 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRational Communication Shapes Morphological Composition
May 05, 2026Human languages expand vocabularies by combining existing morphemes rather than inventing arbitrary forms. Communicative efficiency shapes lexical systems at multiple levels (Gibson et al., 2019), yet morphological composition -- combining morphemes through compounding or affixation -- has rarely been modeled as a historically situated speaker choice among competing morpheme sequences, leaving unanswered why a language settles on one morpheme combination over other plausible alternatives. We ask whether a trade-off between listener recoverability and speaker production cost can predict attested compositions over contemporaneously available alternatives. Here we show, within the Rational Speech Act (RSA) framework (Frank & Goodman, 2012; Goodman & Frank, 2016) using a time-indexed lexicon constructed from Corpus of Historical American English (COHA) and Corpus of Contemporary American English (COCA), that across 4323 naturally occurring English compounds and derivations spanning 1820--2019, attested compositions are systematically ranked above unattested alternatives generated from contemporaneously available morphemes. Models integrating semantic informativeness with production cost outperform semantic-only and cost-only baselines on Mean Reciprocal Rank (MRR) and top-k accuracy (Acc@k), with the advantage of the Pragmatic Speaker model ($S_1$) over the semantic-only baseline growing as the candidate set expands, where meaning alone leaves morphological choice underdetermined. These findings suggest that lexicalization reflects a communicative trade-off between expressiveness and efficiency, extending rational accounts of communication from utterance-level choice to the internal structure of words.
Grounding Before Generalizing: How AI Differs from Humans in Causal Transfer
Apr 27, 2026Extracting abstract causal structures and applying them to novel situations is a hallmark of human intelligence. While Large Language Models (LLMs) and Vision Language Models (VLMs) have shown strong performance on a wide range of reasoning tasks, their capacity for interactive causal learning -- inducing latent structures through sequential exploration and transferring them across contexts -- remains uncharacterized. Human learners accomplish such transfer after minimal exposure, whereas classical Reinforcement Learning (RL) agents fail catastrophically. Whether state-of-the-art Artificial Intelligence (AI) models possess human-like mechanisms for abstract causal structure transfer is an open question. Using the OpenLock paradigm requiring sequential discovery of Common Cause (CC) and Common Effect (CE) structures, here we show that models exhibit fundamentally delayed or absent transfer: even successful models require initial environmental-specific mapping -- what we term environmental grounding -- before efficiency gains emerge, whereas humans leverage prior structural knowledge from the very first solution attempt. In the text-only condition, models matched or exceeded human discovery efficiency. In contrast, visual information -- in both the image-only and text-and-image conditions -- overall degraded rather than enhanced performance, revealing a broad reliance on symbolic processing rather than integrated multimodal reasoning. Models further exhibited systematic CC/CE asymmetries absent in humans, suggesting heuristic biases rather than direction-neutral causal abstraction. These findings reveal that large-scale statistical learning does not produce the decontextualized causal schemas underpinning human analogical reasoning, establishing grounding-dependent transfer as a fundamental limitation of current LLMs and VLMs.
Probing and Inducing Combinational Creativity in Vision-Language Models
Apr 17, 2025The ability to combine existing concepts into novel ideas stands as a fundamental hallmark of human intelligence. Recent advances in Vision-Language Models (VLMs) like GPT-4V and DALLE-3 have sparked debate about whether their outputs reflect combinational creativity--defined by M. A. Boden (1998) as synthesizing novel ideas through combining existing concepts--or sophisticated pattern matching of training data. Drawing inspiration from cognitive science, we investigate the combinational creativity of VLMs from the lens of concept blending. We propose the Identification-Explanation-Implication (IEI) framework, which decomposes creative processes into three levels: identifying input spaces, extracting shared attributes, and deriving novel semantic implications. To validate this framework, we curate CreativeMashup, a high-quality dataset of 666 artist-generated visual mashups annotated according to the IEI framework. Through extensive experiments, we demonstrate that in comprehension tasks, best VLMs have surpassed average human performance while falling short of expert-level understanding; in generation tasks, incorporating our IEI framework into the generation pipeline significantly enhances the creative quality of VLMs outputs. Our findings establish both a theoretical foundation for evaluating artificial creativity and practical guidelines for improving creative generation in VLMs.
