 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR-GAN: Conditional Generative Adversarial Network for Fine-Grained Lesion Synthesis on Diabetic Retinopathy Images
Dec 10, 2019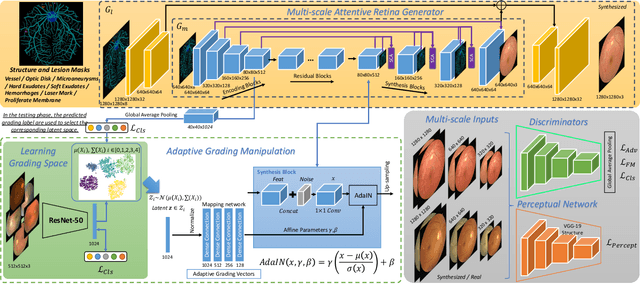
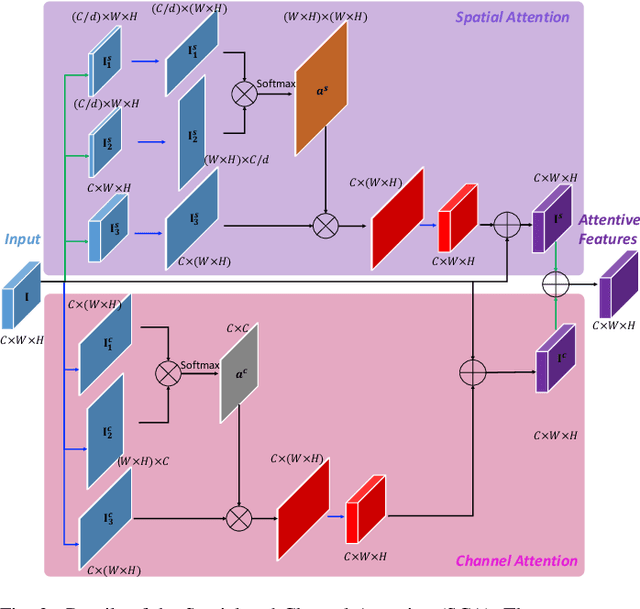
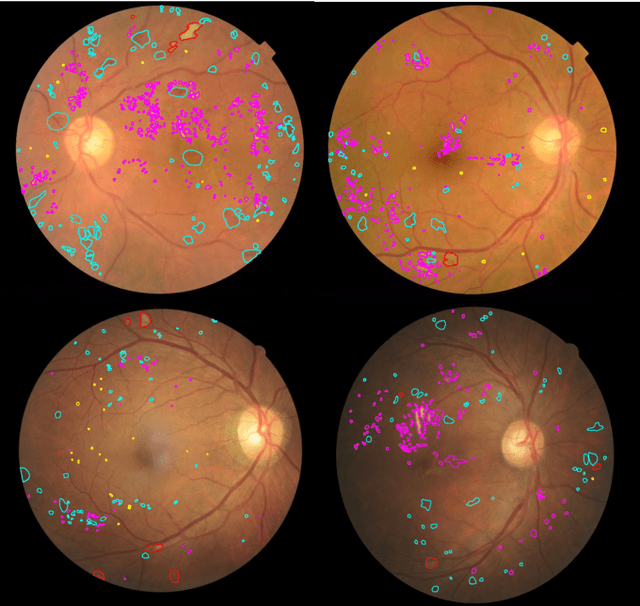
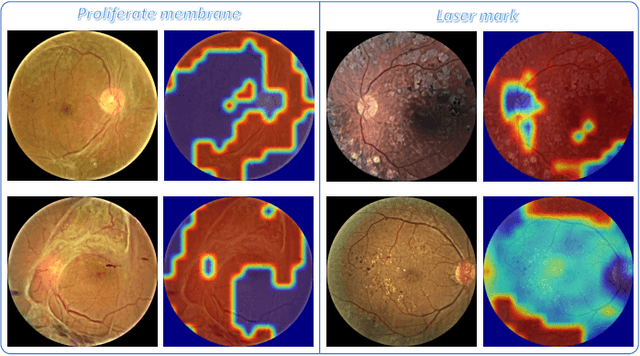
Diabetic retinopathy (DR) is a complication of diabetes that severely affects eyes. It can be graded into five levels of severity according to international protocol. However, optimizing a grading model to have strong generalizability requires a large amount of balanced training data, which is difficult to collect particularly for the high severity levels. Typical data augmentation methods, including random flipping and rotation, cannot generate data with high diversity. In this paper, we propose a diabetic retinopathy generative adversarial network (DR-GAN) to synthesize high-resolution fundus images which can be manipulated with arbitrary grading and lesion information. Thus, large-scale generated data can be used for more meaningful augmentation to train a DR grading and lesion segmentation model. The proposed retina generator is conditioned on the structural and lesion masks, as well as adaptive grading vectors sampled from the latent grading space, which can be adopted to control the synthesized grading severity. Moreover, a multi-scale spatial and channel attention module is devised to improve the generation ability to synthesize details. Multi-scale discriminators are designed to operate from large to small receptive fields, and joint adversarial losses are adopted to optimize the whole network in an end-to-end manner. With extensive experiments evaluated on the EyePACS dataset connected to Kaggle, as well as our private dataset (SKA - will be released once get official permission), we validate the effectiveness of our method, which can both synthesize highly realistic (1280 x 1280) controllable fundus images and contribute to the DR grading task.
