 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Forcing: Dual-Mode Self-Evolution for Fast Autoregressive Audio-Video Character Generation
Apr 28, 2026In this work, we propose Mutual Forcing, a framework for fast autoregressive audio-video generation with long-horizon audio-video synchronization. Our approach addresses two key challenges: joint audio-video modeling and fast autoregressive generation. To ease joint audio-video optimization, we adopt a two-stage training strategy: we first train uni-modal generators and then couple them into a unified audio-video model for joint training on paired data. For streaming generation, we ask whether a native fast causal audio-video model can be trained directly, instead of following existing streaming distillation pipelines that typically train a bidirectional model first and then convert it into a causal generator through multiple distillation stages. Our answer is Mutual Forcing, which builds directly on native autoregressive model and integrates few-step and multi-step generation within a single weight-shared model, enabling self-distillation and improved training-inference consistency. The multi-step mode improves the few-step mode via self-distillation, while the few-step mode generates historical context during training to improve training-inference consistency; because the two modes share parameters, these two effects reinforce each other within a single model. Compared with prior approaches such as Self-Forcing, Mutual Forcing removes the need for an additional bidirectional teacher model, supports more flexible training sequence lengths, reduces training overhead, and allows the model to improve directly from real paired data rather than a fixed teacher. Experiments show that Mutual Forcing matches or surpasses strong baselines that require around 50 sampling steps while using only 4 to 8 steps, demonstrating substantial advantages in both efficiency and quality. The project page is available at https://mutualforcing.github.io.
ViLaD: A Large Vision Language Diffusion Framework for End-to-End Autonomous Driving
Aug 18, 2025End-to-end autonomous driving systems built on Vision Language Models (VLMs) have shown significant promise, yet their reliance on autoregressive architectures introduces some limitations for real-world applications. The sequential, token-by-token generation process of these models results in high inference latency and cannot perform bidirectional reasoning, making them unsuitable for dynamic, safety-critical environments. To overcome these challenges, we introduce ViLaD, a novel Large Vision Language Diffusion (LVLD) framework for end-to-end autonomous driving that represents a paradigm shift. ViLaD leverages a masked diffusion model that enables parallel generation of entire driving decision sequences, significantly reducing computational latency. Moreover, its architecture supports bidirectional reasoning, allowing the model to consider both past and future simultaneously, and supports progressive easy-first generation to iteratively improve decision quality. We conduct comprehensive experiments on the nuScenes dataset, where ViLaD outperforms state-of-the-art autoregressive VLM baselines in both planning accuracy and inference speed, while achieving a near-zero failure rate. Furthermore, we demonstrate the framework's practical viability through a real-world deployment on an autonomous vehicle for an interactive parking task, confirming its effectiveness and soundness for practical applications.
Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
Jul 23, 2025
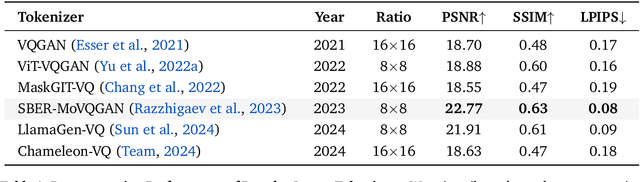
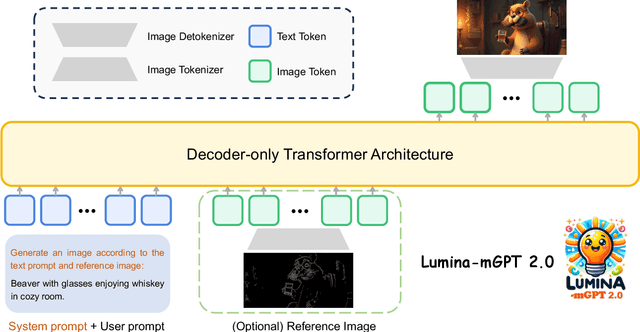

We present Lumina-mGPT 2.0, a stand-alone, decoder-only autoregressive model that revisits and revitalizes the autoregressive paradigm for high-quality image generation and beyond. Unlike existing approaches that rely on pretrained components or hybrid architectures, Lumina-mGPT 2.0 is trained entirely from scratch, enabling unrestricted architectural design and licensing freedom. It achieves generation quality on par with state-of-the-art diffusion models such as DALL-E 3 and SANA, while preserving the inherent flexibility and compositionality of autoregressive modeling. Our unified tokenization scheme allows the model to seamlessly handle a wide spectrum of tasks-including subject-driven generation, image editing, controllable synthesis, and dense prediction-within a single generative framework. To further boost usability, we incorporate efficient decoding strategies like inference-time scaling and speculative Jacobi sampling to improve quality and speed, respectively. Extensive evaluations on standard text-to-image benchmarks (e.g., GenEval, DPG) demonstrate that Lumina-mGPT 2.0 not only matches but in some cases surpasses diffusion-based models. Moreover, we confirm its multi-task capabilities on the Graph200K benchmark, with the native Lumina-mGPT 2.0 performing exceptionally well. These results position Lumina-mGPT 2.0 as a strong, flexible foundation model for unified multimodal generation. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-mGPT-2.0.
