 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Saliency Transformer
Apr 25, 2021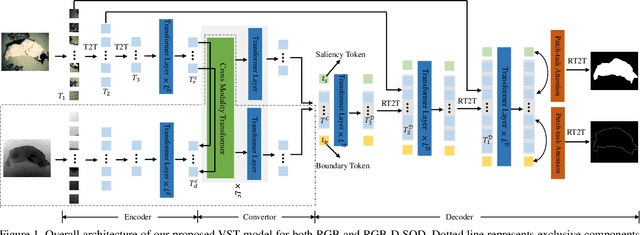
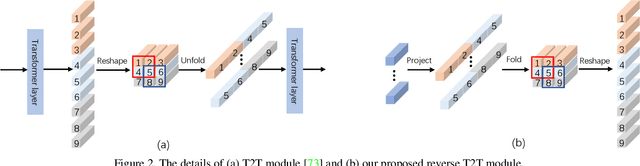
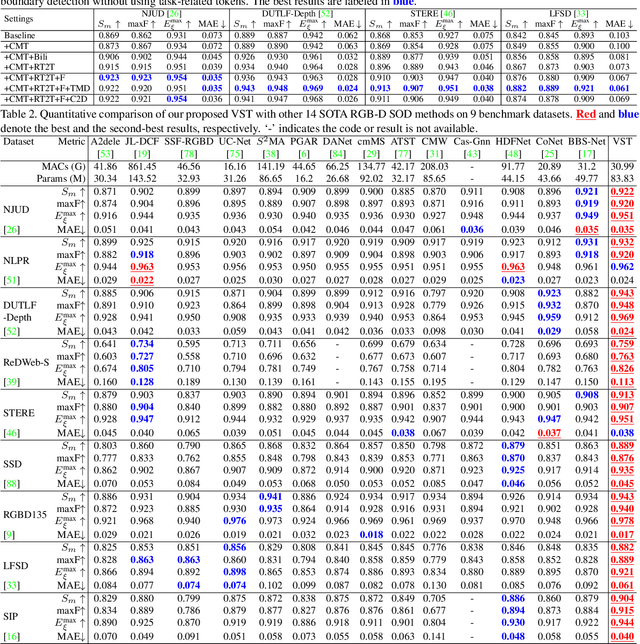
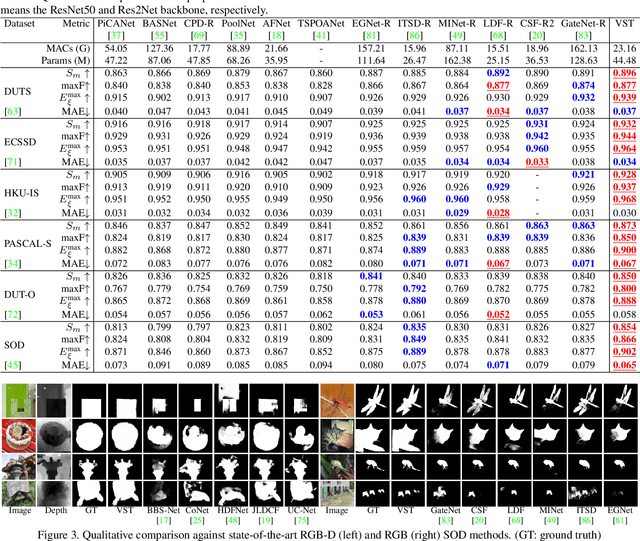
Recently, massive saliency detection methods have achieved promising results by relying on CNN-based architectures. Alternatively, we rethink this task from a convolution-free sequence-to-sequence perspective and predict saliency by modeling long-range dependencies, which can not be achieved by convolution. Specifically, we develop a novel unified model based on a pure transformer, namely, Visual Saliency Transformer (VST), for both RGB and RGB-D salient object detection (SOD). It takes image patches as inputs and leverages the transformer to propagate global contexts among image patches. Apart from the traditional transformer architecture used in Vision Transformer (ViT), we leverage multi-level token fusion and propose a new token upsampling method under the transformer framework to get high-resolution detection results. We also develop a token-based multi-task decoder to simultaneously perform saliency and boundary detection by introducing task-related tokens and a novel patch-task-attention mechanism. Experimental results show that our model outperforms existing state-of-the-art results on both RGB and RGB-D SOD benchmark datasets. Most importantly, our whole framework not only provides a new perspective for the SOD field but also shows a new paradigm for transformer-based dense prediction models.