Diversifying Inference Path Selection: Moving-Mobile-Network for Landmark Recognition
Dec 01, 2019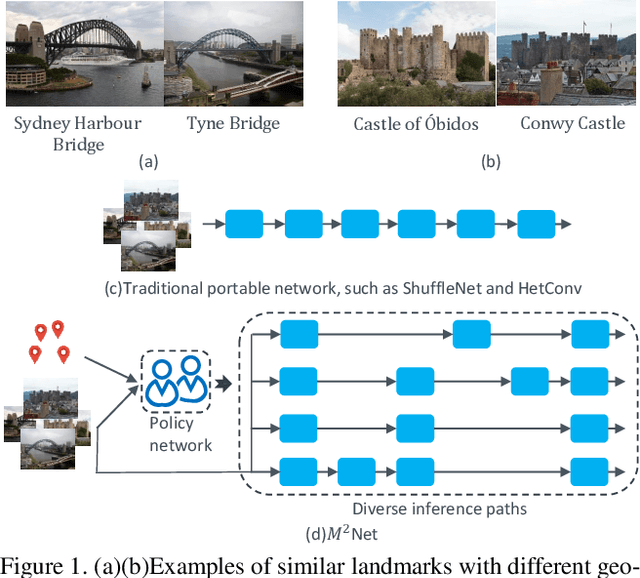
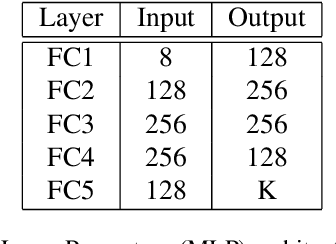
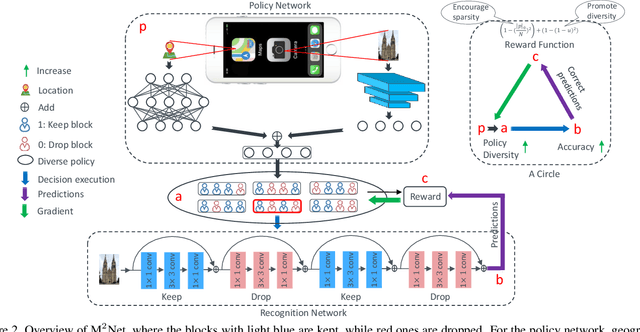
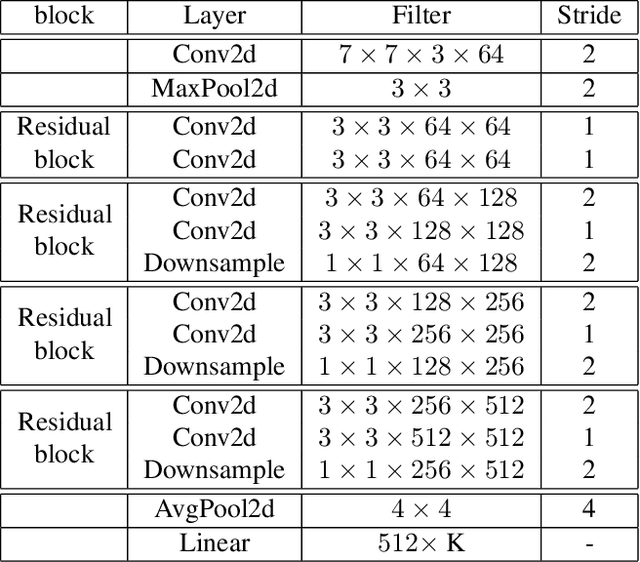
Deep convolutional neural networks have largely benefited computer vision tasks. However, the high computational complexity limits their real-world applications. To this end, many methods have been proposed for efficient network learning, and applications in portable mobile devices. In this paper, we propose a novel \underline{M}oving-\underline{M}obile-\underline{Net}work, named M$^2$Net, for landmark recognition, equipped each landmark image with located geographic information. We intuitively find that M$^2$Net can essentially promote the diversity of the inference path (selected blocks subset) selection, so as to enhance the recognition accuracy. The above intuition is achieved by our proposed reward function with the input of geo-location and landmarks. We also find that the performance of other portable networks can be improved via our architecture. We construct two landmark image datasets, with each landmark associated with geographic information, over which we conduct extensive experiments to demonstrate that M$^2$Net achieves improved recognition accuracy with comparable complexity.
Semi-Heterogeneous Three-Way Joint Embedding Network for Sketch-Based Image Retrieval
Nov 10, 2019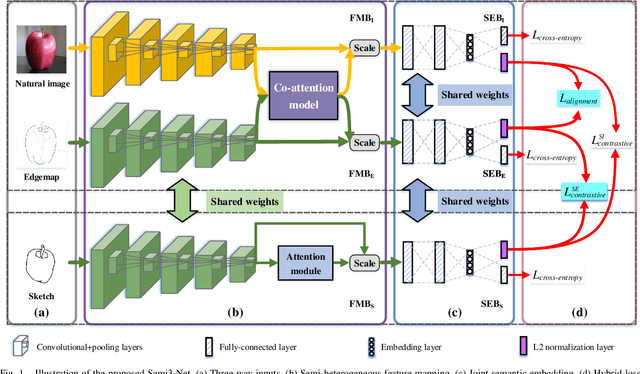
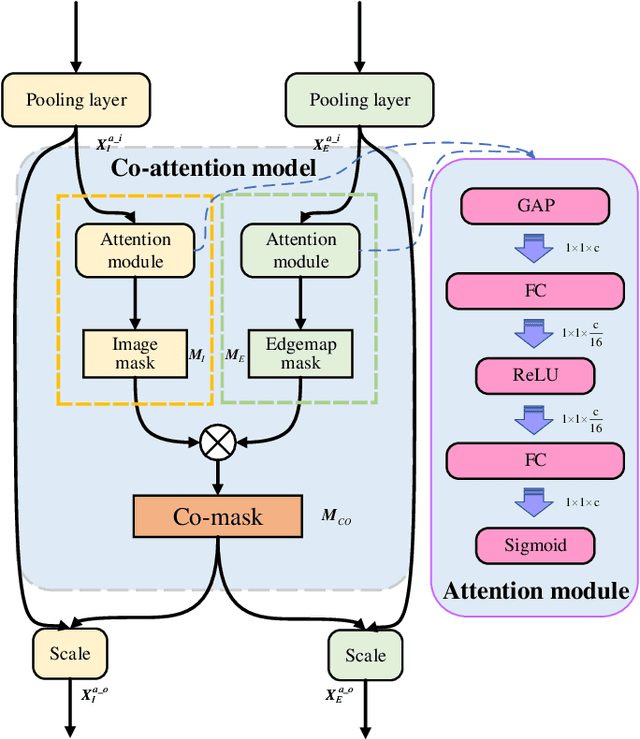

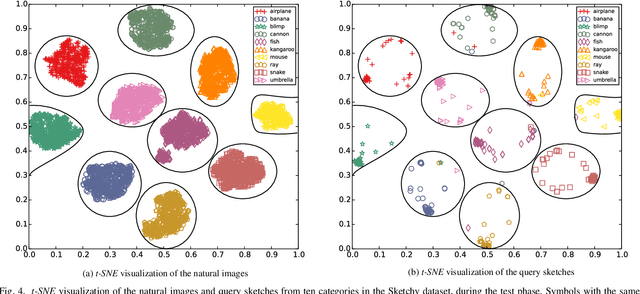
Sketch-based image retrieval (SBIR) is a challenging task due to the large cross-domain gap between sketches and natural images. How to align abstract sketches and natural images into a common high-level semantic space remains a key problem in SBIR. In this paper, we propose a novel semi-heterogeneous three-way joint embedding network (Semi3-Net), which integrates three branches (a sketch branch, a natural image branch, and an edgemap branch) to learn more discriminative