 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Aware Caching for Efficient Autoregressive Video Generation
May 03, 2026Autoregressive video generation paradigms offer theoretical promise for long video synthesis, yet their practical deployment is hindered by the computational burden of sequential iterative denoising. While cache reuse strategies can accelerate generation by skipping redundant denoising steps, existing methods rely on coarse-grained chunk-level skipping that fails to capture fine-grained pixel dynamics. This oversight is critical: pixels with high motion require more denoising steps to prevent error accumulation, while static pixels tolerate aggressive skipping. We formalize this insight theoretically by linking cache errors to residual instability, and propose MotionCache, a motion-aware cache framework that exploits inter-frame differences as a lightweight proxy for pixel-level motion characteristics. MotionCache employs a coarse-to-fine strategy: an initial warm-up phase establishes semantic coherence, followed by motion-weighted cache reuse that dynamically adjusts update frequencies per token. Extensive experiments on state-of-the-art models like SkyReels-V2 and MAGI-1 demonstrate that MotionCache achieves significant speedups of $\textbf{6.28}\times$ and $\textbf{1.64}\times$ respectively, while effectively preserving generation quality (VBench: $1\%\downarrow$ and $0.01\%\downarrow$ respectively). The code is available at https://github.com/ywlq/MotionCache.
DreamLite: A Lightweight On-Device Unified Model for Image Generation and Editing
Mar 30, 2026Diffusion models have made significant progress in both text-to-image (T2I) generation and text-guided image editing. However, these models are typically built with billions of parameters, leading to high latency and increased deployment challenges. While on-device diffusion models improve efficiency, they largely focus on T2I generation and lack support for image editing. In this paper, we propose DreamLite, a compact unified on-device diffusion model (0.39B) that supports both T2I generation and text-guided image editing within a single network. DreamLite is built on a pruned mobile U-Net backbone and unifies conditioning through in-context spatial concatenation in the latent space. It concatenates images horizontally as input, using a (target | blank) configuration for generation tasks and (target | source) for editing tasks. To stabilize the training of this compact model, we introduce a task-progressive joint pretraining strategy that sequentially targets T2I, editing, and joint tasks. After high-quality SFT and reinforcement learning, DreamLite achieves GenEval (0.72) for image generation and ImgEdit (4.11) for image editing, outperforming existing on-device models and remaining competitive with several server-side models. By employing step distillation, we further reduce denoising processing to just 4 steps, enabling our DreamLite could generate or edit a 1024 x 1024 image in less than 1s on a Xiaomi 14 smartphone. To the best of our knowledge, DreamLite is the first unified on-device diffusion model that supports both image generation and image editing.
S2O: Early Stopping for Sparse Attention via Online Permutation
Feb 26, 2026Attention scales quadratically with sequence length, fundamentally limiting long-context inference. Existing block-granularity sparsification can reduce latency, but coarse blocks impose an intrinsic sparsity ceiling, making further improvements difficult even with carefully engineered designs. We present S2O, which performs early stopping for sparse attention via online permutation. Inspired by virtual-to-physical address mapping in memory systems, S2O revisits and factorizes FlashAttention execution, enabling inference to load non-contiguous tokens rather than a contiguous span in the original order. Motivated by fine-grained structures in attention heatmaps, we transform explicit permutation into an online, index-guided, discrete loading policy; with extremely lightweight preprocessing and index-remapping overhead, it concentrates importance on a small set of high-priority blocks. Building on this importance-guided online permutation for loading, S2O further introduces an early-stopping rule: computation proceeds from high to low importance; once the current block score falls below a threshold, S2O terminates early and skips the remaining low-contribution blocks, thereby increasing effective sparsity and reducing computation under a controlled error budget. As a result, S2O substantially raises the practical sparsity ceiling. On Llama-3.1-8B under a 128K context, S2O reduces single-operator MSE by 3.82$\times$ at matched sparsity, and reduces prefill compute density by 3.31$\times$ at matched MSE; meanwhile, it preserves end-to-end accuracy and achieves 7.51$\times$ attention and 3.81$\times$ end-to-end speedups.