Repetitive Activity Counting by Sight and Sound
Apr 17, 2021



This paper strives for repetitive activity counting in videos. Different from existing works, which all analyze the visual video content only, we incorporate for the first time the corresponding sound into the repetition counting process. This benefits accuracy in challenging vision conditions such as occlusion, dramatic camera view changes, low resolution, etc. We propose a model that starts with analyzing the sight and sound streams separately. Then an audiovisual temporal stride decision module and a reliability estimation module are introduced to exploit cross-modal temporal interaction. For learning and evaluation, an existing dataset is repurposed and reorganized to allow for repetition counting with sight and sound. We also introduce a variant of this dataset for repetition counting under challenging vision conditions. Experiments demonstrate the benefit of sound, as well as the other introduced modules, for repetition counting. Our sight-only model already outperforms the state-of-the-art by itself, when we add sound, results improve notably, especially under harsh vision conditions.
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Apr 15, 2021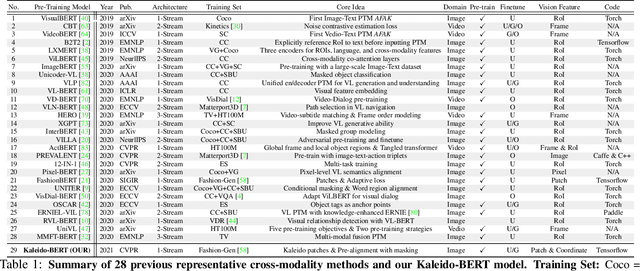
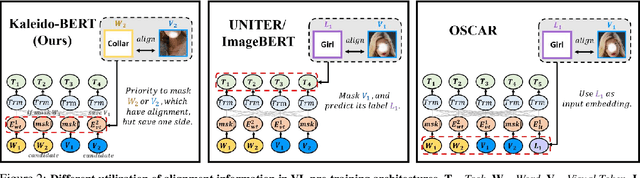
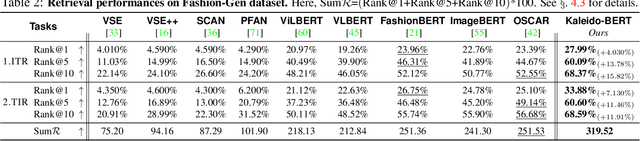
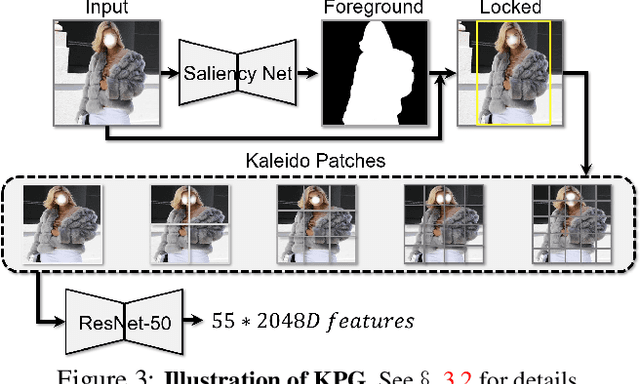
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.