A Hierarchical Test Platform for Vision Language Model (VLM)-Integrated Real-World Autonomous Driving
Jun 17, 2025Vision-Language Models (VLMs) have demonstrated notable promise in autonomous driving by offering the potential for multimodal reasoning through pretraining on extensive image-text pairs. However, adapting these models from broad web-scale data to the safety-critical context of driving presents a significant challenge, commonly referred to as domain shift. Existing simulation-based and dataset-driven evaluation methods, although valuable, often fail to capture the full complexity of real-world scenarios and cannot easily accommodate repeatable closed-loop testing with flexible scenario manipulation. In this paper, we introduce a hierarchical real-world test platform specifically designed to evaluate VLM-integrated autonomous driving systems. Our approach includes a modular, low-latency on-vehicle middleware that allows seamless incorporation of various VLMs, a clearly separated perception-planning-control architecture that can accommodate both VLM-based and conventional modules, and a configurable suite of real-world testing scenarios on a closed track that facilitates controlled yet authentic evaluations. We demonstrate the effectiveness of the proposed platform`s testing and evaluation ability with a case study involving a VLM-enabled autonomous vehicle, highlighting how our test framework supports robust experimentation under diverse conditions.
AR-1-to-3: Single Image to Consistent 3D Object Generation via Next-View Prediction
Mar 17, 2025Novel view synthesis (NVS) is a cornerstone for image-to-3d creation. However, existing works still struggle to maintain consistency between the generated views and the input views, especially when there is a significant camera pose difference, leading to poor-quality 3D geometries and textures. We attribute this issue to their treatment of all target views with equal priority according to our empirical observation that the target views closer to the input views exhibit higher fidelity. With this inspiration, we propose AR-1-to-3, a novel next-view prediction paradigm based on diffusion models that first generates views close to the input views, which are then utilized as contextual information to progressively synthesize farther views. To encode the generated view subsequences as local and global conditions for the next-view prediction, we accordingly develop a stacked local feature encoding strategy (Stacked-LE) and an LSTM-based global feature encoding strategy (LSTM-GE). Extensive experiments demonstrate that our method significantly improves the consistency between the generated views and the input views, producing high-fidelity 3D assets.
On-Board Vision-Language Models for Personalized Autonomous Vehicle Motion Control: System Design and Real-World Validation
Nov 17, 2024



Personalized driving refers to an autonomous vehicle's ability to adapt its driving behavior or control strategies to match individual users' preferences and driving styles while maintaining safety and comfort standards. However, existing works either fail to capture every individual preference precisely or become computationally inefficient as the user base expands. Vision-Language Models (VLMs) offer promising solutions to this front through their natural language understanding and scene reasoning capabilities. In this work, we propose a lightweight yet effective on-board VLM framework that provides low-latency personalized driving performance while maintaining strong reasoning capabilities. Our solution incorporates a Retrieval-Augmented Generation (RAG)-based memory module that enables continuous learning of individual driving preferences through human feedback. Through comprehensive real-world vehicle deployment and experiments, our system has demonstrated the ability to provide safe, comfortable, and personalized driving experiences across various scenarios and significantly reduce takeover rates by up to 76.9%. To the best of our knowledge, this work represents the first end-to-end VLM-based motion control system in real-world autonomous vehicles.
