 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Mitigating Inconsistency in Discrete Audio Tokens for Neural Codec Language Models
Sep 28, 2024



Building upon advancements in Large Language Models (LLMs), the field of audio processing has seen increased interest in training audio generation tasks with discrete audio token sequences. However, directly discretizing audio by neural audio codecs often results in sequences that fundamentally differ from text sequences. Unlike text, where text token sequences are deterministic, discrete audio tokens can exhibit significant variability based on contextual factors, while still producing perceptually identical audio segments. We refer to this phenomenon as \textbf{Discrete Representation Inconsistency (DRI)}. This inconsistency can lead to a single audio segment being represented by multiple divergent sequences, which creates confusion in neural codec language models and results in omissions and repetitions during speech generation. In this paper, we quantitatively analyze the DRI phenomenon within popular audio tokenizers such as EnCodec. Our approach effectively mitigates the DRI phenomenon of the neural audio codec. Furthermore, extensive experiments on the neural codec language model over LibriTTS and large-scale MLS datases (44,000 hours) demonstrate the effectiveness and generality of our method. The demo of audio samples is available online~\footnote{\url{https://consistencyinneuralcodec.github.io}}.
Qwen2-Audio Technical Report
Jul 15, 2024We introduce the latest progress of Qwen-Audio, a large-scale audio-language model called Qwen2-Audio, which is capable of accepting various audio signal inputs and performing audio analysis or direct textual responses with regard to speech instructions. In contrast to complex hierarchical tags, we have simplified the pre-training process by utilizing natural language prompts for different data and tasks, and have further expanded the data volume. We have boosted the instruction-following capability of Qwen2-Audio and implemented two distinct audio interaction modes for voice chat and audio analysis. In the voice chat mode, users can freely engage in voice interactions with Qwen2-Audio without text input. In the audio analysis mode, users could provide audio and text instructions for analysis during the interaction. Note that we do not use any system prompts to switch between voice chat and audio analysis modes. Qwen2-Audio is capable of intelligently comprehending the content within audio and following voice commands to respond appropriately. For instance, in an audio segment that simultaneously contains sounds, multi-speaker conversations, and a voice command, Qwen2-Audio can directly understand the command and provide an interpretation and response to the audio. Additionally, DPO has optimized the model's performance in terms of factuality and adherence to desired behavior. According to the evaluation results from AIR-Bench, Qwen2-Audio outperformed previous SOTAs, such as Gemini-1.5-pro, in tests focused on audio-centric instruction-following capabilities. Qwen2-Audio is open-sourced with the aim of fostering the advancement of the multi-modal language community.
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Jun 14, 2024

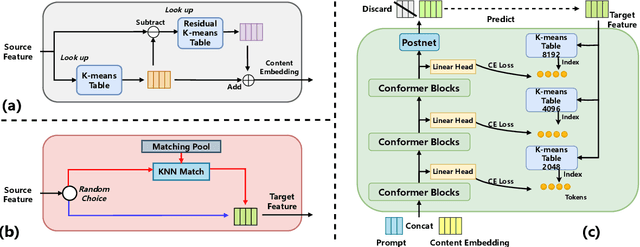

Zero-shot voice conversion (VC) aims to transform source speech into arbitrary unseen target voice while keeping the linguistic content unchanged. Recent VC methods have made significant progress, but semantic losses in the decoupling process as well as training-inference mismatch still hinder conversion performance. In this paper, we propose Vec-Tok-VC+, a novel prompt-based zero-shot VC model improved from Vec-Tok Codec, achieving voice conversion given only a 3s target speaker prompt. We design a residual-enhanced K-Means decoupler to enhance the semantic content extraction with a two-layer clustering process. Besides, we employ teacher-guided refinement to simulate the conversion process to eliminate the training-inference mismatch, forming a dual-mode training strategy. Furthermore, we design a multi-codebook progressive loss function to constrain the layer-wise output of the model from coarse to fine to improve speaker similarity and content accuracy. Objective and subjective evaluations demonstrate that Vec-Tok-VC+ outperforms the strong baselines in naturalness, intelligibility, and speaker similarity.
FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter
Jun 12, 2024



Vocoders reconstruct speech waveforms from acoustic features and play a pivotal role in modern TTS systems. Frequent-domain GAN vocoders like Vocos and APNet2 have recently seen rapid advancements, outperforming time-domain models in inference speed while achieving comparable audio quality. However, these frequency-domain vocoders suffer from large parameter sizes, thus introducing extra memory burden. Inspired by PriorGrad and SpecGrad, we employ pseudo-inverse to estimate the amplitude spectrum as the initialization roughly. This simple initialization significantly mitigates the parameter demand for vocoder. Based on APNet2 and our streamlined Amplitude prediction branch, we propose our FreeV, compared with its counterpart APNet2, our FreeV achieves 1.8 times inference speed improvement with nearly half parameters. Meanwhile, our FreeV outperforms APNet2 in resynthesis quality, marking a step forward in pursuing real-time, high-fidelity speech synthesis. Code and checkpoints is available at: https://github.com/BakerBunker/FreeV
RaD-Net 2: A causal two-stage repairing and denoising speech enhancement network with knowledge distillation and complex axial self-attention
Jun 11, 2024



In real-time speech communication systems, speech signals are often degraded by multiple distortions. Recently, a two-stage Repair-and-Denoising network (RaD-Net) was proposed with superior speech quality improvement in the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. However, failure to use future information and constraint receptive field of convolution layers limit the system's performance. To mitigate these problems, we extend RaD-Net to its upgraded version, RaD-Net 2. Specifically, a causality-based knowledge distillation is introduced in the first stage to use future information in a causal way. We use the non-causal repairing network as the teacher to improve the performance of the causal repairing network. In addition, in the second stage, complex axial self-attention is applied in the denoising network's complex feature encoder/decoder. Experimental results on the ICASSP 2024 SSI Challenge blind test set show that RaD-Net 2 brings 0.10 OVRL DNSMOS improvement compared to RaD-Net.
Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation
Jun 11, 2024