Cloth Interactive Transformer for Virtual Try-On
Apr 12, 20212D image-based virtual try-on has attracted increased attention from the multimedia and computer vision communities. However, most of the existing image-based virtual try-on methods directly put both person and the in-shop clothing representations together, without considering the mutual correlation between them. What is more, the long-range information, which is crucial for generating globally consistent results, is also hard to be established via the regular convolution operation. To alleviate these two problems, in this paper we propose a novel two-stage Cloth Interactive Transformer (CIT) for virtual try-on. In the first stage, we design a CIT matching block, aiming to perform a learnable thin-plate spline transformation that can capture more reasonable long-range relation. As a result, the warped in-shop clothing looks more natural. In the second stage, we propose a novel CIT reasoning block for establishing the global mutual interactive dependence. Based on this mutual dependence, the significant region within the input data can be highlighted, and consequently, the try-on results can become more realistic. Extensive experiments on a public fashion dataset demonstrate that our CIT can achieve the new state-of-the-art virtual try-on performance both qualitatively and quantitatively. The source code and trained models are available at https://github.com/Amazingren/CIT.
Dual-Octave Convolution for Accelerated Parallel MR Image Reconstruction
Apr 12, 2021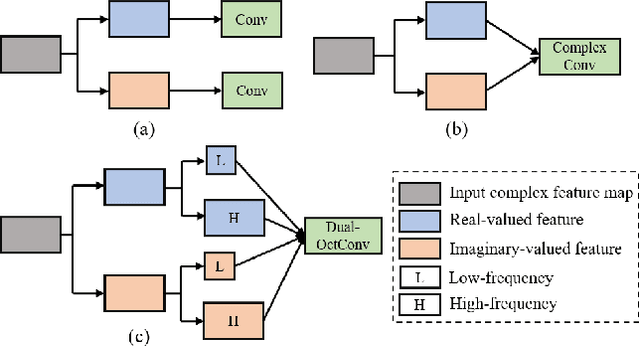
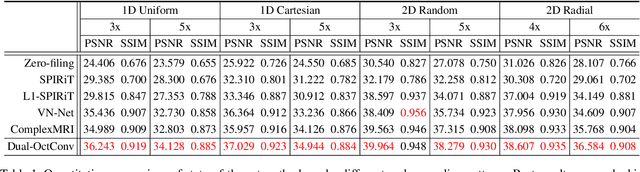
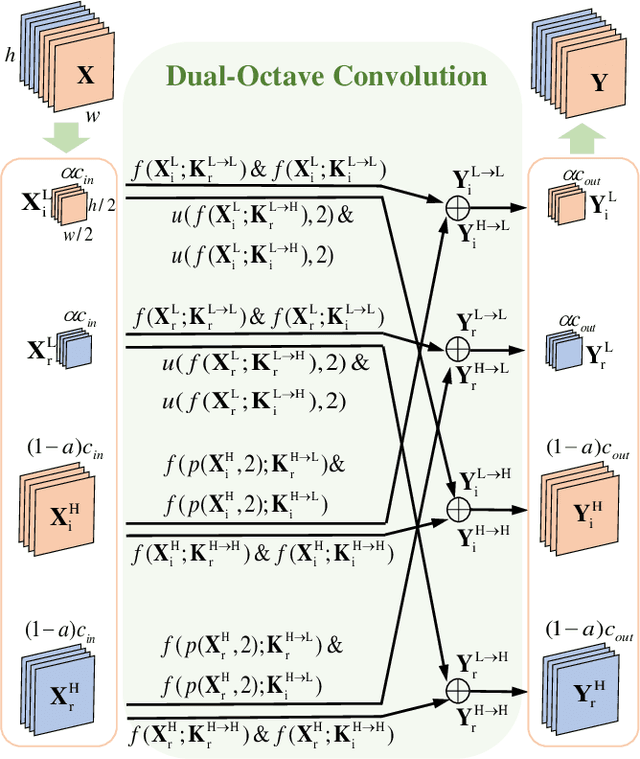
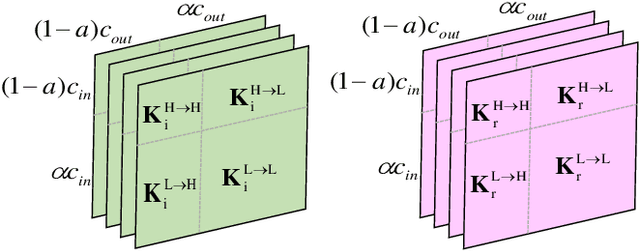
Magnetic resonance (MR) image acquisition is an inherently prolonged process, whose acceleration by obtaining multiple undersampled images simultaneously through parallel imaging has always been the subject of research. In this paper, we propose the Dual-Octave Convolution (Dual-OctConv), which is capable of learning multi-scale spatial-frequency features from both real and imaginary components, for fast parallel MR image reconstruction. By reformulating the complex operations using octave convolutions, our model shows a strong ability to capture richer representations of MR images, while at the same time greatly reducing the spatial redundancy. More specifically, the input feature maps and convolutional kernels are first split into two components (i.e., real and imaginary), which are then divided into four groups according to their spatial frequencies. Then, our Dual-OctConv conducts intra-group information updating and inter-group information