 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGMA: Refining Large Language Model Reasoning via Sibling-Guided Monte Carlo Augmentation
Jun 06, 2025



Enhancing large language models by simply scaling up datasets has begun to yield diminishing returns, shifting the spotlight to data quality. Monte Carlo Tree Search (MCTS) has emerged as a powerful technique for generating high-quality chain-of-thought data, yet conventional approaches typically retain only the top-scoring trajectory from the search tree, discarding sibling nodes that often contain valuable partial insights, recurrent error patterns, and alternative reasoning strategies. This unconditional rejection of non-optimal reasoning branches may waste vast amounts of informative data in the whole search tree. We propose SIGMA (Sibling Guided Monte Carlo Augmentation), a novel framework that reintegrates these discarded sibling nodes to refine LLM reasoning. SIGMA forges semantic links among sibling nodes along each search path and applies a two-stage refinement: a critique model identifies overlooked strengths and weaknesses across the sibling set, and a revision model conducts text-based backpropagation to refine the top-scoring trajectory in light of this comparative feedback. By recovering and amplifying the underutilized but valuable signals from non-optimal reasoning branches, SIGMA substantially improves reasoning trajectories. On the challenging MATH benchmark, our SIGMA-tuned 7B model achieves 54.92% accuracy using only 30K samples, outperforming state-of-the-art models trained on 590K samples. This result highlights that our sibling-guided optimization not only significantly reduces data usage but also significantly boosts LLM reasoning.
Human-imperceptible, Machine-recognizable Images
Jun 06, 2023



Massive human-related data is collected to train neural networks for computer vision tasks. A major conflict is exposed relating to software engineers between better developing AI systems and distancing from the sensitive training data. To reconcile this conflict, this paper proposes an efficient privacy-preserving learning paradigm, where images are first encrypted to become ``human-imperceptible, machine-recognizable'' via one of the two encryption strategies: (1) random shuffling to a set of equally-sized patches and (2) mixing-up sub-patches of the images. Then, minimal adaptations are made to vision transformer to enable it to learn on the encrypted images for vision tasks, including image classification and object detection. Extensive experiments on ImageNet and COCO show that the proposed paradigm achieves comparable accuracy with the competitive methods. Decrypting the encrypted images requires solving an NP-hard jigsaw puzzle or an ill-posed inverse problem, which is empirically shown intractable to be recovered by various attackers, including the powerful vision transformer-based attacker. We thus show that the proposed paradigm can ensure the encrypted images have become human-imperceptible while preserving machine-recognizable information. The code is available at \url{https://github.com/FushengHao/PrivacyPreservingML.}
Transition-based Parsing with Context Enhancement and Future Reward Reranking
Dec 15, 2016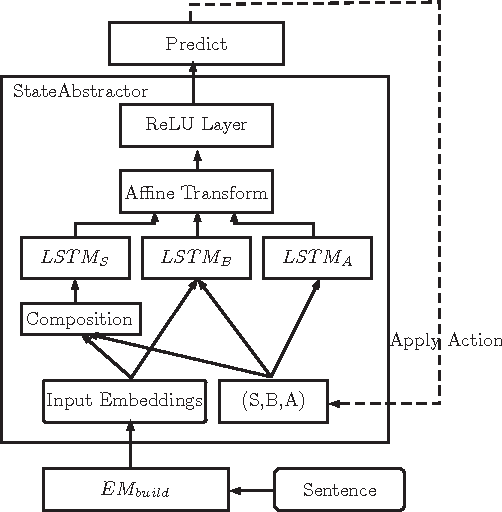


This paper presents a novel reranking model, future reward reranking, to re-score the actions in a transition-based parser by using a global scorer. Different to conventional reranking parsing, the model searches for the best dependency tree in all feasible trees constraining by a sequence of actions to get the future reward of the sequence. The scorer is based on a first-order graph-based parser with bidirectional LSTM, which catches different parsing view compared with the transition-based parser. Besides, since context enhancement has shown substantial improvement in the arc-stand transition-based parsing over the parsing accuracy, we implement context enhancement on an arc-eager transition-base parser with stack LSTMs, the dynamic oracle and dropout supporting and achieve further improvement. With the global scorer and context enhancement, the results show that UAS of the parser increases as much as 1.20% for English and 1.66% for Chinese, and LAS increases as much as 1.32% for English and 1.63% for Chinese. Moreover, we get state-of-the-art LASs, achieving 87.58% for Chinese and 93.37% for English.