cross-domain feature representations for the SBIR task. The key insight lies with how we cultivate the mutual and subtle relationships amongst the sketches, natural images, and edgemaps. A semi-heterogeneous feature mapping is designed to extract bottom features from each domain, where the sketch and edgemap branches are shared while the natural image branch is heterogeneous to the other branches. In addition, a joint semantic embedding is introduced to embed the features from different domains into a common high-level semantic space, where all of the three branches are shared. To further capture informative features common to both natural images and the corresponding edgemaps, a co-attention model is introduced to conduct common channel-wise feature recalibration between different domains. A hybrid-loss mechanism is designed to align the three branches, where an alignment loss and a sketch-edgemap contrastive loss are presented to encourage the network to learn invariant cross-domain representations. Experimental results on two widely used category-level datasets (Sketchy and TU-Berlin Extension) demonstrate that the proposed method outperforms state-of-the-art methods.
Deep Contextual Attention for Human-Object Interaction Detection
Oct 17, 2019

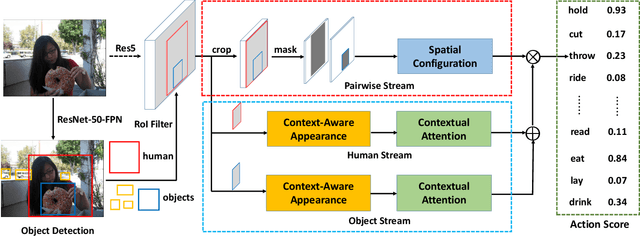
Human-object interaction detection is an important and relatively new class of visual relationship detection tasks, essential for deeper scene understanding. Most existing approaches decompose the problem into object localization and interaction recognition. Despite showing progress, these approaches only rely on the appearances of humans and objects and overlook the available context information, crucial for capturing subtle interactions between them. We propose a contextual attention framework for human-object interaction detection. Our approach leverages context by learning contextually-aware appearance features for human and object instances. The proposed attention module then adaptively selects relevant instance-centric context