 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamLifting: A Plug-in Module Lifting MV Diffusion Models for 3D Asset Generation
Sep 09, 2025



The labor- and experience-intensive creation of 3D assets with physically based rendering (PBR) materials demands an autonomous 3D asset creation pipeline. However, most existing 3D generation methods focus on geometry modeling, either baking textures into simple vertex colors or leaving texture synthesis to post-processing with image diffusion models. To achieve end-to-end PBR-ready 3D asset generation, we present Lightweight Gaussian Asset Adapter (LGAA), a novel framework that unifies the modeling of geometry and PBR materials by exploiting multi-view (MV) diffusion priors from a novel perspective. The LGAA features a modular design with three components. Specifically, the LGAA Wrapper reuses and adapts network layers from MV diffusion models, which encapsulate knowledge acquired from billions of images, enabling better convergence in a data-efficient manner. To incorporate multiple diffusion priors for geometry and PBR synthesis, the LGAA Switcher aligns multiple LGAA Wrapper layers encapsulating different knowledge. Then, a tamed variational autoencoder (VAE), termed LGAA Decoder, is designed to predict 2D Gaussian Splatting (2DGS) with PBR channels. Finally, we introduce a dedicated post-processing procedure to effectively extract high-quality, relightable mesh assets from the resulting 2DGS. Extensive quantitative and qualitative experiments demonstrate the superior performance of LGAA with both text-and image-conditioned MV diffusion models. Additionally, the modular design enables flexible incorporation of multiple diffusion priors, and the knowledge-preserving scheme leads to efficient convergence trained on merely 69k multi-view instances. Our code, pre-trained weights, and the dataset used will be publicly available via our project page: https://zx-yin.github.io/dreamlifting/.
IGFuse: Interactive 3D Gaussian Scene Reconstruction via Multi-Scans Fusion
Aug 18, 2025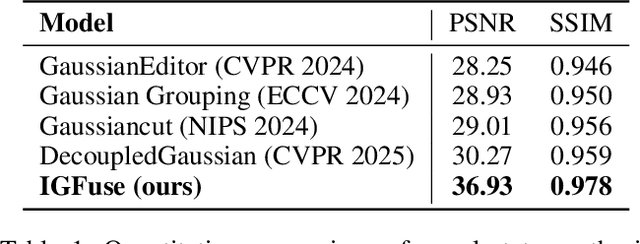
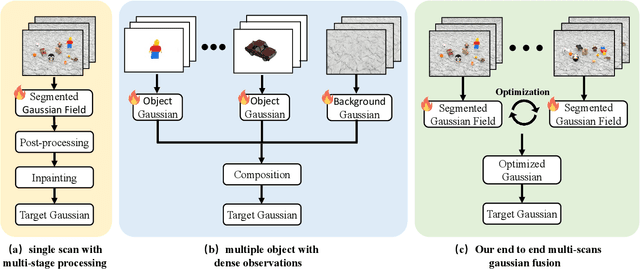
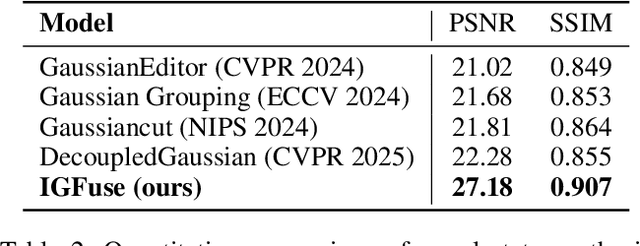
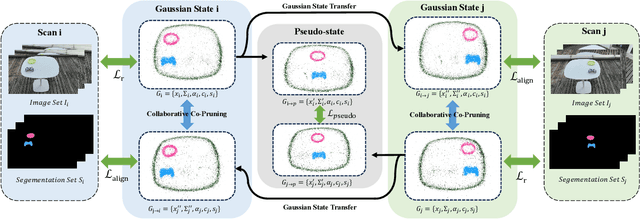
Reconstructing complete and interactive 3D scenes remains a fundamental challenge in computer vision and robotics, particularly due to persistent object occlusions and limited sensor coverage. Multiview observations from a single scene scan often fail to capture the full structural details. Existing approaches typically rely on multi stage pipelines, such as segmentation, background completion, and inpainting or require per-object dense scanning, both of which are error-prone, and not easily scalable. We propose IGFuse, a novel framework that reconstructs interactive Gaussian scene by fusing observations from multiple scans, where natural object rearrangement between captures reveal previously occluded regions. Our method constructs segmentation aware Gaussian fields and enforces bi-directional photometric and semantic consistency across scans. To handle spatial misalignments, we introduce a pseudo-intermediate scene state for unified alignment, alongside collaborative co-pruning strategies to refine geometry. IGFuse enables high fidelity rendering and object level scene manipulation without dense observations or complex pipelines. Extensive experiments validate the framework's strong generalization to novel scene configurations, demonstrating its effectiveness for real world 3D reconstruction and real-to-simulation transfer. Our project page is available online.
ArtGS:3D Gaussian Splatting for Interactive Visual-Physical Modeling and Manipulation of Articulated Objects
Jul 03, 2025Articulated object manipulation remains a critical challenge in robotics due to the complex kinematic constraints and the limited physical reasoning of existing methods. In this work, we introduce ArtGS, a novel framework that extends 3D Gaussian Splatting (3DGS) by integrating visual-physical modeling for articulated object understanding and interaction. ArtGS begins with multi-view RGB-D reconstruction, followed by reasoning with a vision-language model (VLM) to extract semantic and structural information, particularly the articulated bones. Through dynamic, differentiable 3DGS-based rendering, ArtGS optimizes the parameters of the articulated bones, ensuring physically consistent motion constraints and enhancing the manipulation policy. By leveraging dynamic Gaussian splatting, cross-embodiment adaptability, and closed-loop optimization, ArtGS establishes a new framework for efficient, scalable, and generalizable articulated object modeling and manipulation. Experiments conducted in both simulation and real-world environments demonstrate that ArtGS significantly outperforms previous methods in joint estimation accuracy and manipulation success rates across a variety of articulated objects. Additional images and videos are available on the project website: https://sites.google.com/view/artgs/home
From Long Videos to Engaging Clips: A Human-Inspired Video Editing Framework with Multimodal Narrative Understanding
Jul 03, 2025The rapid growth of online video content, especially on short video platforms, has created a growing demand for efficient video editing techniques that can condense long-form videos into concise and engaging clips. Existing automatic editing methods predominantly rely on textual cues from ASR transcripts and end-to-end segment selection, often neglecting the rich visual context and leading to incoherent outputs. In this paper, we propose a human-inspired automatic video editing framework (HIVE) that leverages multimodal narrative understanding to address these limitations. Our approach incorporates character extraction, dialogue analysis, and narrative summarization through multimodal large language models, enabling a holistic understanding of the video content. To further enhance coherence, we apply scene-level segmentation and decompose the editing process into three subtasks: highlight detection, opening/ending selection, and pruning of irrelevant content. To facilitate research in this area, we introduce DramaAD, a novel benchmark dataset comprising over 800 short drama episodes and 500 professionally edited advertisement clips. Experimental results demonstrate that our framework consistently outperforms existing baselines across both general and advertisement-oriented editing tasks, significantly narrowing the quality gap between automatic and human-edited videos.
Research on Graph-Retrieval Augmented Generation Based on Historical Text Knowledge Graphs
Jun 18, 2025



