 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Long Videos to Engaging Clips: A Human-Inspired Video Editing Framework with Multimodal Narrative Understanding
Jul 03, 2025The rapid growth of online video content, especially on short video platforms, has created a growing demand for efficient video editing techniques that can condense long-form videos into concise and engaging clips. Existing automatic editing methods predominantly rely on textual cues from ASR transcripts and end-to-end segment selection, often neglecting the rich visual context and leading to incoherent outputs. In this paper, we propose a human-inspired automatic video editing framework (HIVE) that leverages multimodal narrative understanding to address these limitations. Our approach incorporates character extraction, dialogue analysis, and narrative summarization through multimodal large language models, enabling a holistic understanding of the video content. To further enhance coherence, we apply scene-level segmentation and decompose the editing process into three subtasks: highlight detection, opening/ending selection, and pruning of irrelevant content. To facilitate research in this area, we introduce DramaAD, a novel benchmark dataset comprising over 800 short drama episodes and 500 professionally edited advertisement clips. Experimental results demonstrate that our framework consistently outperforms existing baselines across both general and advertisement-oriented editing tasks, significantly narrowing the quality gap between automatic and human-edited videos.
Spiral Language Modeling
Dec 20, 2021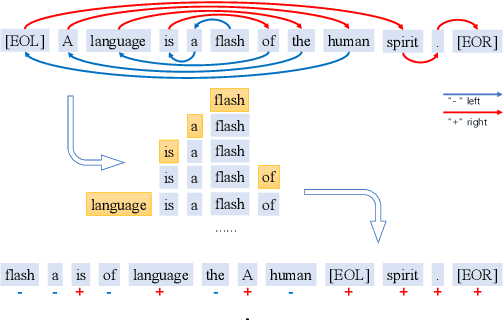

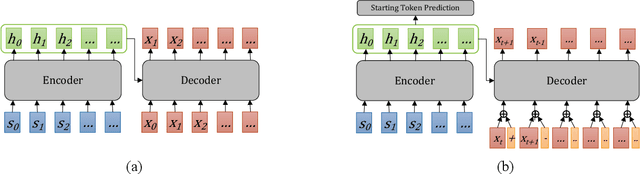
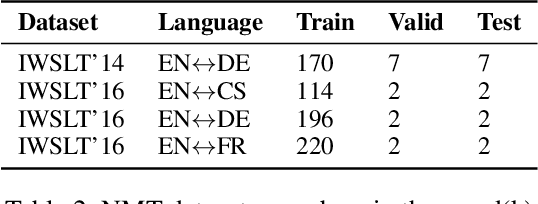
In almost all text generation applications, word sequences are constructed in a left-to-right (L2R) or right-to-left (R2L) manner, as natural language sentences are written either L2R or R2L. However, we find that the natural language written order is not essential for text generation. In this paper, we propose Spiral Language Modeling (SLM), a general approach that enables one to construct natural language sentences beyond the L2R and R2L order. SLM allows one to form natural language text by starting from an arbitrary token inside the result text and expanding the rest tokens around the selected ones. It makes the decoding order a new optimization objective besides the language model perplexity, which further improves the diversity and quality of the generated text. Furthermore, SLM makes it possible to manipulate the text construction process by selecting a proper starting token. SLM also introduces generation orderings as additional regularization to improve model robustness in low-resource scenarios. Experiments on 8 widely studied Neural Machine Translation (NMT) tasks show that SLM is constantly effective with up to 4.7 BLEU increase comparing to the conventional L2R decoding approach.