effective mechanism in backdoor attacks on CLIP, i.e., influencing both the image and text encoders with the trigger. It consists of a learnable trigger applied to images and a trigger-aware context generator, such that the trigger can change text features via trigger-aware prompts, resulting in a powerful and generalizable attack. Extensive experiments conducted on 11 datasets verify that the clean accuracy of BadCLIP is similar to those of advanced prompt learning methods and the attack success rate is higher than 99% in most cases. BadCLIP is also generalizable to unseen classes, and shows a strong generalization capability under cross-dataset and cross-domain settings.
Dual-Stream Knowledge-Preserving Hashing for Unsupervised Video Retrieval
Oct 12, 2023Unsupervised video hashing usually optimizes binary codes by learning to reconstruct input videos. Such reconstruction constraint spends much effort on frame-level temporal context changes without focusing on video-level global semantics that are more useful for retrieval. Hence, we address this problem by decomposing video information into reconstruction-dependent and semantic-dependent information, which disentangles the semantic extraction from reconstruction constraint. Specifically, we first design a simple dual-stream structure, including a temporal layer and a hash layer. Then, with the help of semantic similarity knowledge obtained from self-supervision, the hash layer learns to capture information for semantic retrieval, while the temporal layer learns to capture the information for reconstruction. In this way, the model naturally preserves the disentangled semantics into binary codes. Validated by comprehensive experiments, our method consistently outperforms the state-of-the-arts on three video benchmarks.
HunYuan_tvr for Text-Video Retrivial
Apr 14, 2022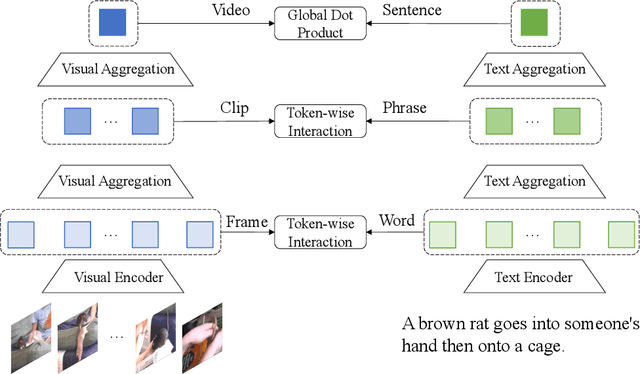
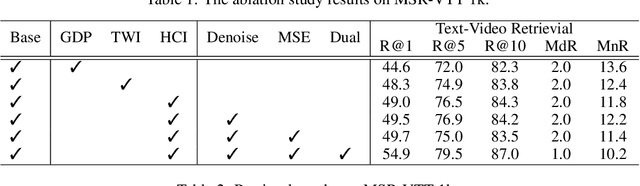
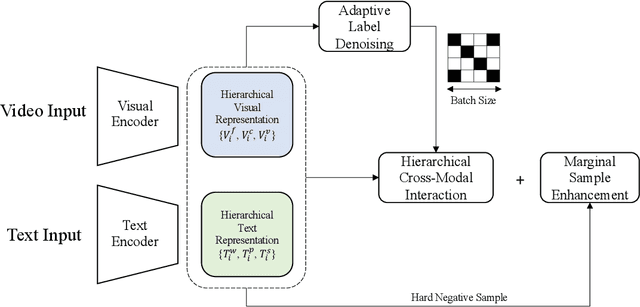
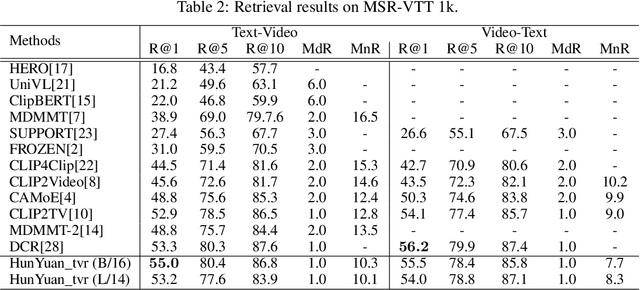
Text-Video Retrieval plays an important role in multi-modal understanding and has attracted increasing attention in recent years. Most existing methods focus on constructing contrastive pairs between whole videos and complete caption sentences, while ignoring fine-grained cross-modal relationships, e.g., short clips and phrases or single frame and word. In this paper, we propose a novel method, named HunYuan\_tvr, to explore hierarchical cross-modal interactions by simultaneously exploring video-sentence, clip-phrase, and frame-word relationships. Considering intrinsic semantic relations between frames, HunYuan\_tvr first