Hybrid SD: Edge-Cloud Collaborative Inference for Stable Diffusion Models
Aug 13, 2024



Stable Diffusion Models (SDMs) have shown remarkable proficiency in image synthesis. However, their broad application is impeded by their large model sizes and intensive computational requirements, which typically require expensive cloud servers for deployment. On the flip side, while there are many compact models tailored for edge devices that can reduce these demands, they often compromise on semantic integrity and visual quality when compared to full-sized SDMs. To bridge this gap, we introduce Hybrid SD, an innovative, training-free SDMs inference framework designed for edge-cloud collaborative inference. Hybrid SD distributes the early steps of the diffusion process to the large models deployed on cloud servers, enhancing semantic planning. Furthermore, small efficient models deployed on edge devices can be integrated for refining visual details in the later stages. Acknowledging the diversity of edge devices with differing computational and storage capacities, we employ structural pruning to the SDMs U-Net and train a lightweight VAE. Empirical evaluations demonstrate that our compressed models achieve state-of-the-art parameter efficiency (225.8M) on edge devices with competitive image quality. Additionally, Hybrid SD reduces the cloud cost by 66% with edge-cloud collaborative inference.
FoldGPT: Simple and Effective Large Language Model Compression Scheme
Jul 01, 2024The demand for deploying large language models(LLMs) on mobile devices continues to increase, driven by escalating data security concerns and cloud costs. However, network bandwidth and memory limitations pose challenges for deploying billion-level models on mobile devices. In this study, we investigate the outputs of different layers across various scales of LLMs and found that the outputs of most layers exhibit significant similarity. Moreover, this similarity becomes more pronounced as the model size increases, indicating substantial redundancy in the depth direction of the LLMs. Based on this observation, we propose an efficient model volume compression strategy, termed FoldGPT, which combines block removal and block parameter sharing.This strategy consists of three parts: (1) Based on the learnable gating parameters, we determine the block importance ranking while modeling the coupling effect between blocks. Then we delete some redundant layers based on the given removal rate. (2) For the retained blocks, we apply a specially designed group parameter sharing strategy, where blocks within the same group share identical weights, significantly compressing the number of parameters and slightly reducing latency overhead. (3) After sharing these Blocks, we "cure" the mismatch caused by sparsity with a minor amount of fine-tuning and introduce a tail-layer distillation strategy to improve the performance. Experiments demonstrate that FoldGPT outperforms previous state-of-the-art(SOTA) methods in efficient model compression, demonstrating the feasibility of achieving model lightweighting through straightforward block removal and parameter sharing.
Differentiable Search for Finding Optimal Quantization Strategy
Apr 15, 2024



To accelerate and compress deep neural networks (DNNs), many network quantization algorithms have been proposed. Although the quantization strategy of any algorithm from the state-of-the-arts may outperform others in some network architectures, it is hard to prove the strategy is always better than others, and even cannot judge that the strategy is always the best choice for all layers in a network. In other words, existing quantization algorithms are suboptimal as they ignore the different characteristics of different layers and quantize all layers by a uniform quantization strategy. To solve the issue, in this paper, we propose a differentiable quantization strategy search (DQSS) to assign optimal quantization strategy for individual layer by taking advantages of the benefits of different quantization algorithms. Specifically, we formulate DQSS as a differentiable neural architecture search problem and adopt an efficient convolution to efficiently explore the mixed quantization strategies from a global perspective by gradient-based optimization. We conduct DQSS for post-training quantization to enable their performance to be comparable with that in full precision models. We also employ DQSS in quantization-aware training for further validating the effectiveness of DQSS. To circumvent the expensive optimization cost when employing DQSS in quantization-aware training, we update the hyper-parameters and the network parameters in a single forward-backward pass. Besides, we adjust the optimization process to avoid the potential under-fitting problem. Comprehensive experiments on high level computer vision task, i.e., image classification, and low level computer vision task, i.e., image super-resolution, with various network architectures show that DQSS could outperform the state-of-the-arts.