This article addresses domain knowledge gaps in general large language models for historical text analysis in the context of computational humanities and AIGC technology. We propose the Graph RAG framework, combining chain-of-thought prompting, self-instruction generation, and process supervision to create a The First Four Histories character relationship dataset with minimal manual annotation. This dataset supports automated historical knowledge extraction, reducing labor costs. In the graph-augmented generation phase, we introduce a collaborative mechanism between knowledge graphs and retrieval-augmented generation, improving the alignment of general models with historical knowledge. Experiments show that the domain-specific model Xunzi-Qwen1.5-14B, with Simplified Chinese input and chain-of-thought prompting, achieves optimal performance in relation extraction (F1 = 0.68). The DeepSeek model integrated with GraphRAG improves F1 by 11% (0.08-0.19) on the open-domain C-CLUE relation extraction dataset, surpassing the F1 value of Xunzi-Qwen1.5-14B (0.12), effectively alleviating hallucinations phenomenon, and improving interpretability. This framework offers a low-resource solution for classical text knowledge extraction, advancing historical knowledge services and humanities research.
Re-Initialization Token Learning for Tool-Augmented Large Language Models
Jun 17, 2025



Large language models have demonstrated exceptional performance, yet struggle with complex tasks such as numerical reasoning, plan generation. Integrating external tools, such as calculators and databases, into large language models (LLMs) is crucial for enhancing problem-solving capabilities. Current methods assign a unique token to each tool, enabling LLMs to call tools through token prediction-similar to word generation. However, this approach fails to account for the relationship between tool and word tokens, limiting adaptability within pre-trained LLMs. To address this issue, we propose a novel token learning method that aligns tool tokens with the existing word embedding space from the perspective of initialization, thereby enhancing model performance. We begin by constructing prior token embeddings for each tool based on the tool's name or description, which are used to initialize and regularize the learnable tool token embeddings. This ensures the learned embeddings are well-aligned with the word token space, improving tool call accuracy. We evaluate the method on tasks such as numerical reasoning, knowledge-based question answering, and embodied plan generation using GSM8K-XL, FuncQA, KAMEL, and VirtualHome datasets. The results demonstrate clear improvements over recent baselines, including CoT, REACT, ICL, and ToolkenGPT, indicating that our approach effectively augments LLMs with tools through relevant tokens across diverse domains.
LARGO: Low-Rank Regulated Gradient Projection for Robust Parameter Efficient Fine-Tuning
Jun 14, 2025



