 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Long Videos to Engaging Clips: A Human-Inspired Video Editing Framework with Multimodal Narrative Understanding
Jul 03, 2025The rapid growth of online video content, especially on short video platforms, has created a growing demand for efficient video editing techniques that can condense long-form videos into concise and engaging clips. Existing automatic editing methods predominantly rely on textual cues from ASR transcripts and end-to-end segment selection, often neglecting the rich visual context and leading to incoherent outputs. In this paper, we propose a human-inspired automatic video editing framework (HIVE) that leverages multimodal narrative understanding to address these limitations. Our approach incorporates character extraction, dialogue analysis, and narrative summarization through multimodal large language models, enabling a holistic understanding of the video content. To further enhance coherence, we apply scene-level segmentation and decompose the editing process into three subtasks: highlight detection, opening/ending selection, and pruning of irrelevant content. To facilitate research in this area, we introduce DramaAD, a novel benchmark dataset comprising over 800 short drama episodes and 500 professionally edited advertisement clips. Experimental results demonstrate that our framework consistently outperforms existing baselines across both general and advertisement-oriented editing tasks, significantly narrowing the quality gap between automatic and human-edited videos.
Design Space Exploration of Neural Network Activation Function Circuits
Sep 22, 2018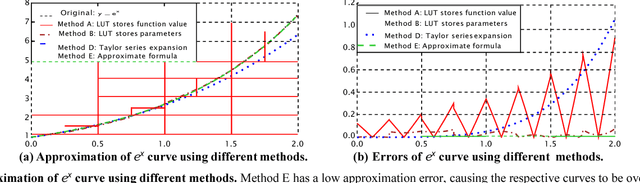
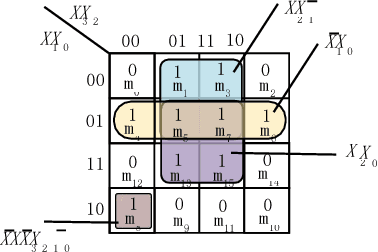
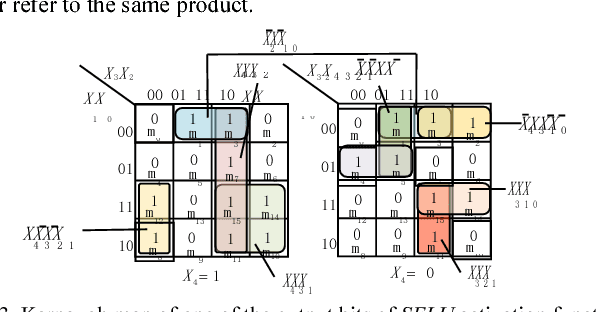
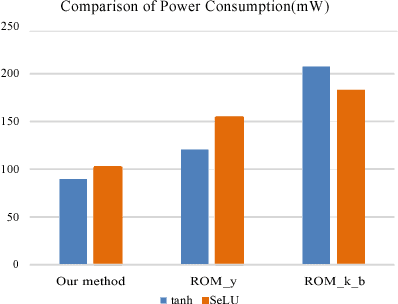
The widespread application of artificial neural networks has prompted researchers to experiment with FPGA and customized ASIC designs to speed up their computation. These implementation efforts have generally focused on weight multiplication and signal summation operations, and less on activation functions used in these applications. Yet, efficient hardware implementations of nonlinear activation functions like Exponential Linear Units (ELU), Scaled Exponential Linear Units (SELU), and Hyperbolic Tangent (tanh), are central to designing effective neural network accelerators, since these functions require lots of resources. In this paper, we explore efficient hardware implementations of activation functions using purely combinational circuits, with a focus on two widely used nonlinear activation functions, i.e., SELU and tanh. Our experiments demonstrate that neural networks are generally insensitive to the precision of the activation function. The results also prove that the proposed combinational circuit-based approach is very efficient in terms of speed and area, with negligible accuracy loss on the MNIST, CIFAR-10 and IMAGENET benchmarks. Synopsys Design Compiler synthesis results show that circuit designs for tanh and SELU can save between 3.13-7.69 and 4.45-8:45 area compared to the LUT/memory-based implementations, and can operate at 5.14GHz and 4.52GHz using the 28nm SVT library, respectively. The implementation is available at: https://github.com/ThomasMrY/ActivationFunctionDemo.