 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on Graph-Retrieval Augmented Generation Based on Historical Text Knowledge Graphs
Jun 18, 2025



This article addresses domain knowledge gaps in general large language models for historical text analysis in the context of computational humanities and AIGC technology. We propose the Graph RAG framework, combining chain-of-thought prompting, self-instruction generation, and process supervision to create a The First Four Histories character relationship dataset with minimal manual annotation. This dataset supports automated historical knowledge extraction, reducing labor costs. In the graph-augmented generation phase, we introduce a collaborative mechanism between knowledge graphs and retrieval-augmented generation, improving the alignment of general models with historical knowledge. Experiments show that the domain-specific model Xunzi-Qwen1.5-14B, with Simplified Chinese input and chain-of-thought prompting, achieves optimal performance in relation extraction (F1 = 0.68). The DeepSeek model integrated with GraphRAG improves F1 by 11% (0.08-0.19) on the open-domain C-CLUE relation extraction dataset, surpassing the F1 value of Xunzi-Qwen1.5-14B (0.12), effectively alleviating hallucinations phenomenon, and improving interpretability. This framework offers a low-resource solution for classical text knowledge extraction, advancing historical knowledge services and humanities research.
Can reasoning models comprehend mathematical problems in Chinese ancient texts? An empirical study based on data from Suanjing Shishu
May 22, 2025This study addresses the challenges in intelligent processing of Chinese ancient mathematical classics by constructing Guji_MATH, a benchmark for evaluating classical texts based on Suanjing Shishu. It systematically assesses the mathematical problem-solving capabilities of mainstream reasoning models under the unique linguistic constraints of classical Chinese. Through machine-assisted annotation and manual verification, 538 mathematical problems were extracted from 8 canonical texts, forming a structured dataset centered on the "Question-Answer-Solution" framework, supplemented by problem types and difficulty levels. Dual evaluation modes--closed-book (autonomous problem-solving) and open-book (reproducing classical solution methods)--were designed to evaluate the performance of six reasoning models on ancient Chinese mathematical problems. Results indicate that reasoning models can partially comprehend and solve these problems, yet their overall performance remains inferior to benchmarks on modern mathematical tasks. Enhancing models' classical Chinese comprehension and cultural knowledge should be prioritized for optimization. This study provides methodological support for mining mathematical knowledge from ancient texts and disseminating traditional culture, while offering new perspectives for evaluating cross-linguistic and cross-cultural capabilities of reasoning models.
Dynamic Change of Amplitude for OCT Functional Imaging
Nov 28, 2023Optical coherence tomography (OCT) is capable of non-destructively obtaining cross-sectional information of samples with micrometer spatial resolution, which plays an important role in ophthalmology and endovascular medicine. Measuring OCT amplitude can obtain three-dimensional structural information of the sample, such as the layered structure of the retina, but is of limited use for functional information such as tissue specificity, blood flow, and mechanical properties. OCT functional imaging techniques based on other optical field properties including phase, polarization state, and wavelength have emerged, such as Doppler OCT, optical coherence elastography, polarization-sensitive OCT, and visible-light OCT. Among them, functional imaging techniques based on dynamic changes of amplitude have significant robustness and complexity advantages, and achieved significant clinical success in label-free blood flow imaging. In addition, dynamic light scattering OCT for 3D blood flow velocity measurement, dynamic OCT with the ability to display label-free tissue/cell specificity, and OCT thermometry for monitoring the temperature field of thermophysical treatments are the frontiers in OCT functional imaging. In this paper, the principles and applications of the above technologies are summarized, the remaining technical challenges are analyzed, and the future development is envisioned.
SikuGPT: A Generative Pre-trained Model for Intelligent Information Processing of Ancient Texts from the Perspective of Digital Humanities
Apr 16, 2023The rapid advance in artificial intelligence technology has facilitated the prosperity of digital humanities research. Against such backdrop, research methods need to be transformed in the intelligent processing of ancient texts, which is a crucial component of digital humanities research, so as to adapt to new development trends in the wave of AIGC. In this study, we propose a GPT model called SikuGPT based on the corpus of Siku Quanshu. The model's performance in tasks such as intralingual translation and text classification exceeds that of other GPT-type models aimed at processing ancient texts. SikuGPT's ability to process traditional Chinese ancient texts can help promote the organization of ancient information and knowledge services, as well as the international dissemination of Chinese ancient culture.
