 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAM-LLM: A Modular, Open-Source Multimodal Large Language Model Framework and Best Practice for Speech, Language, Audio and Music Processing
Jan 14, 2026The recent surge in open-source Multimodal Large Language Models (MLLM) frameworks, such as LLaVA, provides a convenient kickoff for artificial intelligence developers and researchers. However, most of the MLLM frameworks take vision as the main input modality, and provide limited in-depth support for the modality of speech, audio, and music. This situation hinders the development of audio-language models, and forces researchers to spend a lot of effort on code writing and hyperparameter tuning. We present SLAM-LLM, an open-source deep learning framework designed to train customized MLLMs, focused on speech, language, audio, and music processing. SLAM-LLM provides a modular configuration of different encoders, projectors, LLMs, and parameter-efficient fine-tuning plugins. SLAM-LLM also includes detailed training and inference recipes for mainstream tasks, along with high-performance checkpoints like LLM-based Automatic Speech Recognition (ASR), Automated Audio Captioning (AAC), and Music Captioning (MC). Some of these recipes have already reached or are nearing state-of-the-art performance, and some relevant techniques have also been accepted by academic papers. We hope SLAM-LLM will accelerate iteration, development, data engineering, and model training for researchers. We are committed to continually pushing forward audio-based MLLMs through this open-source framework, and call on the community to contribute to the LLM-based speech, audio and music processing.
PodEval: A Multimodal Evaluation Framework for Podcast Audio Generation
Oct 01, 2025Recently, an increasing number of multimodal (text and audio) benchmarks have emerged, primarily focusing on evaluating models' understanding capability. However, exploration into assessing generative capabilities remains limited, especially for open-ended long-form content generation. Significant challenges lie in no reference standard answer, no unified evaluation metrics and uncontrollable human judgments. In this work, we take podcast-like audio generation as a starting point and propose PodEval, a comprehensive and well-designed open-source evaluation framework. In this framework: 1) We construct a real-world podcast dataset spanning diverse topics, serving as a reference for human-level creative quality. 2) We introduce a multimodal evaluation strategy and decompose the complex task into three dimensions: text, speech and audio, with different evaluation emphasis on "Content" and "Format". 3) For each modality, we design corresponding evaluation methods, involving both objective metrics and subjective listening test. We leverage representative podcast generation systems (including open-source, close-source, and human-made) in our experiments. The results offer in-depth analysis and insights into podcast generation, demonstrating the effectiveness of PodEval in evaluating open-ended long-form audio. This project is open-source to facilitate public use: https://github.com/yujxx/PodEval.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025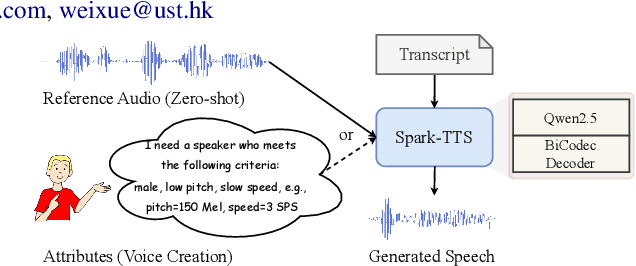



Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
Audio-FLAN: A Preliminary Release
Feb 23, 2025