exchange to aggregate the contextual information across different groups. Our framework provides two appealing benefits: (i) it encourages interactions between real and imaginary components at various spatial frequencies to achieve richer representational capacity, and (ii) it enlarges the receptive field by learning multiple spatial-frequency features of both the real and imaginary components. We evaluate the performance of the proposed model on the acceleration of multi-coil MR image reconstruction. Extensive experiments are conducted on an {in vivo} knee dataset under different undersampling patterns and acceleration factors. The experimental results demonstrate the superiority of our model in accelerated parallel MR image reconstruction. Our code is available at: github.com/chunmeifeng/Dual-OctConv.
* Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI) 2021
Target-Aware Object Discovery and Association for Unsupervised Video Multi-Object Segmentation
Apr 10, 2021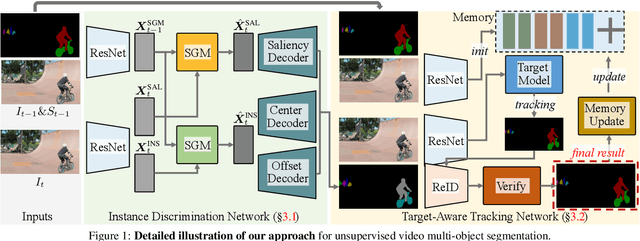
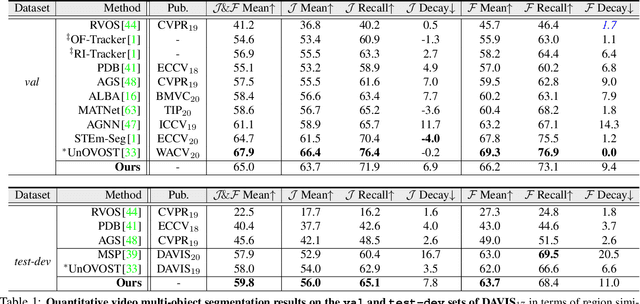
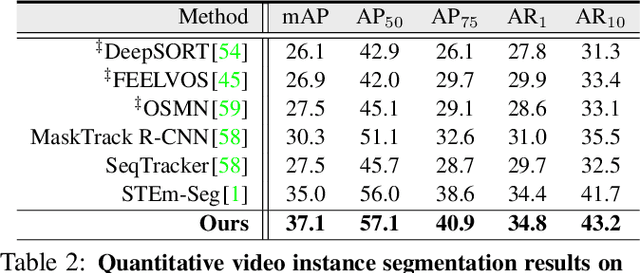

This paper addresses the task of unsupervised video multi-object segmentation. Current approaches follow a two-stage paradigm: 1) detect object proposals using pre-trained Mask R-CNN, and 2) conduct generic feature matching for temporal association using re-identification techniques. However, the generic features, widely used in both stages, are not reliable for characterizing unseen objects, leading to poor generalization. To address this, we introduce a novel approach for more accurate and efficient spatio-temporal segmentation. In particular, to address \textbf{instance discrimination}, we propose to combine foreground region estimation and instance grouping together in one network, and additionally introduce temporal guidance for segmenting each frame, enabling more accurate object discovery. For \textbf{temporal association}, we complement current video object segmentation architectures with a discriminative appearance model, capable of capturing more fine-grained target-specific information. Given object proposals from the instance discrimination network, three essential strategies are adopted to achieve accurate segmentation: 1) target-specific tracking using a memory-augmented appearance model; 2) target-agnostic verification to trace possible tracklets for the proposal; 3) adaptive memory updating using the verified segments. We evaluate the proposed approach on DAVIS$_{17}$ and YouTube-VIS, and the results demonstrate that it outperforms state-of-the-art methods both in segmentation accuracy and inference speed.