information to highlight image regions likely to contain human-object interactions. Experiments are performed on three benchmarks: V-COCO, HICO-DET and HCVRD. Our approach outperforms the state-of-the-art on all datasets. On the V-COCO dataset, our method achieves a relative gain of 4.4% in terms of role mean average precision ($mAP_{role}$), compared to the existing best approach.
Mask-Guided Attention Network for Occluded Pedestrian Detection
Oct 15, 2019

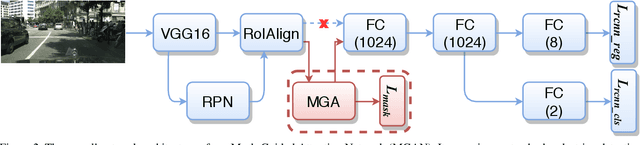
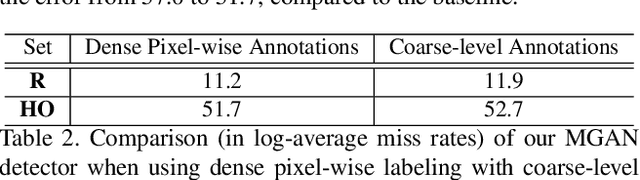
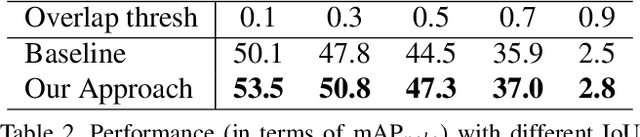
Pedestrian detection relying on deep convolution neural networks has made significant progress. Though promising results have been achieved on standard pedestrians, the performance on heavily occluded pedestrians remains far from satisfactory. The main culprits are intra-class occlusions involving other pedestrians and inter-class occlusions caused by other objects, such as cars and bicycles. These result in a multitude of occlusion patterns. We propose an approach for occluded pedestrian detection with the following contributions. First, we introduce a novel mask-guided attention network that fits naturally into popular pedestrian detection pipelines. Our attention network emphasizes on visible pedestrian regions while suppressing the occluded ones by modulating full body features. Second, we empirically demonstrate that coarse-level segmentation annotations provide reasonable approximation to their dense pixel-wise counterparts. Experiments are performed on CityPersons and Caltech datasets. Our approach sets a new state-of-the-art on both datasets. Our approach obtains an absolute gain of 9.5% in log-average miss rate, compared to the best reported results on the heavily occluded (HO) pedestrian set of CityPersons test set. Further, on the HO pedestrian set of Caltech dataset, our method achieves an absolute gain of 5.0% in log-average miss rate, compared to the best reported results. Code and models are available at: https://github.com/Leotju/MGAN.