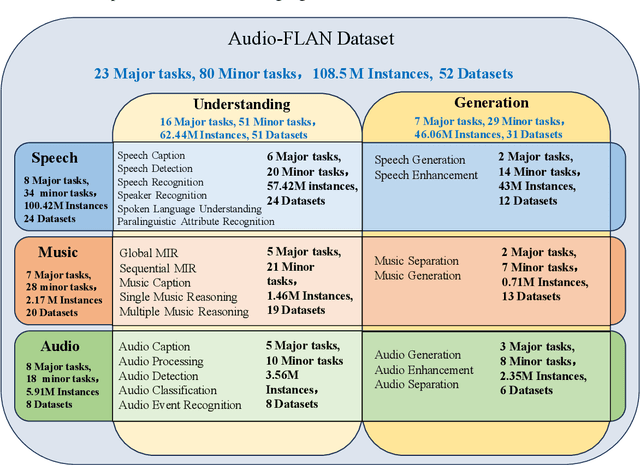

Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Feb 06, 2025Recent advances in text-based large language models (LLMs), particularly in the GPT series and the o1 model, have demonstrated the effectiveness of scaling both training-time and inference-time compute. However, current state-of-the-art TTS systems leveraging LLMs are often multi-stage, requiring separate models (e.g., diffusion models after LLM), complicating the decision of whether to scale a particular model during training or testing. This work makes the following contributions: First, we explore the scaling of train-time and inference-time compute for speech synthesis. Second, we propose a simple framework Llasa for speech synthesis that employs a single-layer vector quantizer (VQ) codec and a single Transformer architecture to fully align with standard LLMs such as Llama. Our experiments reveal that scaling train-time compute for Llasa consistently improves the naturalness of synthesized speech and enables the generation of more complex and accurate prosody patterns. Furthermore, from the perspective of scaling inference-time compute, we employ speech understanding models as verifiers during the search, finding that scaling inference-time compute shifts the sampling modes toward the preferences of specific verifiers, thereby improving emotional expressiveness, timbre consistency, and content accuracy. In addition, we released the checkpoint and training code for our TTS model (1B, 3B, 8B) and codec model publicly available.
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge: Tasks, Results and Findings
Oct 31, 2024



The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge aims to benchmark and advance zero-shot spontaneous style voice cloning, particularly focusing on generating spontaneous behaviors in conversational speech. The challenge comprises two tracks: an unconstrained track without limitation on data and model usage, and a constrained track only allowing the use of constrained open-source datasets. A 100-hour high-quality conversational speech dataset is also made available with the challenge. This paper details the data, tracks, submitted systems, evaluation results, and findings.
Text-aware and Context-aware Expressive Audiobook Speech Synthesis
Jun 12, 2024Recent advances in text-to-speech have significantly improved the expressiveness of synthetic speech. However, a major challenge remains in generating speech that captures the diverse styles exhibited by professional narrators in audiobooks without relying on manually labeled data or reference speech. To address this problem, we propose a text-aware and context-aware(TACA) style modeling approach for expressive audiobook speech synthesis. We first establish a text-aware style space to cover diverse styles via contrastive learning with the supervision of the speech style. Meanwhile, we adopt a context encoder to incorporate cross-sentence information and the style embedding obtained from text. Finally, we introduce the context encoder to two typical TTS models, VITS-based TTS and language model-based TTS. Experimental results demonstrate that our proposed approach can effectively capture diverse styles and coherent prosody, and consequently improves naturalness and expressiveness in audiobook speech synthesis.
WenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark
Jun 11, 2024



With the development of large text-to-speech (TTS) models and scale-up of the training data, state-of-the-art TTS systems have achieved impressive performance. In this paper, we present WenetSpeech4TTS, a multi-domain Mandarin corpus derived from the open-sourced WenetSpeech dataset. Tailored for the text-to-speech tasks, we refined WenetSpeech by adjusting segment boundaries, enhancing the audio quality, and eliminating speaker mixing within each segment. Following a more accurate transcription process and quality-based data filtering process, the obtained WenetSpeech4TTS corpus contains $12,800$ hours of paired audio-text data. Furthermore, we have created subsets of varying sizes, categorized by segment quality scores to allow for TTS model training and fine-tuning. VALL-E and NaturalSpeech 2 systems are trained and fine-tuned on these subsets to validate the usability of WenetSpeech4TTS, establishing baselines on benchmark for fair comparison of TTS systems. The corpus and corresponding benchmarks are publicly available on huggingface.
Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation
Jun 11, 2024



The multi-codebook speech codec enables the application of large language models (LLM) in TTS but bottlenecks efficiency and robustness due to multi-sequence prediction. To avoid this obstacle, we propose Single-Codec, a single-codebook single-sequence codec, which employs a disentangled VQ-VAE to decouple speech into a time-invariant embedding and a phonetically-rich discrete sequence. Furthermore, the encoder is enhanced with 1) contextual modeling with a BLSTM module to exploit the temporal information, 2) a hybrid sampling module to alleviate distortion from upsampling and downsampling, and 3) a resampling module to encourage discrete units to carry more phonetic information. Compared with multi-codebook codecs, e.g., EnCodec and TiCodec, Single-Codec demonstrates higher reconstruction quality with a lower bandwidth of only 304bps. The effectiveness of Single-Code is further validated by LLM-TTS experiments, showing improved naturalness and intelligibility.