Graph Sampling Based Deep Metric Learning for Generalizable Person Re-Identification
Apr 06, 2021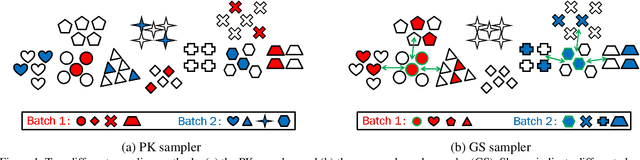
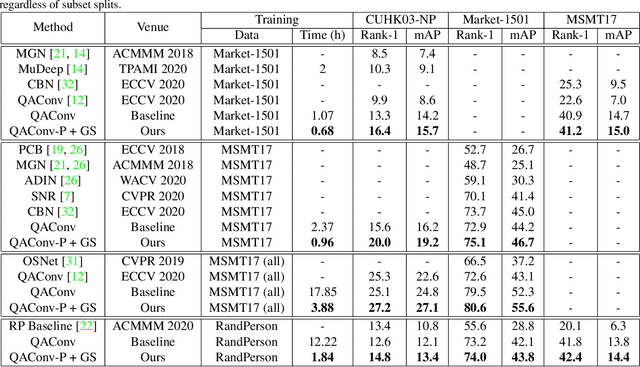
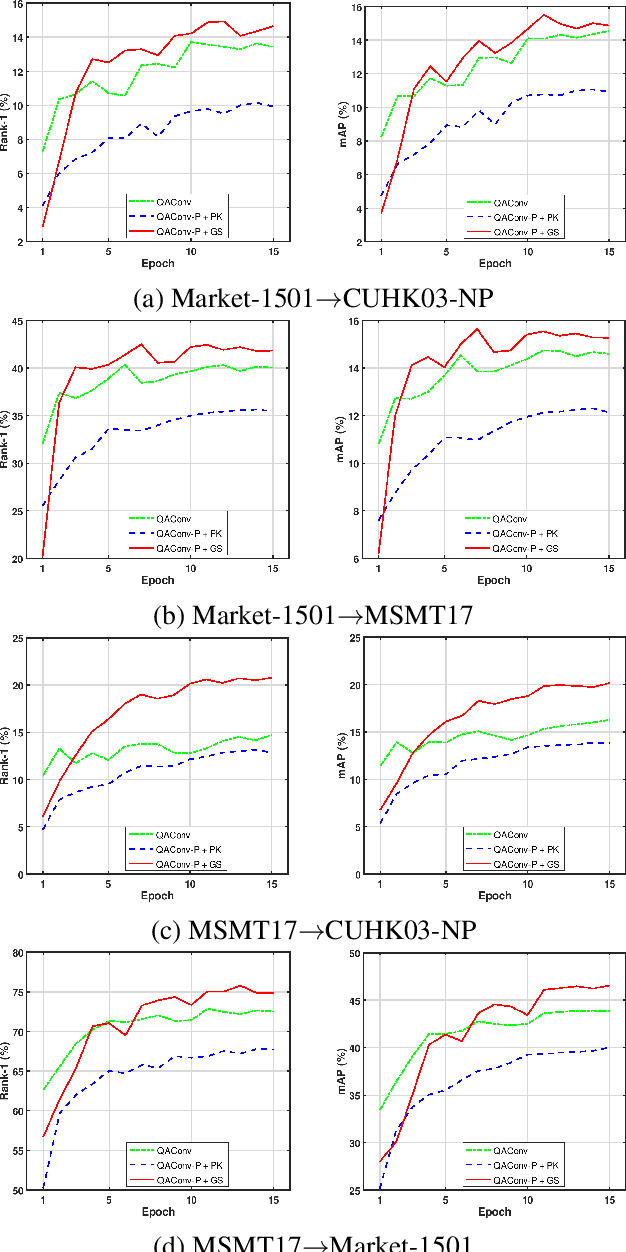
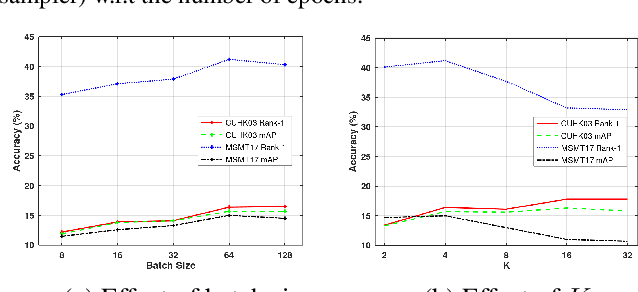
Generalizable person re-identification has recently got increasing attention due to its research values as well as practical values. However, the efficiency of learning from large-scale data has not yet been much studied. In this paper, we argue that the most popular random sampling method, the well-known PK sampler, is not informative and efficient for deep metric learning. Though online hard example mining improves the learning efficiency to some extent, the mining in mini batches after random sampling is still limited. Therefore, this inspires us that the hard example mining should be shifted backward to the data sampling stage. To address this, in this paper, we propose an efficient mini batch sampling method called Graph Sampling (GS) for large-scale metric learning. The basic idea is to build a nearest neighbor relationship graph for all classes at the beginning of each epoch. Then, each mini batch is composed of a randomly selected class and its nearest neighboring classes so as to provide informative and challenging examples for learning. Together with an adapted competitive baseline, we improve the previous state of the arts in generalizable person re-identification significantly, by up to 22.3% in Rank-1 and 15% in mAP. Besides, the proposed method also outperforms the competitive baseline by up to 4%, with the training time significantly reduced by up to x6.6, from 12.2 hours to 1.8 hours in training a large-scale dataset RandPerson with 8,000 IDs. Code is available at \url{https://github.com/ShengcaiLiao/QAConv}.