Fast Large-Scale Discrete Optimization Based on Principal Coordinate Descent
Sep 16, 2019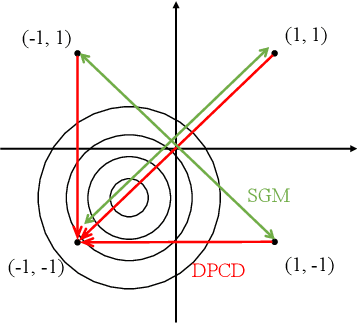
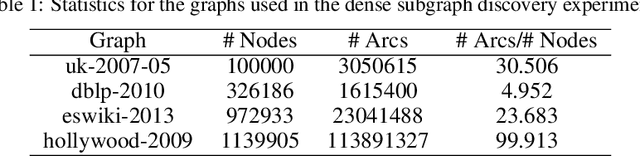
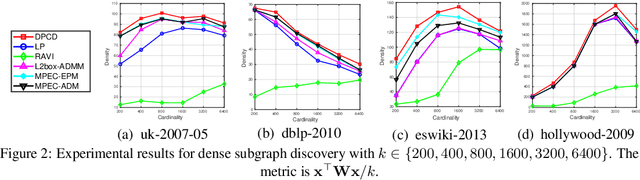
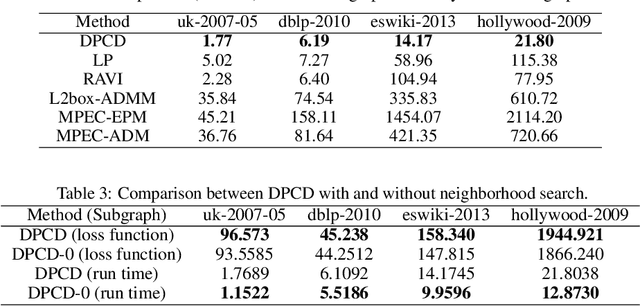
Binary optimization, a representative subclass of discrete optimization, plays an important role in mathematical optimization and has various applications in computer vision and machine learning. Usually, binary optimization problems are NP-hard and difficult to solve due to the binary constraints, especially when the number of variables is very large. Existing methods often suffer from high computational costs or large accumulated quantization errors, or are only designed for specific tasks. In this paper, we propose a fast algorithm to find effective approximate solutions for general binary optimization problems. The proposed algorithm iteratively solves minimization problems related to the linear surrogates of loss functions, which leads to the updating of some binary variables most impacting the value of loss functions in each step. Our method supports a wide class of empirical objective functions with/without restrictions on the numbers of $1$s and $-1$s in the binary variables. Furthermore, the theoretical convergence of our algorithm is proven, and the explicit convergence rates are derived, for objective functions with Lipschitz continuous gradients, which are commonly adopted in practice. Extensive experiments on several binary optimization tasks and large-scale datasets demonstrate the superiority of the proposed algorithm over several state-of-the-art methods in terms of both effectiveness and efficiency.