The advent of parameter-efficient fine-tuning methods has significantly reduced the computational burden of adapting large-scale pretrained models to diverse downstream tasks. However, existing approaches often struggle to achieve robust performance under domain shifts while maintaining computational efficiency. To address this challenge, we propose Low-rAnk Regulated Gradient Projection (LARGO) algorithm that integrates dynamic constraints into low-rank adaptation methods. Specifically, LARGO incorporates parallel trainable gradient projections to dynamically regulate layer-wise updates, retaining the Out-Of-Distribution robustness of pretrained model while preserving inter-layer independence. Additionally, it ensures computational efficiency by mitigating the influence of gradient dependencies across layers during weight updates. Besides, through leveraging singular value decomposition of pretrained weights for structured initialization, we incorporate an SVD-based initialization strategy that minimizing deviation from pretrained knowledge. Through extensive experiments on diverse benchmarks, LARGO achieves state-of-the-art performance across in-domain and out-of-distribution scenarios, demonstrating improved robustness under domain shifts with significantly lower computational overhead compared to existing PEFT methods. The source code will be released soon.
EmbodiedGen: Towards a Generative 3D World Engine for Embodied Intelligence
Jun 12, 2025Constructing a physically realistic and accurately scaled simulated 3D world is crucial for the training and evaluation of embodied intelligence tasks. The diversity, realism, low cost accessibility and affordability of 3D data assets are critical for achieving generalization and scalability in embodied AI. However, most current embodied intelligence tasks still rely heavily on traditional 3D computer graphics assets manually created and annotated, which suffer from high production costs and limited realism. These limitations significantly hinder the scalability of data driven approaches. We present EmbodiedGen, a foundational platform for interactive 3D world generation. It enables the scalable generation of high-quality, controllable and photorealistic 3D assets with accurate physical properties and real-world scale in the Unified Robotics Description Format (URDF) at low cost. These assets can be directly imported into various physics simulation engines for fine-grained physical control, supporting downstream tasks in training and evaluation. EmbodiedGen is an easy-to-use, full-featured toolkit composed of six key modules: Image-to-3D, Text-to-3D, Texture Generation, Articulated Object Generation, Scene Generation and Layout Generation. EmbodiedGen generates diverse and interactive 3D worlds composed of generative 3D assets, leveraging generative AI to address the challenges of generalization and evaluation to the needs of embodied intelligence related research. Code is available at https://horizonrobotics.github.io/robot_lab/embodied_gen/index.html.
SIGMA: Refining Large Language Model Reasoning via Sibling-Guided Monte Carlo Augmentation
Jun 06, 2025



Enhancing large language models by simply scaling up datasets has begun to yield diminishing returns, shifting the spotlight to data quality. Monte Carlo Tree Search (MCTS) has emerged as a powerful technique for generating high-quality chain-of-thought data, yet conventional approaches typically retain only the top-scoring trajectory from the search tree, discarding sibling nodes that often contain valuable partial insights, recurrent error patterns, and alternative reasoning strategies. This unconditional rejection of non-optimal reasoning branches may waste vast amounts of informative data in the whole search tree. We propose SIGMA (Sibling Guided Monte Carlo Augmentation), a novel framework that reintegrates these discarded sibling nodes to refine LLM reasoning. SIGMA forges semantic links among sibling nodes along each search path and applies a two-stage refinement: a critique model identifies overlooked strengths and weaknesses across the sibling set, and a revision model conducts text-based backpropagation to refine the top-scoring trajectory in light of this comparative feedback. By recovering and amplifying the underutilized but valuable signals from non-optimal reasoning branches, SIGMA substantially improves reasoning trajectories. On the challenging MATH benchmark, our SIGMA-tuned 7B model achieves 54.92% accuracy using only 30K samples, outperforming state-of-the-art models trained on 590K samples. This result highlights that our sibling-guided optimization not only significantly reduces data usage but also significantly boosts LLM reasoning.
RoboTransfer: Geometry-Consistent Video Diffusion for Robotic Visual Policy Transfer
May 29, 2025Imitation Learning has become a fundamental approach in robotic manipulation. However, collecting large-scale real-world robot demonstrations is prohibitively expensive. Simulators offer a cost-effective alternative, but the sim-to-real gap make it extremely challenging to scale. Therefore, we introduce RoboTransfer, a diffusion-based video generation framework for robotic data synthesis. Unlike previous methods, RoboTransfer integrates multi-view geometry with explicit control over scene components, such as background and object attributes. By incorporating cross-view feature interactions and global depth/normal conditions, RoboTransfer ensures geometry consistency across views. This framework allows fine-grained control, including background edits and object swaps. Experiments demonstrate that RoboTransfer is capable of generating multi-view videos with enhanced geometric consistency and visual fidelity. In addition, policies trained on the data generated by RoboTransfer achieve a 33.3% relative improvement in the success rate in the DIFF-OBJ setting and a substantial 251% relative improvement in the more challenging DIFF-ALL scenario. Explore more demos on our project page: https://horizonrobotics.github.io/robot_lab/robotransfer