Distilling a Powerful Student Model via Online Knowledge Distillation
Mar 29, 2021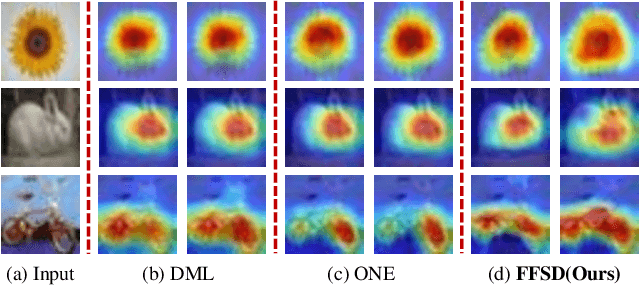
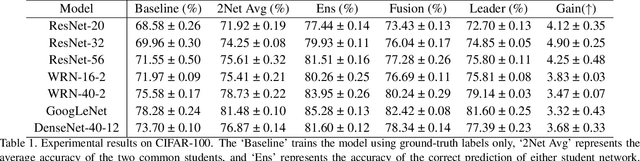
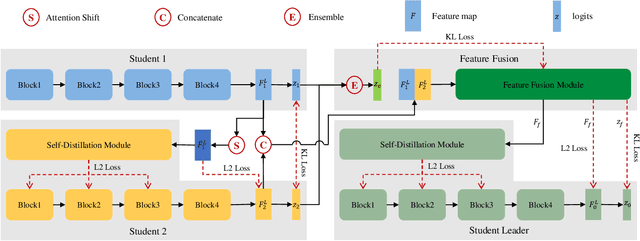
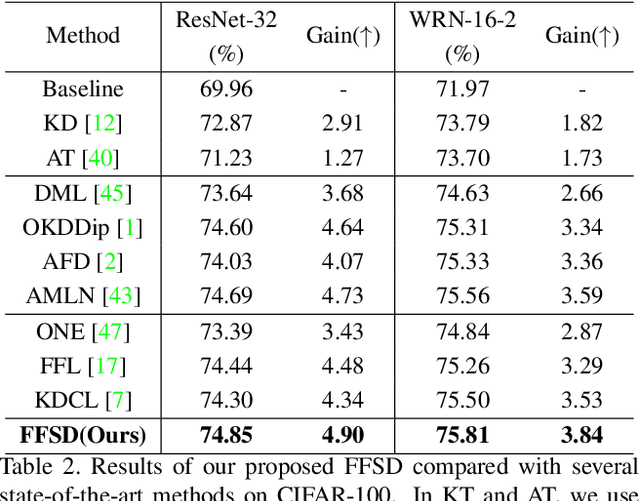
Existing online knowledge distillation approaches either adopt the student with the best performance or construct an ensemble model for better holistic performance. However, the former strategy ignores other students' information, while the latter increases the computational complexity. In this paper, we propose a novel method for online knowledge distillation, termed FFSD, which comprises two key components: Feature Fusion and Self-Distillation, towards solving the above problems in a unified framework. Different from previous works, where all students are treated equally, the proposed FFSD splits them into a student leader and a common student set. Then, the feature fusion module converts the concatenation of feature maps from all common students into a fused feature map. The fused representation is used to assist the learning of the student leader. To enable the student leader to absorb more diverse information, we design an enhancement strategy to increase the diversity among students. Besides, a self-distillation module is adopted to convert the feature map of deeper layers into a shallower one. Then, the shallower layers are encouraged to mimic the transformed feature maps of the deeper