AnimalWeb: A Large-Scale Hierarchical Dataset of Annotated Animal Faces
Sep 11, 2019
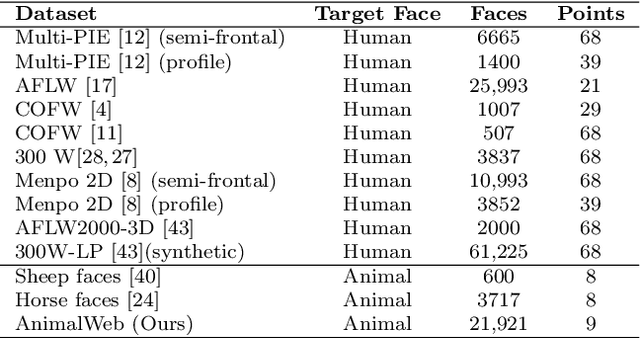

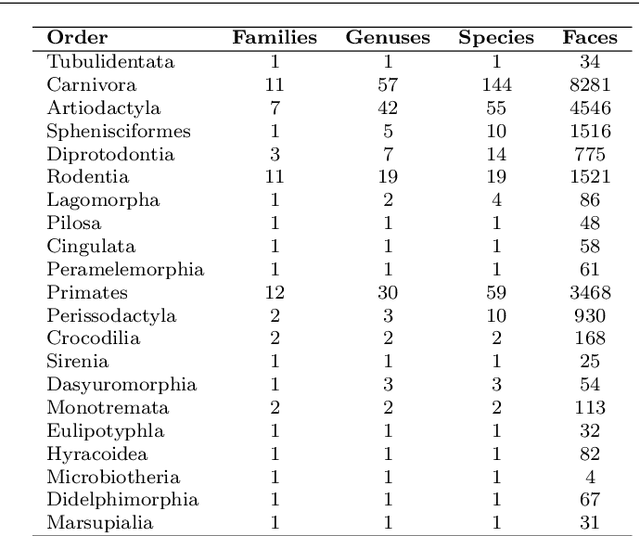
Being heavily reliant on animals, it is our ethical obligation to improve their well-being by understanding their needs. Several studies show that animal needs are often expressed through their faces. Though remarkable progress has been made towards the automatic understanding of human faces, this has regrettably not been the case with animal faces. There exists significant room and appropriate need to develop automatic systems capable of interpreting animal faces. Among many transformative impacts, such a technology will foster better and cheaper animal healthcare, and further advance animal psychology understanding. We believe the underlying research progress is mainly obstructed by the lack of an adequately annotated dataset of animal faces, covering a wide spectrum of animal species. To this end, we introduce a large-scale, hierarchical annotated dataset of animal faces, featuring 21.9K faces from 334 diverse species and 21 animal orders across biological taxonomy. These faces are captured `in-the-wild' conditions and are consistently annotated with 9 landmarks on key facial features. The proposed dataset is structured and scalable by design; its development underwent four systematic stages involving rigorous, manual annotation effort of over 6K man-hours. We benchmark it for face alignment using the existing art under novel problem settings. Results showcase its challenging nature, unique attributes and present definite prospects for novel, adaptive, and generalized face-oriented CV algorithms. We further benchmark the dataset for face detection and fine-grained recognition tasks, to demonstrate multi-task applications and room for improvement. Experiments indicate that this dataset will push the algorithmic advancements across many related CV tasks and encourage the development of novel systems for animal facial behaviour monitoring. We will make the dataset publicly available.