A simulation-heuristics dual-process model for intuitive physics
Apr 13, 2025

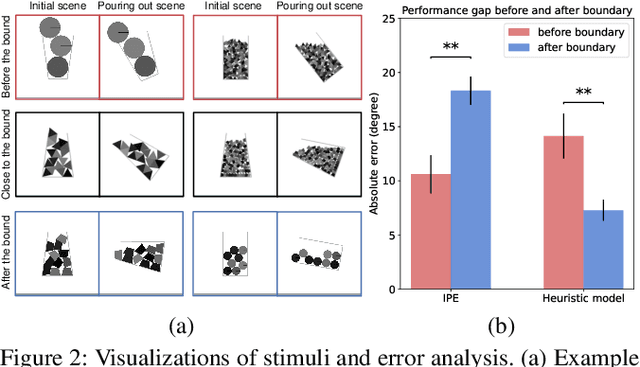
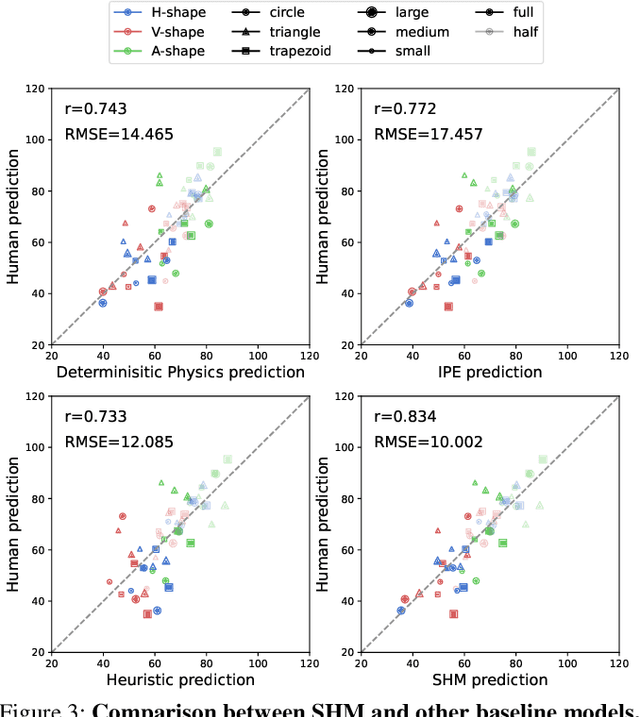
The role of mental simulation in human physical reasoning is widely acknowledged, but whether it is employed across scenarios with varying simulation costs and where its boundary lies remains unclear. Using a pouring-marble task, our human study revealed two distinct error patterns when predicting pouring angles, differentiated by simulation time. While mental simulation accurately captured human judgments in simpler scenarios, a linear heuristic model better matched human predictions when simulation time exceeded a certain boundary. Motivated by these observations, we propose a dual-process framework, Simulation-Heuristics Model (SHM), where intuitive physics employs simulation for short-time simulation but switches to heuristics when simulation becomes costly. By integrating computational methods previously viewed as separate into a unified model, SHM quantitatively captures their switching mechanism. The SHM aligns more precisely with human behavior and demonstrates consistent predictive performance across diverse scenarios, advancing our understanding of the adaptive nature of intuitive physical reasoning.
Word Embeddings Track Social Group Changes Across 70 Years in China
Apr 12, 2025Language encodes societal beliefs about social groups through word patterns. While computational methods like word embeddings enable quantitative analysis of these patterns, studies have primarily examined gradual shifts in Western contexts. We present the first large-scale computational analysis of Chinese state-controlled media (1950-2019) to examine how revolutionary social transformations are reflected in official linguistic representations of social groups. Using diachronic word embeddings at multiple temporal resolutions, we find that Chinese representations differ significantly from Western counterparts, particularly regarding economic status, ethnicity, and gender. These representations show distinct evolutionary dynamics: while stereotypes of ethnicity, age, and body type remain remarkably stable across political upheavals, representations of gender and economic classes undergo dramatic shifts tracking historical transformations. This work advances our understanding of how officially sanctioned discourse encodes social structure through language while highlighting the importance of non-Western perspectives in computational social science.