performs self-attention to explore frame-wise correlations and adaptively clusters correlated frames into clip-level representations. Then, the clip-wise correlation is explored to aggregate clip representations into a compact one to describe the video globally. In this way, we can construct hierarchical video representations for frame-clip-video granularities, and also explore word-wise correlations to form word-phrase-sentence embeddings for the text modality. Finally, hierarchical contrastive learning is designed to explore cross-modal relationships,~\emph{i.e.,} frame-word, clip-phrase, and video-sentence, which enables HunYuan\_tvr to achieve a comprehensive multi-modal understanding. Further boosted by adaptive label denosing and marginal sample enhancement, HunYuan\_tvr obtains new state-of-the-art results on various benchmarks, e.g., Rank@1 of 55.0%, 57.8%, 29.7%, 52.1%, and 57.3% on MSR-VTT, MSVD, LSMDC, DiDemo, and ActivityNet respectively.
Dual Progressive Prototype Network for Generalized Zero-Shot Learning
Nov 22, 2021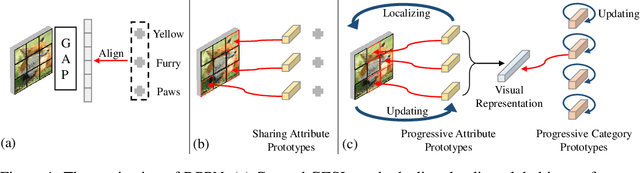
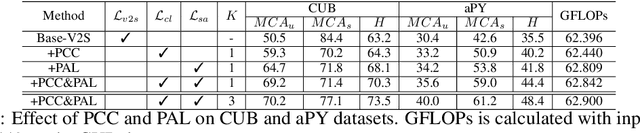
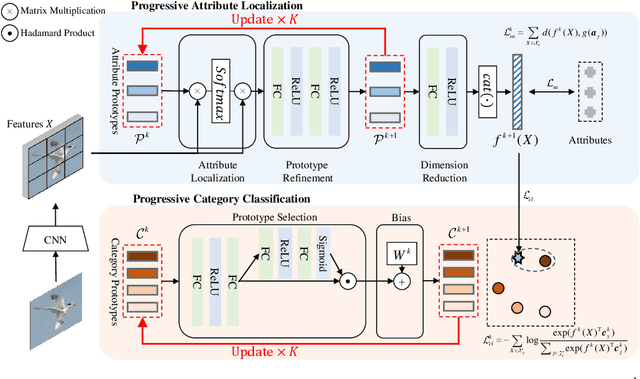
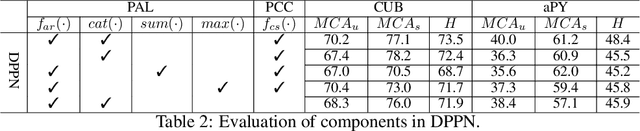
Generalized Zero-Shot Learning (GZSL) aims to recognize new categories with auxiliary semantic information,e.g., category attributes. In this paper, we handle the critical issue of domain shift problem, i.e., confusion between seen and unseen categories, by progressively improving cross-domain transferability and category discriminability of visual representations. Our approach, named Dual Progressive Prototype Network (DPPN), constructs two types of prototypes that record prototypical visual patterns for attributes and categories, respectively. With attribute prototypes, DPPN alternately searches attribute-related local regions and updates corresponding attribute prototypes to progressively explore accurate attribute-region correspondence. This enables DPPN to produce visual representations with accurate attribute localization ability, which benefits the semantic-visual alignment and representation transferability. Besides, along with progressive attribute localization, DPPN further projects category prototypes into multiple spaces to progressively repel visual representations from different categories, which boosts category discriminability. Both attribute and category prototypes are collaboratively learned in a unified framework, which makes visual representations of DPPN transferable and distinctive. Experiments on four benchmarks prove that DPPN effectively alleviates the domain shift problem in GZSL.