RANet: Ranking Attention Network for Fast Video Object Segmentation
Sep 08, 2019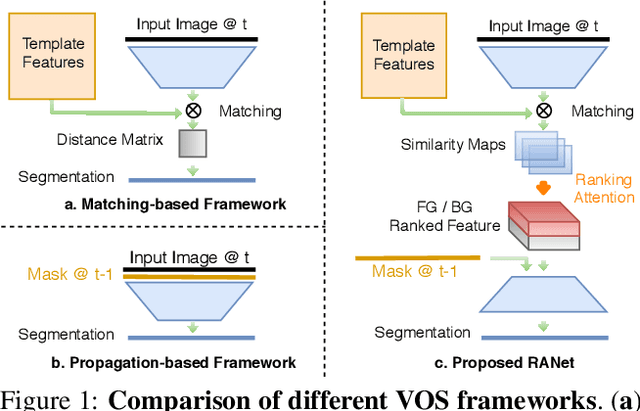
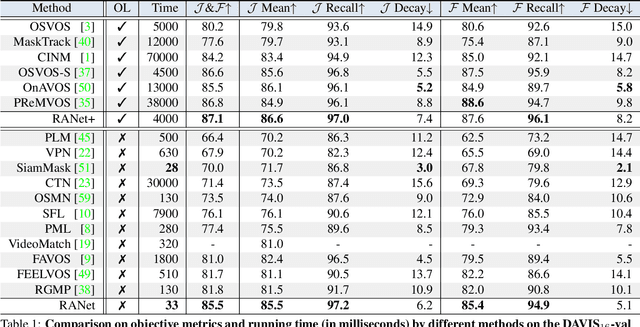
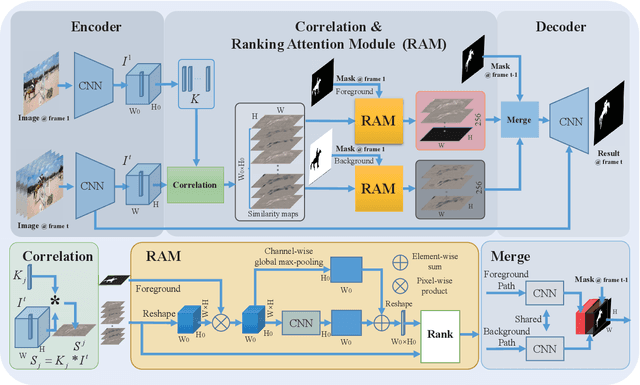
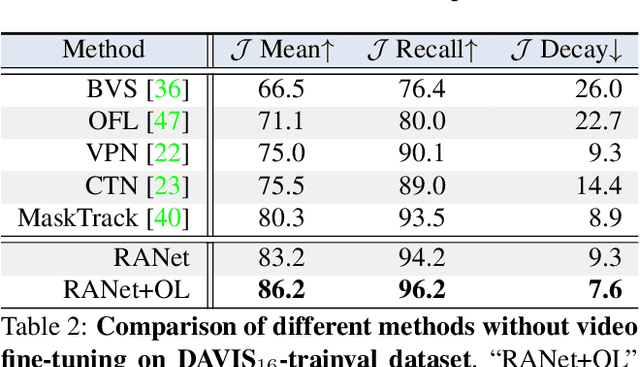
Despite online learning (OL) techniques have boosted the performance of semi-supervised video object segmentation (VOS) methods, the huge time costs of OL greatly restrict their practicality. Matching based and propagation based methods run at a faster speed by avoiding OL techniques. However, they are limited by sub-optimal accuracy, due to mismatching and drifting problems. In this paper, we develop a real-time yet very accurate Ranking Attention Network (RANet) for VOS. Specifically, to integrate the insights of matching based and propagation based methods, we employ an encoder-decoder framework to learn pixel-level similarity and segmentation in an end-to-end manner. To better utilize the similarity maps, we propose a novel ranking attention module, which automatically ranks and selects these maps for fine-grained VOS performance. Experiments on DAVIS-16 and DAVIS-17 datasets show that our RANet achieves the best speed-accuracy trade-off, e.g., with 33 milliseconds per frame and J&F=85.5% on DAVIS-16. With OL, our RANet reaches J&F=87.1% on DAVIS-16, exceeding state-of-the-art VOS methods. The code can be found at https://github.com/Storife/RANet.