Benchmark of Segmentation Techniques for Pelvic Fracture in CT and X-ray: Summary of the PENGWIN 2024 Challenge
Apr 03, 2025The segmentation of pelvic fracture fragments in CT and X-ray images is crucial for trauma diagnosis, surgical planning, and intraoperative guidance. However, accurately and efficiently delineating the bone fragments remains a significant challenge due to complex anatomy and imaging limitations. The PENGWIN challenge, organized as a MICCAI 2024 satellite event, aimed to advance automated fracture segmentation by benchmarking state-of-the-art algorithms on these complex tasks. A diverse dataset of 150 CT scans was collected from multiple clinical centers, and a large set of simulated X-ray images was generated using the DeepDRR method. Final submissions from 16 teams worldwide were evaluated under a rigorous multi-metric testing scheme. The top-performing CT algorithm achieved an average fragment-wise intersection over union (IoU) of 0.930, demonstrating satisfactory accuracy. However, in the X-ray task, the best algorithm attained an IoU of 0.774, highlighting the greater challenges posed by overlapping anatomical structures. Beyond the quantitative evaluation, the challenge revealed methodological diversity in algorithm design. Variations in instance representation, such as primary-secondary classification versus boundary-core separation, led to differing segmentation strategies. Despite promising results, the challenge also exposed inherent uncertainties in fragment definition, particularly in cases of incomplete fractures. These findings suggest that interactive segmentation approaches, integrating human decision-making with task-relevant information, may be essential for improving model reliability and clinical applicability.
Proposing and solving olympiad geometry with guided tree search
Dec 14, 2024Mathematics olympiads are prestigious competitions, with problem proposing and solving highly honored. Building artificial intelligence that proposes and solves olympiads presents an unresolved challenge in automated theorem discovery and proving, especially in geometry for its combination of numerical and spatial elements. We introduce TongGeometry, a Euclidean geometry system supporting tree-search-based guided problem proposing and solving. The efficient geometry system establishes the most extensive repository of geometry theorems to date: within the same computational budget as the existing state-of-the-art, TongGeometry discovers 6.7 billion geometry theorems requiring auxiliary constructions, including 4.1 billion exhibiting geometric symmetry. Among them, 10 theorems were proposed to regional mathematical olympiads with 3 of TongGeometry's proposals selected in real competitions, earning spots in a national team qualifying exam or a top civil olympiad in China and the US. Guided by fine-tuned large language models, TongGeometry solved all International Mathematical Olympiad geometry in IMO-AG-30, outperforming gold medalists for the first time. It also surpasses the existing state-of-the-art across a broader spectrum of olympiad-level problems. The full capabilities of the system can be utilized on a consumer-grade machine, making the model more accessible and fostering widespread democratization of its use. By analogy, unlike existing systems that merely solve problems like students, TongGeometry acts like a geometry coach, discovering, presenting, and proving theorems.
Evaluating and Modeling Social Intelligence: A Comparative Study of Human and AI Capabilities
May 20, 2024



Facing the current debate on whether Large Language Models (LLMs) attain near-human intelligence levels (Mitchell & Krakauer, 2023; Bubeck et al., 2023; Kosinski, 2023; Shiffrin & Mitchell, 2023; Ullman, 2023), the current study introduces a benchmark for evaluating social intelligence, one of the most distinctive aspects of human cognition. We developed a comprehensive theoretical framework for social dynamics and introduced two evaluation tasks: Inverse Reasoning (IR) and Inverse Inverse Planning (IIP). Our approach also encompassed a computational model based on recursive Bayesian inference, adept at elucidating diverse human behavioral patterns. Extensive experiments and detailed analyses revealed that humans surpassed the latest GPT models in overall performance, zero-shot learning, one-shot generalization, and adaptability to multi-modalities. Notably, GPT models demonstrated social intelligence only at the most basic order (order = 0), in stark contrast to human social intelligence (order >= 2). Further examination indicated a propensity of LLMs to rely on pattern recognition for shortcuts, casting doubt on their possession of authentic human-level social intelligence. Our codes, dataset, appendix and human data are released at https://github.com/bigai-ai/Evaluate-n-Model-Social-Intelligence.