SparseByteNN: A Novel Mobile Inference Acceleration Framework Based on Fine-Grained Group Sparsity
Oct 30, 2023



To address the challenge of increasing network size, researchers have developed sparse models through network pruning. However, maintaining model accuracy while achieving significant speedups on general computing devices remains an open problem. In this paper, we present a novel mobile inference acceleration framework SparseByteNN, which leverages fine-grained kernel sparsity to achieve real-time execution as well as high accuracy. Our framework consists of two parts: (a) A fine-grained kernel sparsity schema with a sparsity granularity between structured pruning and unstructured pruning. It designs multiple sparse patterns for different operators. Combined with our proposed whole network rearrangement strategy, the schema achieves a high compression rate and high precision at the same time. (b) Inference engine co-optimized with the sparse pattern. The conventional wisdom is that this reduction in theoretical FLOPs does not translate into real-world efficiency gains. We aim to correct this misconception by introducing a family of efficient sparse kernels for ARM and WebAssembly. Equipped with our efficient implementation of sparse primitives, we show that sparse versions of MobileNet-v1 outperform strong dense baselines on the efficiency-accuracy curve. Experimental results on Qualcomm 855 show that for 30% sparse MobileNet-v1, SparseByteNN achieves 1.27x speedup over the dense version and 1.29x speedup over the state-of-the-art sparse inference engine MNN with a slight accuracy drop of 0.224%. The source code of SparseByteNN will be available at https://github.com/lswzjuer/SparseByteNN
Privacy-preserving Online AutoML for Domain-Specific Face Detection
Mar 16, 2022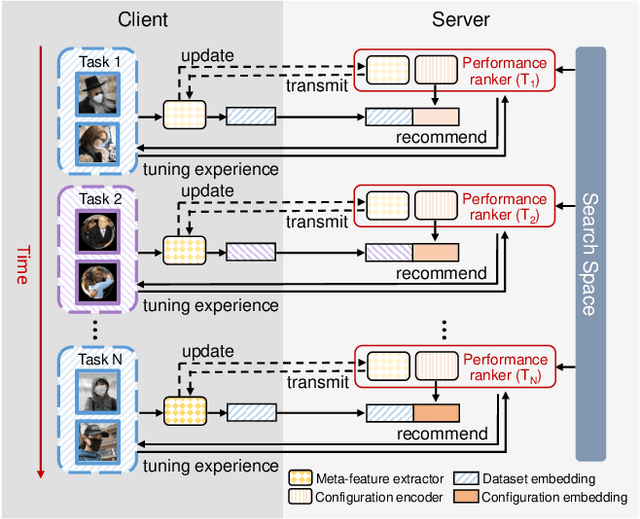
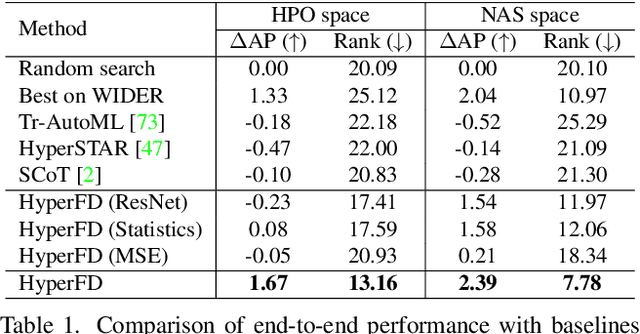
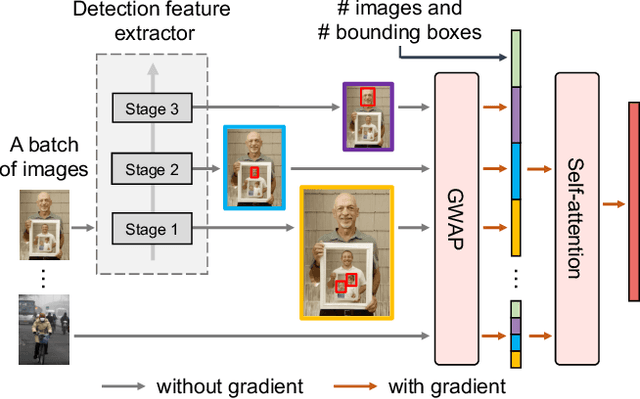
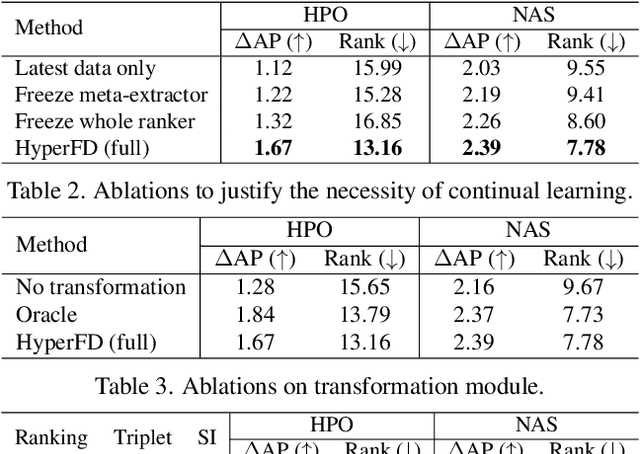
Despite the impressive progress of general face detection, the tuning of hyper-parameters and architectures is still critical for the performance of a domain-specific face detector. Though existing AutoML works can speedup such process, they either require tuning from scratch for a new scenario or do not consider data privacy. To scale up, we derive a new AutoML setting from a platform perspective. In such setting, new datasets sequentially arrive at