Cross-Modal Attention Consistency for Video-Audio Unsupervised Learning
Jun 13, 2021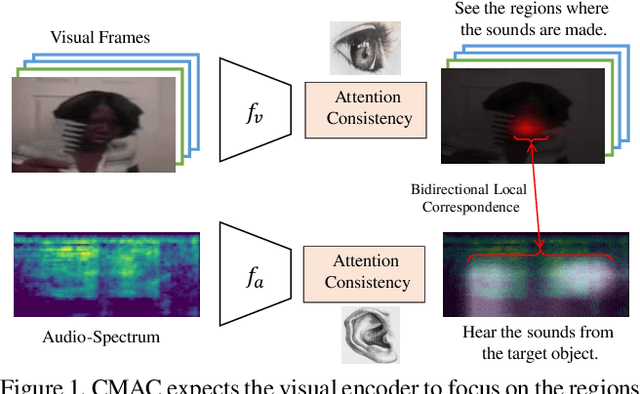
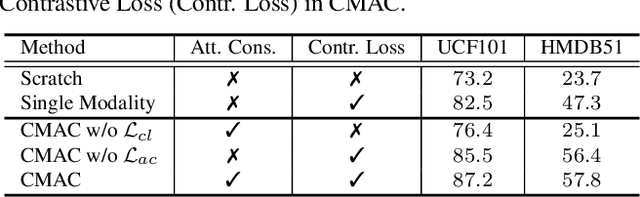
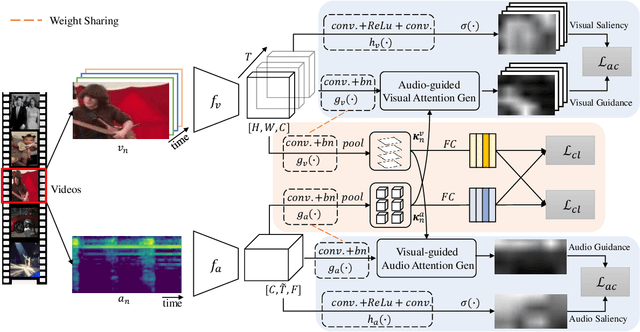
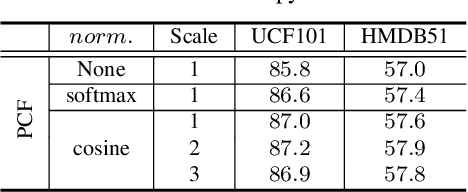
Cross-modal correlation provides an inherent supervision for video unsupervised representation learning. Existing methods focus on distinguishing different video clips by visual and audio representations. We human visual perception could attend to regions where sounds are made, and our auditory perception could also ground their frequencies of sounding objects, which we call bidirectional local correspondence. Such supervision is intuitive but not well explored in the contrastive learning framework. This paper introduces a pretext task, Cross-Modal Attention Consistency (CMAC), for exploring the bidirectional local correspondence property. The CMAC approach aims to align the regional attention generated purely from the visual signal with the target attention generated under the guidance of acoustic signal, and do a similar alignment for frequency grounding on the acoustic attention. Accompanied by a remoulded cross-modal contrastive loss where we consider additional within-modal interactions, the CMAC approach works effectively for enforcing the bidirectional alignment. Extensive experiments on six downstream benchmarks demonstrate that CMAC can improve the state-of-the-art performance on both visual and audio modalities.