Brain in a Vat: On Missing Pieces Towards Artificial General Intelligence in Large Language Models
Jul 07, 2023In this perspective paper, we first comprehensively review existing evaluations of Large Language Models (LLMs) using both standardized tests and ability-oriented benchmarks. We pinpoint several problems with current evaluation methods that tend to overstate the capabilities of LLMs. We then articulate what artificial general intelligence should encompass beyond the capabilities of LLMs. We propose four characteristics of generally intelligent agents: 1) they can perform unlimited tasks; 2) they can generate new tasks within a context; 3) they operate based on a value system that underpins task generation; and 4) they have a world model reflecting reality, which shapes their interaction with the world. Building on this viewpoint, we highlight the missing pieces in artificial general intelligence, that is, the unity of knowing and acting. We argue that active engagement with objects in the real world delivers more robust signals for forming conceptual representations. Additionally, knowledge acquisition isn't solely reliant on passive input but requires repeated trials and errors. We conclude by outlining promising future research directions in the field of artificial general intelligence.
XBound-Former: Toward Cross-scale Boundary Modeling in Transformers
Jun 02, 2022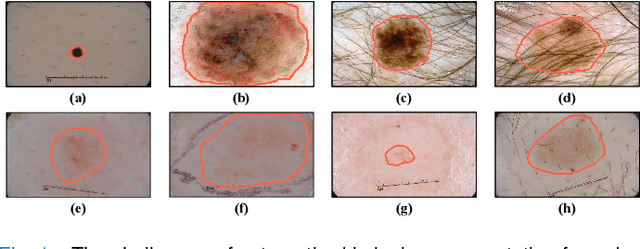
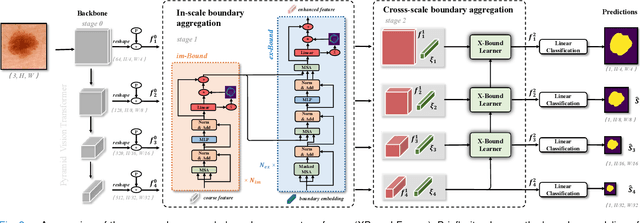
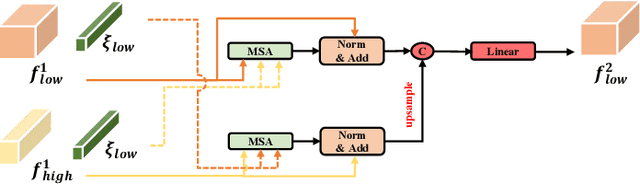
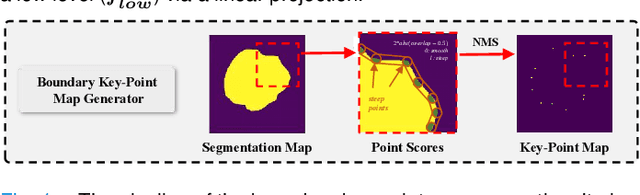
Skin lesion segmentation from dermoscopy images is of great significance in the quantitative analysis of skin cancers, which is yet challenging even for dermatologists due to the inherent issues, i.e., considerable size, shape and color variation, and ambiguous boundaries. Recent vision transformers have shown promising performance in handling the variation through global context modeling. Still, they have not thoroughly solved the problem of ambiguous boundaries as they ignore the complementary usage of the boundary knowledge and global contexts. In this paper, we propose a novel cross-scale boundary-aware transformer, \textbf{XBound-Former}, to simultaneously address the variation and boundary problems of skin lesion segmentation. XBound-Former is a purely attention-based network and catches boundary knowledge via three specially designed learners. We evaluate the model on two skin lesion datasets, ISIC-2016\&PH$^2$ and ISIC-2018, where our model consistently outperforms other convolution- and transformer-based models, especially on the boundary-wise metrics. We extensively verify the generalization ability of polyp lesion segmentation that has similar characteristics, and our model can also yield significant improvement compared to the latest models.