the platform, where an architecture and hyper-parameter configuration is recommended to train the optimal face detector for each dataset. This, however, brings two major challenges: (1) how to predict the best configuration for any given dataset without touching their raw images due to the privacy concern? and (2) how to continuously improve the AutoML algorithm from previous tasks and offer a better warm-up for future ones? We introduce "HyperFD", a new privacy-preserving online AutoML framework for face detection. At its core part, a novel meta-feature representation of a dataset as well as its learning paradigm is proposed. Thanks to HyperFD, each local task (client) is able to effectively leverage the learning "experience" of previous tasks without uploading raw images to the platform; meanwhile, the meta-feature extractor is continuously learned to better trade off the bias and variance. Extensive experiments demonstrate the effectiveness and efficiency of our design.
AceNAS: Learning to Rank Ace Neural Architectures with Weak Supervision of Weight Sharing
Aug 06, 2021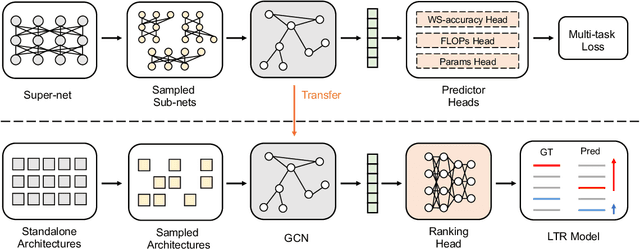
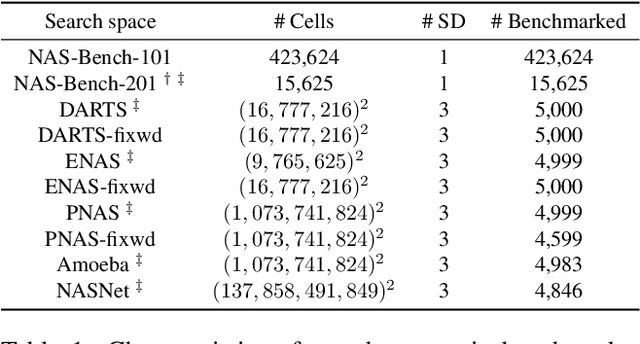
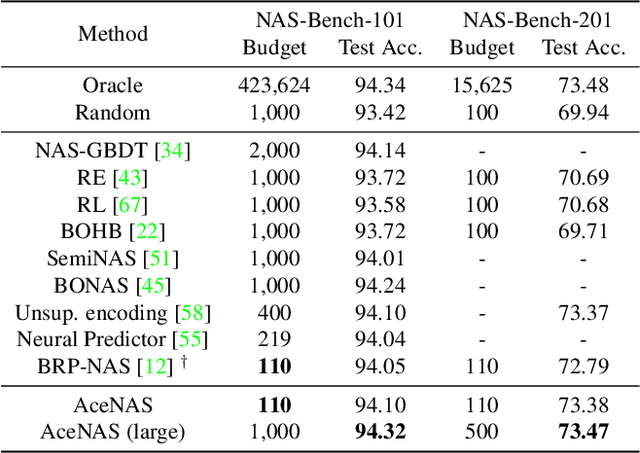
Architecture performance predictors have been widely used in neural architecture search (NAS). Although they are shown to be simple and effective, the optimization objectives in previous arts (e.g., precise accuracy estimation or perfect ranking of all architectures in the space) did not capture the ranking nature of NAS. In addition, a large number of ground-truth architecture-accuracy pairs are usually required to build a reliable predictor, making the process too computationally expensive. To overcome these, in this paper, we look at NAS from a novel point of view and introduce Learning to Rank (LTR) methods to select the best (ace) architectures from a space. Specifically, we propose to use Normalized Discounted Cumulative Gain (NDCG) as the target metric and LambdaRank as the training algorithm. We also propose to leverage weak supervision from weight sharing by pretraining architecture representation on weak labels obtained from the super-net and then finetuning the ranking model using a small number of architectures trained from scratch. Extensive experiments on NAS benchmarks and large-scale search spaces demonstrate that our approach outperforms SOTA with a significantly reduced search cost.
