 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHand3R: Online 4D Hand-Scene Reconstruction in the Wild
Feb 03, 2026For Embodied AI, jointly reconstructing dynamic hands and the dense scene context is crucial for understanding physical interaction. However, most existing methods recover isolated hands in local coordinates, overlooking the surrounding 3D environment. To address this, we present Hand3R, the first online framework for joint 4D hand-scene reconstruction from monocular video. Hand3R synergizes a pre-trained hand expert with a 4D scene foundation model via a scene-aware visual prompting mechanism. By injecting high-fidelity hand priors into a persistent scene memory, our approach enables simultaneous reconstruction of accurate hand meshes and dense metric-scale scene geometry in a single forward pass. Experiments demonstrate that Hand3R bypasses the reliance on offline optimization and delivers competitive performance in both local hand reconstruction and global positioning.
RecurGS: Interactive Scene Modeling via Discrete-State Recurrent Gaussian Fusion
Dec 20, 2025Recent advances in 3D scene representations have enabled high-fidelity novel view synthesis, yet adapting to discrete scene changes and constructing interactive 3D environments remain open challenges in vision and robotics. Existing approaches focus solely on updating a single scene without supporting novel-state synthesis. Others rely on diffusion-based object-background decoupling that works on one state at a time and cannot fuse information across multiple observations. To address these limitations, we introduce RecurGS, a recurrent fusion framework that incrementally integrates discrete Gaussian scene states into a single evolving representation capable of interaction. RecurGS detects object-level changes across consecutive states, aligns their geometric motion using semantic correspondence and Lie-algebra based SE(3) refinement, and performs recurrent updates that preserve historical structures through replay supervision. A voxelized, visibility-aware fusion module selectively incorporates newly observed regions while keeping stable areas fixed, mitigating catastrophic forgetting and enabling efficient long-horizon updates. RecurGS supports object-level manipulation, synthesizes novel scene states without requiring additional scans, and maintains photorealistic fidelity across evolving environments. Extensive experiments across synthetic and real-world datasets demonstrate that our framework delivers high-quality reconstructions with substantially improved update efficiency, providing a scalable step toward continuously interactive Gaussian worlds.
IGFuse: Interactive 3D Gaussian Scene Reconstruction via Multi-Scans Fusion
Aug 18, 2025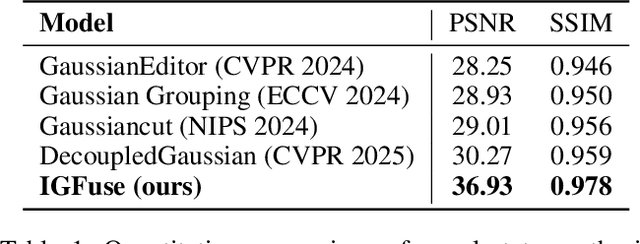
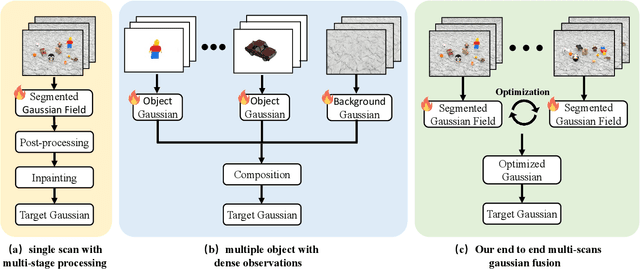
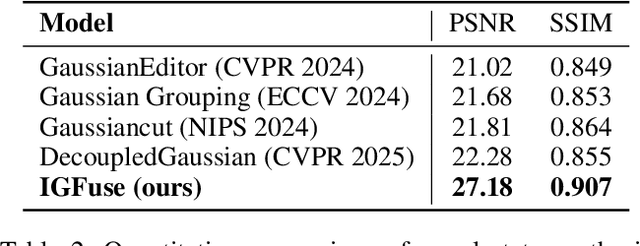
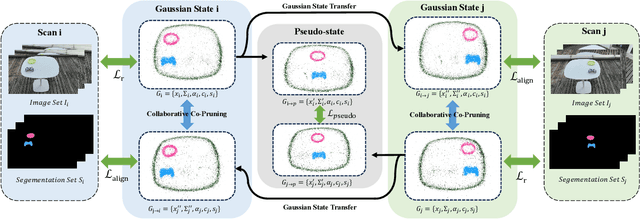
Reconstructing complete and interactive 3D scenes remains a fundamental challenge in computer vision and robotics, particularly due to persistent object occlusions and limited sensor coverage. Multiview observations from a single scene scan often fail to capture the full structural details. Existing approaches typically rely on multi stage pipelines, such as segmentation, background completion, and inpainting or require per-object dense scanning, both of which are error-prone, and not easily scalable. We propose IGFuse, a novel framework that reconstructs interactive Gaussian scene by fusing observations from multiple scans, where natural object rearrangement between captures reveal previously occluded regions. Our method constructs segmentation aware Gaussian fields and enforces bi-directional photometric and semantic consistency across scans. To handle spatial misalignments, we introduce a pseudo-intermediate scene state for unified alignment, alongside collaborative co-pruning strategies to refine geometry. IGFuse enables high fidelity rendering and object level scene manipulation without dense observations or complex pipelines. Extensive experiments validate the framework's strong generalization to novel scene configurations, demonstrating its effectiveness for real world 3D reconstruction and real-to-simulation transfer. Our project page is available online.