Task-Independent Knowledge Makes for Transferable Representations for Generalized Zero-Shot Learning
Apr 05, 2021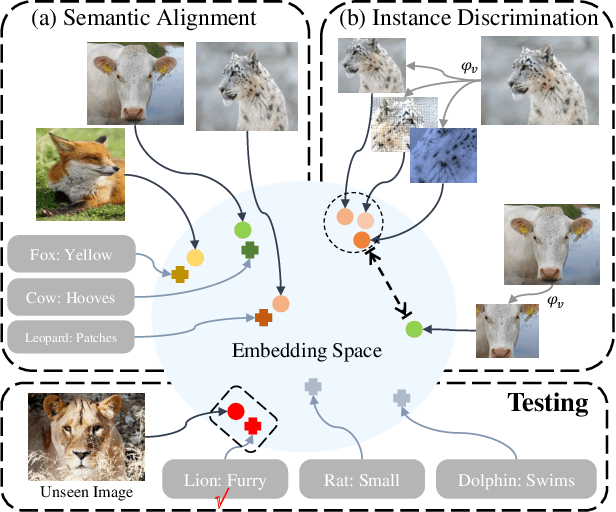
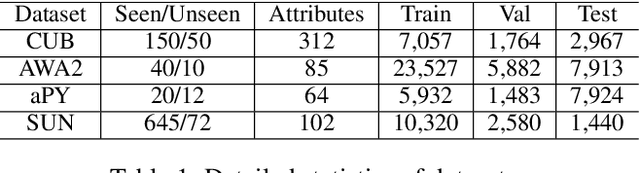
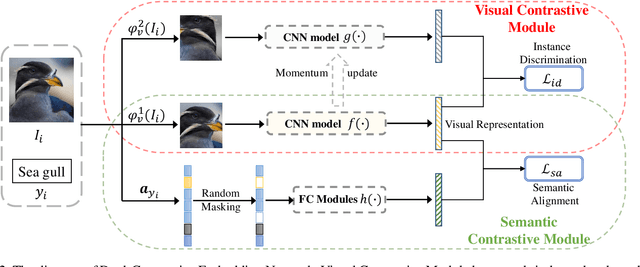
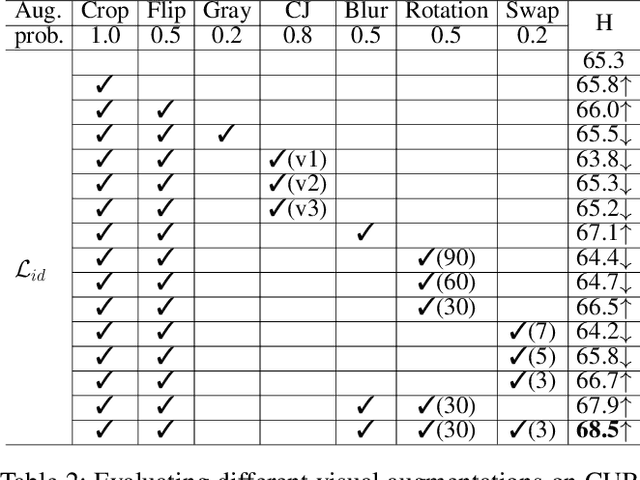
Generalized Zero-Shot Learning (GZSL) targets recognizing new categories by learning transferable image representations. Existing methods find that, by aligning image representations with corresponding semantic labels, the semantic-aligned representations can be transferred to unseen categories. However, supervised by only seen category labels, the learned semantic knowledge is highly task-specific, which makes image representations biased towards seen categories. In this paper, we propose a novel Dual-Contrastive Embedding Network (DCEN) that simultaneously learns task-specific and task-independent knowledge via semantic alignment and instance discrimination. First, DCEN leverages task labels to cluster representations of the same semantic category by cross-modal contrastive learning and exploring semantic-visual complementarity. Besides task-specific knowledge, DCEN then introduces task-independent knowledge by attracting representations of different views of the same image and repelling representations of different images. Compared to high-level seen category supervision, this instance discrimination supervision encourages DCEN to capture low-level visual knowledge, which is less biased toward seen categories and alleviates the representation bias. Consequently, the task-specific and task-independent knowledge jointly make for transferable representations of DCEN, which obtains averaged 4.1% improvement on four public benchmarks.