PAMS: Quantized Super-Resolution via Parameterized Max Scale
Nov 09, 2020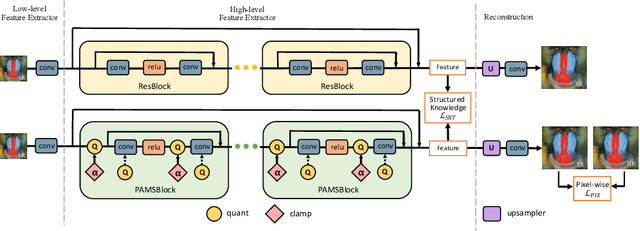

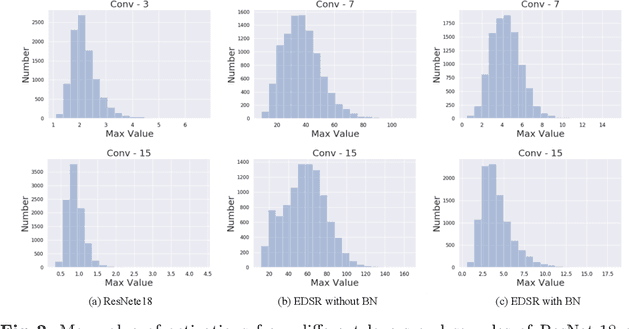
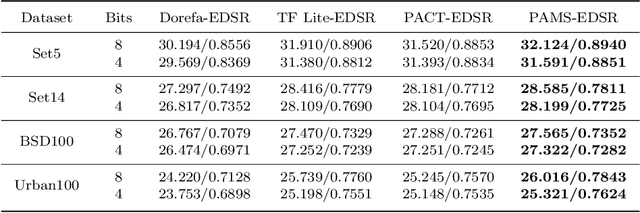
Deep convolutional neural networks (DCNNs) have shown dominant performance in the task of super-resolution (SR). However, their heavy memory cost and computation overhead significantly restrict their practical deployments on resource-limited devices, which mainly arise from the floating-point storage and operations between weights and activations. Although previous endeavors mainly resort to fixed-point operations, quantizing both weights and activations with fixed coding lengths may cause significant performance drop, especially on low bits. Specifically, most state-of-the-art SR models without batch normalization have a large dynamic quantization range, which also serves as another cause of performance drop. To address these two issues, we propose a new quantization scheme termed PArameterized Max Scale (PAMS), which applies the trainable truncated parameter to explore the upper bound of the quantization range adaptively. Finally, a structured knowledge transfer (SKT) loss is introduced to fine-tune the quantized network. Extensive experiments demonstrate that the proposed PAMS scheme can well compress and accelerate the existing SR models such as EDSR and RDN. Notably, 8-bit PAMS-EDSR improves PSNR on Set5 benchmark from 32.095dB to 32.124dB with 2.42$\times$ compression ratio, which achieves a new state-of-the-art.