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
May 02, 2024For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge. In this paper, we propose a new way of self-attention calculation, termed Consistent Self-Attention, that significantly boosts the consistency between the generated images and augments prevalent pretrained diffusion-based text-to-image models in a zero-shot manner. To extend our method to long-range video generation, we further introduce a novel semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are significantly more stable than the modules based on latent spaces only, especially in the context of long video generation. By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents. The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from the aspect of architectural modifications. Our code is made publicly available at https://github.com/HVision-NKU/StoryDiffusion.
Large Language Models for Autonomous Driving: Real-World Experiments
Dec 14, 2023Autonomous driving systems are increasingly popular in today's technological landscape, where vehicles with partial automation have already been widely available on the market, and the full automation era with ``driverless'' capabilities is near the horizon. However, accurately understanding humans' commands, particularly for autonomous vehicles that have only passengers instead of drivers, and achieving a high level of personalization remain challenging tasks in the development of autonomous driving systems. In this paper, we introduce a Large Language Model (LLM)-based framework Talk-to-Drive (Talk2Drive) to process verbal commands from humans and make autonomous driving decisions with contextual information, satisfying their personalized preferences for safety, efficiency, and comfort. First, a speech recognition module is developed for Talk2Drive to interpret verbal inputs from humans to textual instructions, which are then sent to LLMs for reasoning. Then, appropriate commands for the Electrical Control Unit (ECU) are generated, achieving a 100\% success rate in executing codes. Real-world experiments show that our framework can substantially reduce the takeover rate for a diverse range of drivers by up to 90.1\%. To the best of our knowledge, Talk2Drive marks the first instance of employing an LLM-based system in a real-world autonomous driving environment.
MaskDiffusion: Boosting Text-to-Image Consistency with Conditional Mask
Sep 08, 2023



Recent advancements in diffusion models have showcased their impressive capacity to generate visually striking images. Nevertheless, ensuring a close match between the generated image and the given prompt remains a persistent challenge. In this work, we identify that a crucial factor leading to the text-image mismatch issue is the inadequate cross-modality relation learning between the prompt and the output image. To better align the prompt and image content, we advance the cross-attention with an adaptive mask, which is conditioned on the attention maps and the prompt embeddings, to dynamically adjust the contribution of each text token to the image features. This mechanism explicitly diminishes the ambiguity in semantic information embedding from the text encoder, leading to a boost of text-to-image consistency in the synthesized images. Our method, termed MaskDiffusion, is training-free and hot-pluggable for popular pre-trained diffusion models. When applied to the latent diffusion models, our MaskDiffusion can significantly improve the text-to-image consistency with negligible computation overhead compared to the original diffusion models.
SRFormer: Permuted Self-Attention for Single Image Super-Resolution
Mar 17, 2023Previous works have shown that increasing the window size for Transformer-based image super-resolution models (e.g., SwinIR) can significantly improve the model performance but the computation overhead is also considerable. In this paper, we present SRFormer, a simple but novel method that can enjoy the benefit of large window self-attention but introduces even less computational burden. The core of our SRFormer is the permuted self-attention (PSA), which strikes an appropriate balance between the channel and spatial information for self-attention. Our PSA is simple and can be easily applied to existing super-resolution networks based on window self-attention. Without any bells and whistles, we show that our SRFormer achieves a 33.86dB PSNR score on the Urban100 dataset, which is 0.46dB higher than that of SwinIR but uses fewer parameters and computations. We hope our simple and effective approach can serve as a useful tool for future research in super-resolution model design.