 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.
Pruner: An Efficient Cross-Platform Tensor Compiler with Dual Awareness
Feb 04, 2024Tensor program optimization on Deep Learning Accelerators (DLAs) is critical for efficient model deployment. Although search-based Deep Learning Compilers (DLCs) have achieved significant performance gains compared to manual methods, they still suffer from the persistent challenges of low search efficiency and poor cross-platform adaptability. In this paper, we propose $\textbf{Pruner}$, following hardware/software co-design principles to hierarchically boost tensor program optimization. Pruner comprises two primary components: a Parameterized Static Analyzer ($\textbf{PSA}$) and a Pattern-aware Cost Model ($\textbf{PaCM}$). The former serves as a hardware-aware and formulaic performance analysis tool, guiding the pruning of the search space, while the latter enables the performance prediction of tensor programs according to the critical data-flow patterns. Furthermore, to ensure effective cross-platform adaptation, we design a Momentum Transfer Learning ($\textbf{MTL}$) strategy using a Siamese network, which establishes a bidirectional feedback mechanism to improve the robustness of the pre-trained cost model. The extensive experimental results demonstrate the effectiveness and advancement of the proposed Pruner in various tensor program tuning tasks across both online and offline scenarios, with low resource overhead. The code is available at https://github.com/qiaolian9/Pruner.
SM$^3$: Self-Supervised Multi-task Modeling with Multi-view 2D Images for Articulated Objects
Jan 17, 2024



Reconstructing real-world objects and estimating their movable joint structures are pivotal technologies within the field of robotics. Previous research has predominantly focused on supervised approaches, relying on extensively annotated datasets to model articulated objects within limited categories. However, this approach falls short of effectively addressing the diversity present in the real world. To tackle this issue, we propose a self-supervised interaction perception method, referred to as SM$^3$, which leverages multi-view RGB images captured before and after interaction to model articulated objects, identify the movable parts, and infer the parameters of their rotating joints. By constructing 3D geometries and textures from the captured 2D images, SM$^3$ achieves integrated optimization of movable part and joint parameters during the reconstruction process, obviating the need for annotations. Furthermore, we introduce the MMArt dataset, an extension of PartNet-Mobility, encompassing multi-view and multi-modal data of articulated objects spanning diverse categories. Evaluations demonstrate that SM$^3$ surpasses existing benchmarks across various categories and objects, while its adaptability in real-world scenarios has been thoroughly validated.
Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detection
Aug 28, 2023



Knowledge distillation (KD) has shown potential for learning compact models in dense object detection. However, the commonly used softmax-based distillation ignores the absolute classification scores for individual categories. Thus, the optimum of the distillation loss does not necessarily lead to the optimal student classification scores for dense object detectors. This cross-task protocol inconsistency is critical, especially for dense object detectors, since the foreground categories are extremely imbalanced. To address the issue of protocol differences between distillation and classification, we propose a novel distillation method with cross-task consistent protocols, tailored for the dense object detection. For classification distillation, we address the cross-task protocol inconsistency problem by formulating the classification logit maps in both teacher and student models as multiple binary-classification maps and applying a binary-classification distillation loss to each map. For localization distillation, we design an IoU-based Localization Distillation Loss that is free from specific network structures and can be compared with existing localization distillation losses. Our proposed method is simple but effective, and experimental results demonstrate its superiority over existing methods. Code is available at https://github.com/TinyTigerPan/BCKD.