layers, which helps the students to generalize better. After training, we simply adopt the student leader, which achieves superior performance, over the common students, without increasing the storage or inference cost. Extensive experiments on CIFAR-100 and ImageNet demonstrate the superiority of our FFSD over existing works. The code is available at https://github.com/SJLeo/FFSD.
M3DSSD: Monocular 3D Single Stage Object Detector
Mar 24, 2021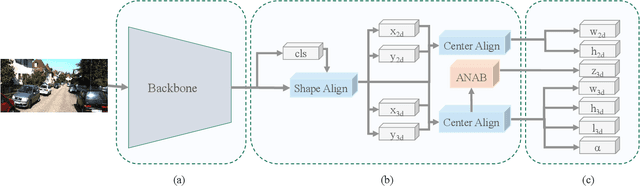
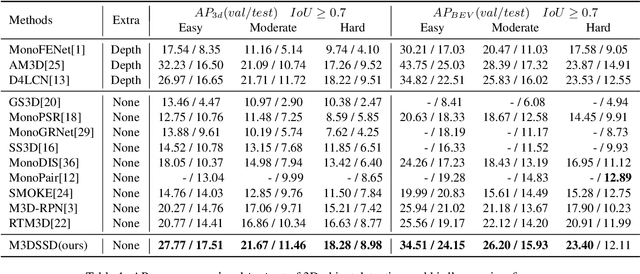
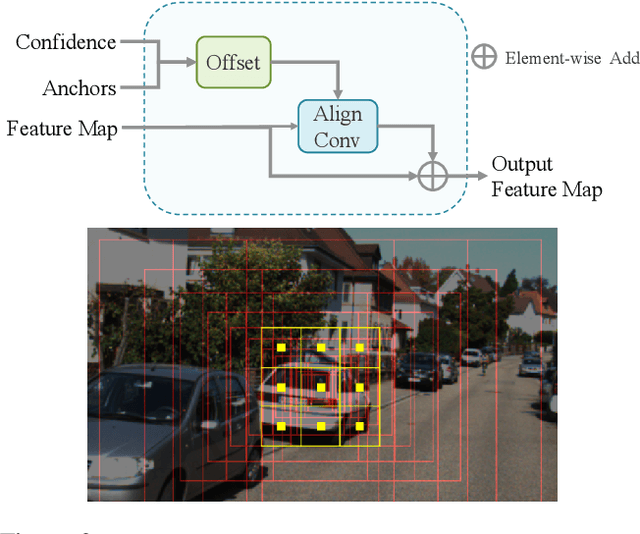
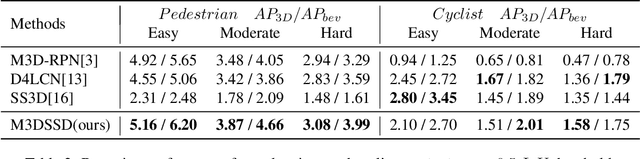
In this paper, we propose a Monocular 3D Single Stage object Detector (M3DSSD) with feature alignment and asymmetric non-local attention. Current anchor-based monocular 3D object detection methods suffer from feature mismatching. To overcome this, we propose a two-step feature alignment approach. In the first step, the shape alignment is performed to enable the receptive field of the feature map to focus on the pre-defined anchors with high confidence scores. In the second step, the center alignment is used to align the features at 2D/3D centers. Further, it is often difficult to learn global information and capture long-range relationships, which are important for the depth prediction of objects. Therefore, we propose a novel asymmetric non-local attention block with multi-scale sampling to extract depth-wise features. The proposed M3DSSD achieves significantly better performance than the monocular 3D object detection methods on the KITTI dataset, in both 3D object detection and bird's eye view tasks.
