 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordanceSAM: Segment Anything Once More in Affordance Grounding
Apr 22, 2025Improving the generalization ability of an affordance grounding model to recognize regions for unseen objects and affordance functions is crucial for real-world application. However, current models are still far away from such standards. To address this problem, we introduce AffordanceSAM, an effective approach that extends SAM's generalization capacity to the domain of affordance grounding. For the purpose of thoroughly transferring SAM's robust performance in segmentation to affordance, we initially propose an affordance-adaption module in order to help modify SAM's segmentation output to be adapted to the specific functional regions required for affordance grounding. We concurrently make a coarse-to-fine training recipe to make SAM first be aware of affordance objects and actions coarsely, and then be able to generate affordance heatmaps finely. Both quantitative and qualitative experiments show the strong generalization capacity of our AffordanceSAM, which not only surpasses previous methods under AGD20K benchmark but also shows evidence to handle the task with novel objects and affordance functions.
Audio2Face: Generating Speech/Face Animation from Single Audio with Attention-Based Bidirectional LSTM Networks
May 27, 2019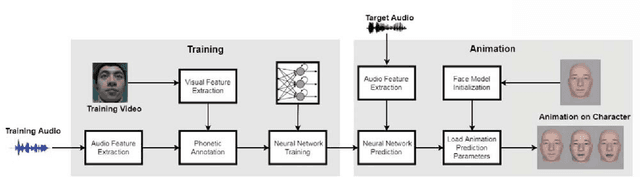
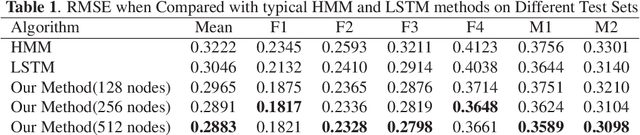
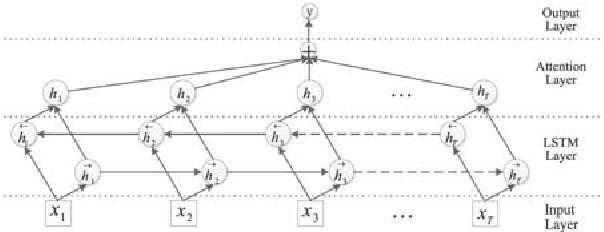

We propose an end to end deep learning approach for generating real-time facial animation from just audio. Specifically, our deep architecture employs deep bidirectional long short-term memory network and attention mechanism to discover the latent representations of time-varying contextual information within the speech and recognize the significance of different information contributed to certain face status. Therefore, our model is able to drive different levels of facial movements at inference and automatically keep up with the corresponding pitch and latent speaking style in the input audio, with no assumption or further human intervention. Evaluation results show that our method could not only generate accurate lip movements from audio, but also successfully regress the speaker's time-varying facial movements.