H-DenseFormer: An Efficient Hybrid Densely Connected Transformer for Multimodal Tumor Segmentation
Jul 04, 2023



Recently, deep learning methods have been widely used for tumor segmentation of multimodal medical images with promising results. However, most existing methods are limited by insufficient representational ability, specific modality number and high computational complexity. In this paper, we propose a hybrid densely connected network for tumor segmentation, named H-DenseFormer, which combines the representational power of the Convolutional Neural Network (CNN) and the Transformer structures. Specifically, H-DenseFormer integrates a Transformer-based Multi-path Parallel Embedding (MPE) module that can take an arbitrary number of modalities as input to extract the fusion features from different modalities. Then, the multimodal fusion features are delivered to different levels of the encoder to enhance multimodal learning representation. Besides, we design a lightweight Densely Connected Transformer (DCT) block to replace the standard Transformer block, thus significantly reducing computational complexity. We conduct extensive experiments on two public multimodal datasets, HECKTOR21 and PI-CAI22. The experimental results show that our proposed method outperforms the existing state-of-the-art methods while having lower computational complexity. The source code is available at https://github.com/shijun18/H-DenseFormer.
Weakly Supervised Lesion Detection and Diagnosis for Breast Cancers with Partially Annotated Ultrasound Images
Jun 12, 2023Deep learning (DL) has proven highly effective for ultrasound-based computer-aided diagnosis (CAD) of breast cancers. In an automaticCAD system, lesion detection is critical for the following diagnosis. However, existing DL-based methods generally require voluminous manually-annotated region of interest (ROI) labels and class labels to train both the lesion detection and diagnosis models. In clinical practice, the ROI labels, i.e. ground truths, may not always be optimal for the classification task due to individual experience of sonologists, resulting in the issue of coarse annotation that limits the diagnosis performance of a CAD model. To address this issue, a novel Two-Stage Detection and Diagnosis Network (TSDDNet) is proposed based on weakly supervised learning to enhance diagnostic accuracy of the ultrasound-based CAD for breast cancers. In particular, all the ROI-level labels are considered as coarse labels in the first training stage, and then a candidate selection mechanism is designed to identify optimallesion areas for both the fully and partially annotated samples. It refines the current ROI-level labels in the fully annotated images and the detected ROIs in the partially annotated samples with a weakly supervised manner under the guidance of class labels. In the second training stage, a self-distillation strategy further is further proposed to integrate the detection network and classification network into a unified framework as the final CAD model for joint optimization, which then further improves the diagnosis performance. The proposed TSDDNet is evaluated on a B-mode ultrasound dataset, and the experimental results show that it achieves the best performance on both lesion detection and diagnosis tasks, suggesting promising application potential.
Language Adaptive Weight Generation for Multi-task Visual Grounding
Jun 06, 2023



Although the impressive performance in visual grounding, the prevailing approaches usually exploit the visual backbone in a passive way, i.e., the visual backbone extracts features with fixed weights without expression-related hints. The passive perception may lead to mismatches (e.g., redundant and missing), limiting further performance improvement. Ideally, the visual backbone should actively extract visual features since the expressions already provide the blueprint of desired visual features. The active perception can take expressions as priors to extract relevant visual features, which can effectively alleviate the mismatches. Inspired by this, we propose an active perception Visual Grounding framework based on Language Adaptive Weights, called VG-LAW. The visual backbone serves as an expression-specific feature extractor through dynamic weights generated for various expressions. Benefiting from the specific and relevant visual features extracted from the language-aware visual backbone, VG-LAW does not require additional modules for cross-modal interaction. Along with a neat multi-task head, VG-LAW can be competent in referring expression comprehension and segmentation jointly. Extensive experiments on four representative datasets, i.e., RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame, validate the effectiveness of the proposed framework and demonstrate state-of-the-art performance.