The multi-codebook speech codec enables the application of large language models (LLM) in TTS but bottlenecks efficiency and robustness due to multi-sequence prediction. To avoid this obstacle, we propose Single-Codec, a single-codebook single-sequence codec, which employs a disentangled VQ-VAE to decouple speech into a time-invariant embedding and a phonetically-rich discrete sequence. Furthermore, the encoder is enhanced with 1) contextual modeling with a BLSTM module to exploit the temporal information, 2) a hybrid sampling module to alleviate distortion from upsampling and downsampling, and 3) a resampling module to encourage discrete units to carry more phonetic information. Compared with multi-codebook codecs, e.g., EnCodec and TiCodec, Single-Codec demonstrates higher reconstruction quality with a lower bandwidth of only 304bps. The effectiveness of Single-Code is further validated by LLM-TTS experiments, showing improved naturalness and intelligibility.
AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension
Feb 12, 2024



Recently, instruction-following audio-language models have received broad attention for human-audio interaction. However, the absence of benchmarks capable of evaluating audio-centric interaction capabilities has impeded advancements in this field. Previous models primarily focus on assessing different fundamental tasks, such as Automatic Speech Recognition (ASR), and lack an assessment of the open-ended generative capabilities centered around audio. Thus, it is challenging to track the progression in the Large Audio-Language Models (LALMs) domain and to provide guidance for future improvement. In this paper, we introduce AIR-Bench (\textbf{A}udio \textbf{I}nst\textbf{R}uction \textbf{Bench}mark), the first benchmark designed to evaluate the ability of LALMs to understand various types of audio signals (including human speech, natural sounds, and music), and furthermore, to interact with humans in the textual format. AIR-Bench encompasses two dimensions: \textit{foundation} and \textit{chat} benchmarks. The former consists of 19 tasks with approximately 19k single-choice questions, intending to inspect the basic single-task ability of LALMs. The latter one contains 2k instances of open-ended question-and-answer data, directly assessing the comprehension of the model on complex audio and its capacity to follow instructions. Both benchmarks require the model to generate hypotheses directly. We design a unified framework that leverages advanced language models, such as GPT-4, to evaluate the scores of generated hypotheses given the meta-information of the audio. Experimental results demonstrate a high level of consistency between GPT-4-based evaluation and human evaluation. By revealing the limitations of existing LALMs through evaluation results, AIR-Bench can provide insights into the direction of future research.
RaD-Net: A Repairing and Denoising Network for Speech Signal Improvement
Jan 09, 2024


This paper introduces our repairing and denoising network (RaD-Net) for the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. We extend our previous framework based on a two-stage network and propose an upgraded model. Specifically, we replace the repairing network with COM-Net from TEA-PSE. In addition, multi-resolution discriminators and multi-band discriminators are adopted in the training stage. Finally, we use a three-step training strategy to optimize our model. We submit two models with different sets of parameters to meet the RTF requirement of the two tracks. According to the official results, the proposed systems rank 2nd in track 1 and 3rd in track 2.
Vec-Tok Speech: speech vectorization and tokenization for neural speech generation
Oct 12, 2023



Language models (LMs) have recently flourished in natural language processing and computer vision, generating high-fidelity texts or images in various tasks. In contrast, the current speech generative models are still struggling regarding speech quality and task generalization. This paper presents Vec-Tok Speech, an extensible framework that resembles multiple speech generation tasks, generating expressive and high-fidelity speech. Specifically, we propose a novel speech codec based on speech vectors and semantic tokens. Speech vectors contain acoustic details contributing to high-fidelity speech reconstruction, while semantic tokens focus on the linguistic content of speech, facilitating language modeling. Based on the proposed speech codec, Vec-Tok Speech leverages an LM to undertake the core of speech generation. Moreover, Byte-Pair Encoding (BPE) is introduced to reduce the token length and bit rate for lower exposure bias and longer context coverage, improving the performance of LMs. Vec-Tok Speech can be used for intra- and cross-lingual zero-shot voice conversion (VC), zero-shot speaking style transfer text-to-speech (TTS), speech-to-speech translation (S2ST), speech denoising, and speaker de-identification and anonymization. Experiments show that Vec-Tok Speech, built on 50k hours of speech, performs better than other SOTA models. Code will be available at https://github.com/BakerBunker/VecTok .
SALT: Distinguishable Speaker Anonymization Through Latent Space Transformation
Oct 08, 2023



Speaker anonymization aims to conceal a speaker's identity without degrading speech quality and intelligibility. Most speaker anonymization systems disentangle the speaker representation from the original speech and achieve anonymization by averaging or modifying the speaker representation. However, the anonymized speech is subject to reduction in pseudo speaker distinctiveness, speech quality and intelligibility for out-of-distribution speaker. To solve this issue, we propose SALT, a Speaker Anonymization system based on Latent space Transformation. Specifically, we extract latent features by a self-supervised feature extractor and randomly sample multiple speakers and their weights, and then interpolate the latent vectors to achieve speaker anonymization. Meanwhile, we explore the extrapolation method to further extend the diversity of pseudo speakers. Experiments on Voice Privacy Challenge dataset show our system achieves a state-of-the-art distinctiveness metric while preserving speech quality and intelligibility. Our code and demo is availible at https://github.com/BakerBunker/SALT .