3C-Net: Category Count and Center Loss for Weakly-Supervised Action Localization
Aug 22, 2019
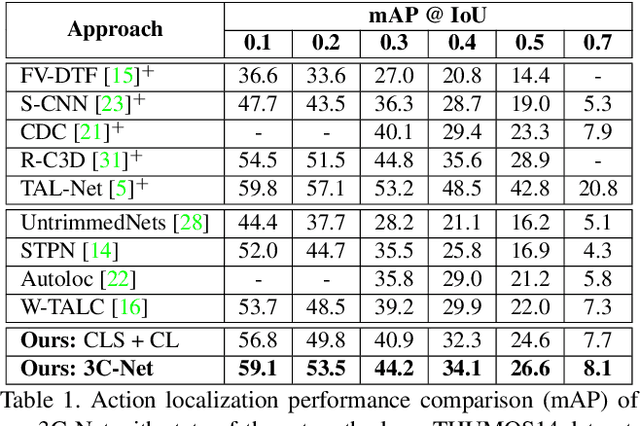
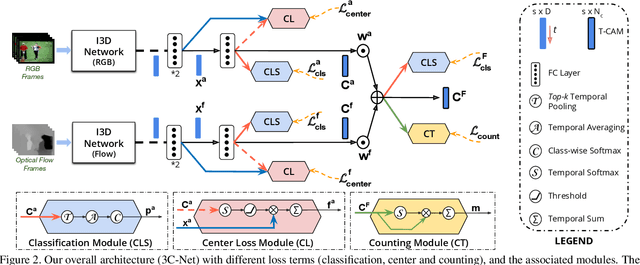
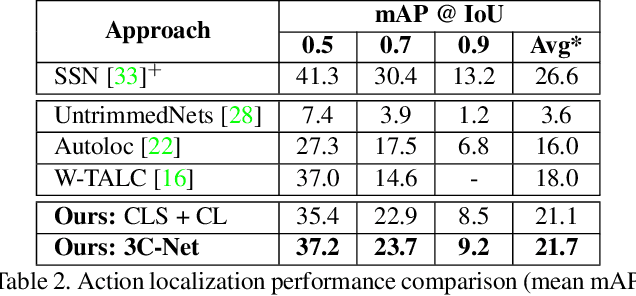
Temporal action localization is a challenging computer vision problem with numerous real-world applications. Most existing methods require laborious frame-level supervision to train action localization models. In this work, we propose a framework, called 3C-Net, which only requires video-level supervision (weak supervision) in the form of action category labels and the corresponding count. We introduce a novel formulation to learn discriminative action features with enhanced localization capabilities. Our joint formulation has three terms: a classification term to ensure the separability of learned action features, an adapted multi-label center loss term to enhance the action feature discriminability and a counting loss term to delineate adjacent action sequences, leading to improved localization. Comprehensive experiments are performed on two challenging benchmarks: THUMOS14 and ActivityNet 1.2. Our approach sets a new state-of-the-art for weakly-supervised temporal action localization on both datasets. On the THUMOS14 dataset, the proposed method achieves an absolute gain of 4.6% in terms of mean average precision (mAP), compared to the state-of-the-art. Source code is available at https://github.com/naraysa/3c-net.
Dual-reference Age Synthesis
Aug 07, 2019

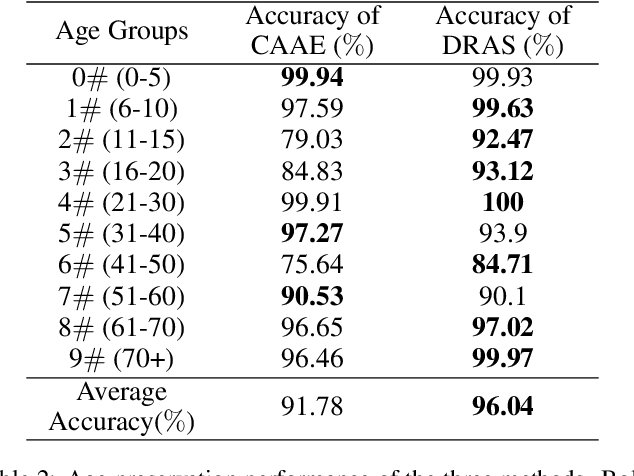
Age synthesis has received much attention in recent years. State-of-the-art methods typically take an input image and utilize a numeral to control the age of the generated image. In this paper, we revisit the age synthesis and ask: is a numeral capable enough to describe the human age? We propose a new framework Dual-reference Age Synthesis (DRAS) that takes two images as inputs to generate an image which shares the same personality of the first image and has the similar age with the second image. In the proposed framework, we employ a joint manifold feature which consists of disentangled age and identity information. The final images are generated by training a generative adversarial network which competes against an age agent and an identity agent. Experimental results demonstrate the appealing performance and flexibility of the proposed framework by comparing with the state-of-the-art and ground truth.