Dynamic Low-Resolution Distillation for Cost-Efficient End-to-End Text Spotting
Jul 15, 2022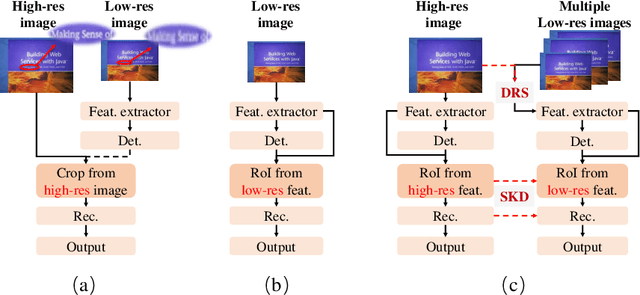
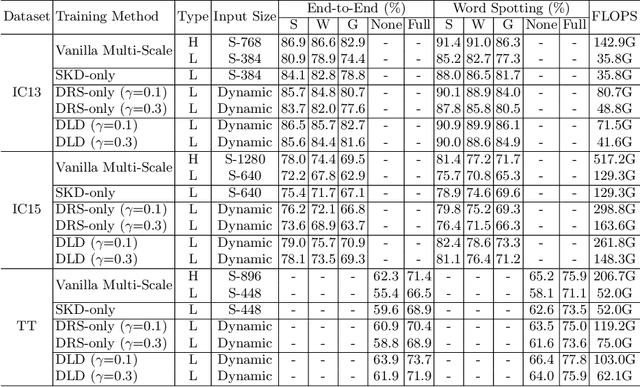
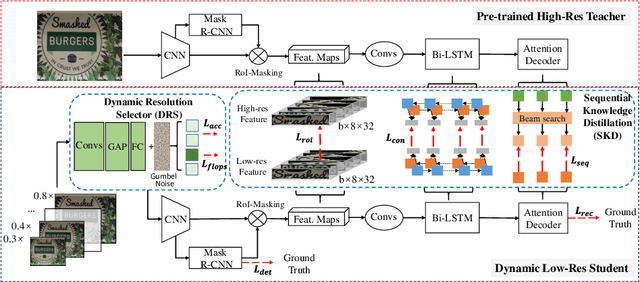
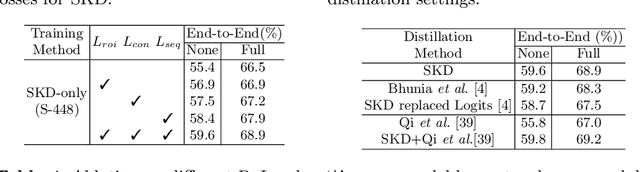
End-to-end text spotting has attached great attention recently due to its benefits on global optimization and high maintainability for real applications. However, the input scale has always been a tough trade-off since recognizing a small text instance usually requires enlarging the whole image, which brings high computational costs. In this paper, to address this problem, we propose a novel cost-efficient Dynamic Low-resolution Distillation (DLD) text spotting framework, which aims to infer images in different small but recognizable resolutions and achieve a better balance between accuracy and efficiency. Concretely, we adopt a resolution selector to dynamically decide the input resolutions for different images, which is constraint by both inference accuracy and computational cost. Another sequential knowledge distillation strategy is conducted on the text recognition branch, making the low-res input obtains comparable performance to a high-res image. The proposed method can be optimized end-to-end and adopted in any current text spotting framework to improve the practicability. Extensive experiments on several text spotting benchmarks show that the proposed method vastly improves the usability of low-res models. The code is available at https://github.com/hikopensource/DAVAR-Lab-OCR/.