ReCU: Reviving the Dead Weights in Binary Neural Networks
Mar 23, 2021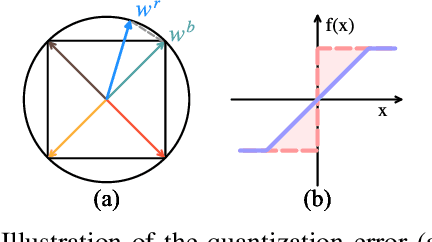
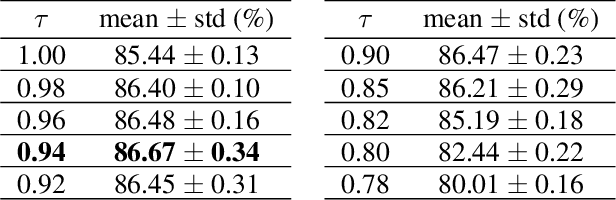
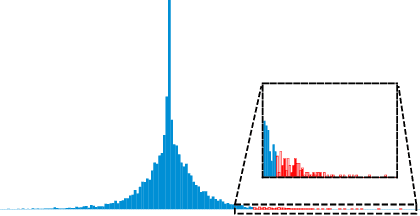
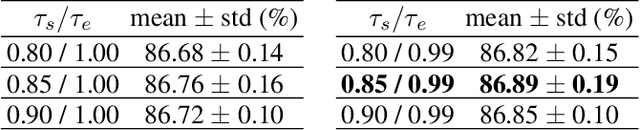
Binary neural networks (BNNs) have received increasing attention due to their superior reductions of computation and memory. Most existing works focus on either lessening the quantization error by minimizing the gap between the full-precision weights and their binarization or designing a gradient approximation to mitigate the gradient mismatch, while leaving the "dead weights" untouched. This leads to slow convergence when training BNNs. In this paper, for the first time, we explore the influence of "dead weights" which refer to a group of weights that are barely updated during the training of BNNs, and then introduce rectified clamp unit (ReCU) to revive the "dead weights" for updating. We prove that reviving the "dead weights" by ReCU can result in a smaller quantization error. Besides, we also take into account the information entropy of the weights, and then mathematically analyze why the weight standardization can benefit BNNs. We demonstrate the inherent contradiction between minimizing the quantization error and maximizing the information entropy, and then propose an adaptive exponential scheduler to identify the range of the "dead weights". By considering the "dead weights", our method offers not only faster BNN training, but also state-of-the-art performance on CIFAR-10 and ImageNet, compared with recent methods. Code can be available at [this https URL](https://github.com/z-hXu/ReCU).