PolSAR Image Classification Based on Dilated Convolution and Pixel-Refining Parallel Mapping network in the Complex Domain
Sep 24, 2019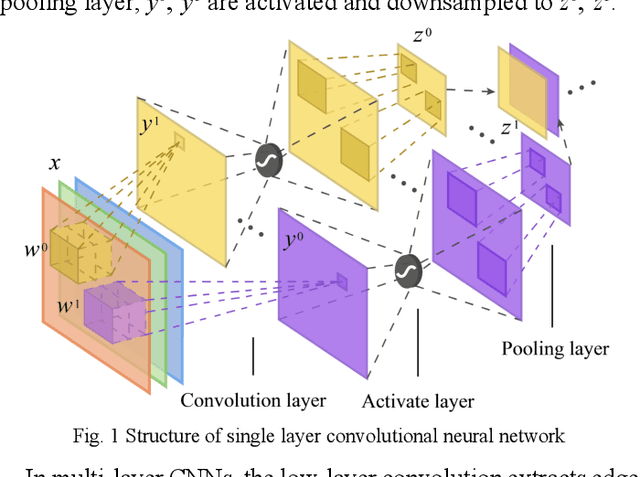
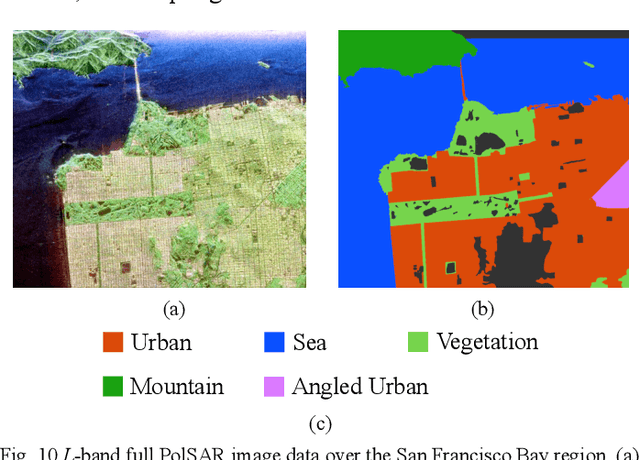
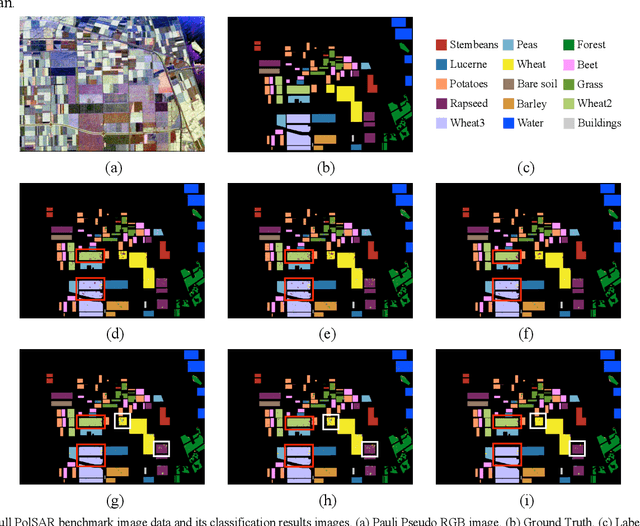
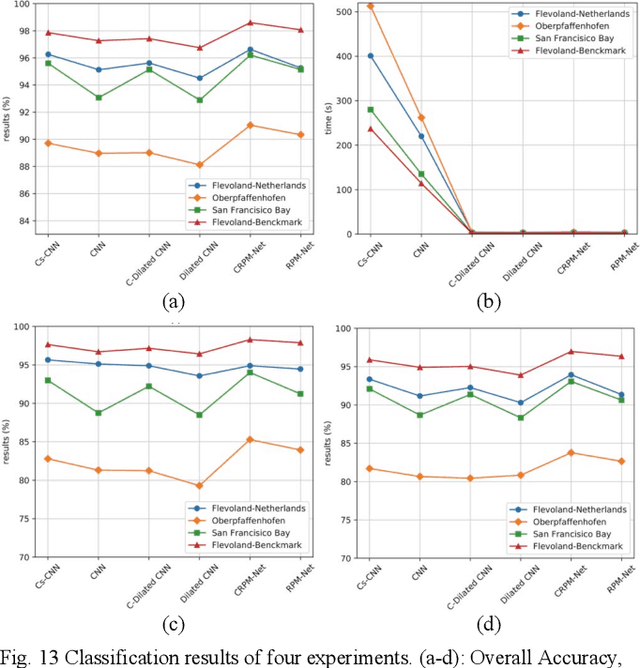
Efficient and accurate polarimetric synthetic aperture radar (PolSAR) image classification with a limited number of prior labels is always full of challenges. For general supervised deep learning classification algorithms, the pixel-by-pixel algorithm achieves precise yet inefficient classification with a small number of labeled pixels, whereas the pixel mapping algorithm achieves efficient yet edge-rough classification with more prior labels required. To take efficiency, accuracy and prior labels into account, we propose a novel pixel-refining parallel mapping network in the complex domain named CRPM-Net and the corresponding training algorithm for PolSAR image classification. CRPM-Net consists of two parallel sub-networks: a) A transfer dilated convolution mapping network in the complex domain (C-Dilated CNN) activated by a complex cross-convolution neural network (Cs-CNN), which is aiming at precise localization, high efficiency and the full use of phase information; b) A complex domain encoder-decoder network connected parallelly with C-Dilated CNN, which is to extract more contextual semantic features. Finally, we design a two-step algorithm to train the Cs-CNN and CRPM-Net with a small number of labeled pixels for higher accuracy by refining misclassified labeled pixels. We verify the proposed method on AIRSAR and E-SAR datasets. The experimental results demonstrate that CRPM-Net achieves the best classification results and substantially outperforms some latest state-of-the-art approaches in both efficiency and accuracy for PolSAR image classification. The source code and trained models for CRPM-Net is available at: https://github.com/PROoshio/CRPM-Net.