DavarOCR: A Toolbox for OCR and Multi-Modal Document Understanding
Jul 14, 2022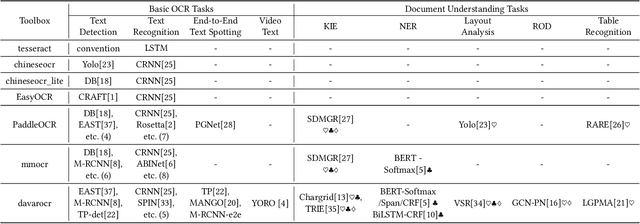


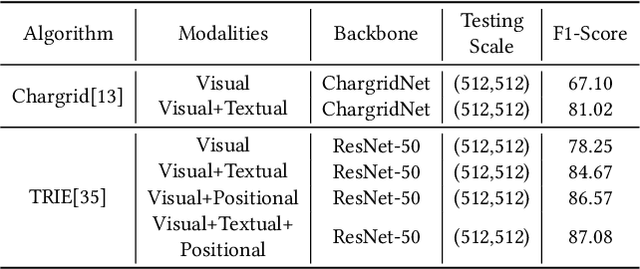
This paper presents DavarOCR, an open-source toolbox for OCR and document understanding tasks. DavarOCR currently implements 19 advanced algorithms, covering 9 different task forms. DavarOCR provides detailed usage instructions and the trained models for each algorithm. Compared with the previous opensource OCR toolbox, DavarOCR has relatively more complete support for the sub-tasks of the cutting-edge technology of document understanding. In order to promote the development and application of OCR technology in academia and industry, we pay more attention to the use of modules that different sub-domains of technology can share. DavarOCR is publicly released at https://github.com/hikopensource/Davar-Lab-OCR.
MINER: Improving Out-of-Vocabulary Named Entity Recognition from an Information Theoretic Perspective
Apr 09, 2022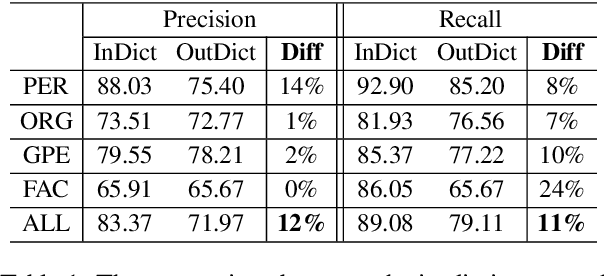
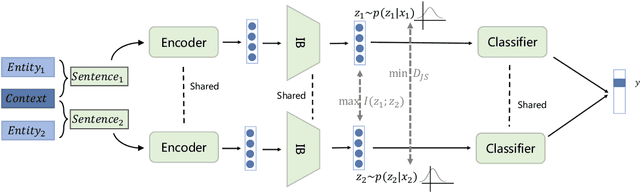
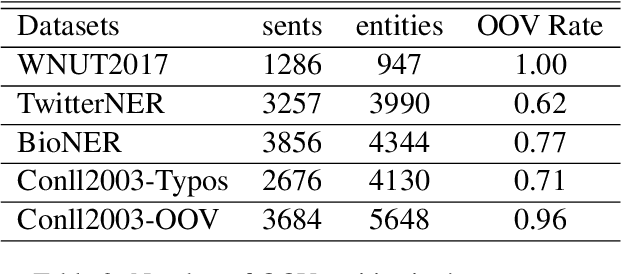
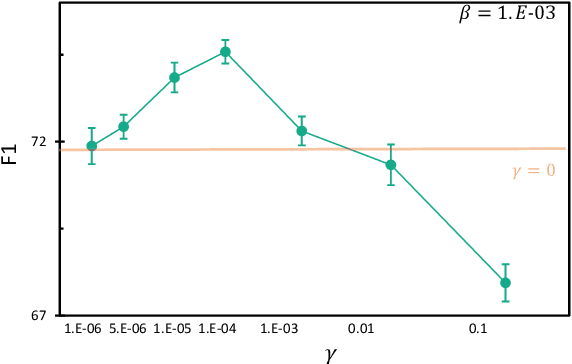
NER model has achieved promising performance on standard NER benchmarks. However, recent studies show that previous approaches may over-rely on entity mention information, resulting in poor performance on out-of-vocabulary (OOV) entity recognition. In this work, we propose MINER, a novel NER learning framework, to remedy this issue from an information-theoretic perspective. The proposed approach contains two mutual information-based training objectives: i) generalizing information maximization, which enhances representation via deep understanding of context and entity surface forms; ii) superfluous information minimization, which discourages representation from rote memorizing entity names or exploiting biased cues in data. Experiments on various settings and datasets demonstrate that it achieves better performance in predicting OOV entities.