 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Priors Guided Modulation Network for Joint Super-Resolution and Inverse Tone-Mapping
Aug 14, 2022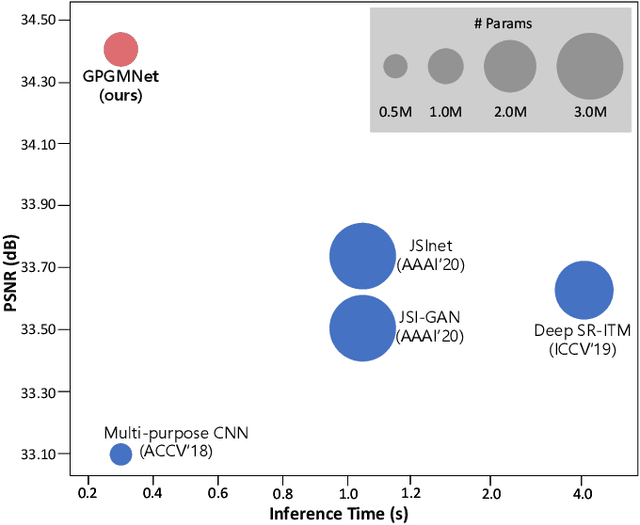
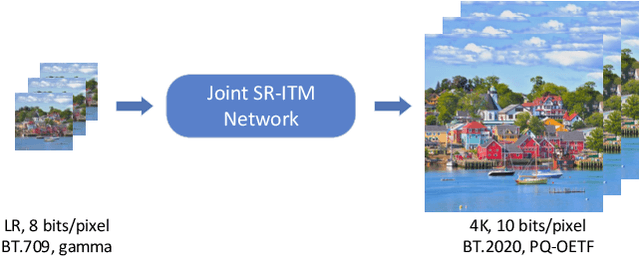
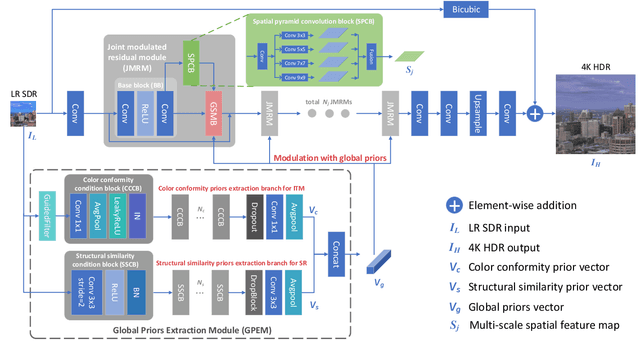
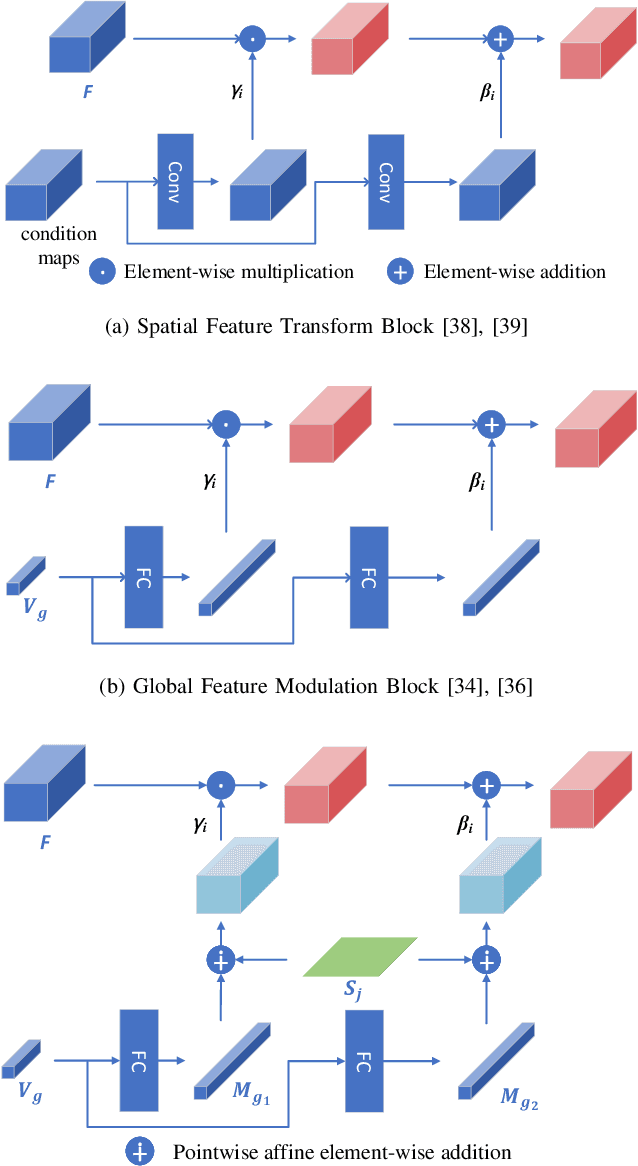
Joint super-resolution and inverse tone-mapping (SR-ITM) aims to enhance the visual quality of videos that have quality deficiencies in resolution and dynamic range. This problem arises when using 4K high dynamic range (HDR) TVs to watch a low-resolution standard dynamic range (LR SDR) video. Previous methods that rely on learning local information typically cannot do well in preserving color conformity and long-range structural similarity, resulting in unnatural color transition and texture artifacts. In order to tackle these challenges, we propose a global priors guided modulation network (GPGMNet) for joint SR-ITM. In particular, we design a global priors extraction module (GPEM) to extract color conformity prior and structural similarity prior that are beneficial for ITM and SR tasks, respectively. To further exploit the global priors and preserve spatial information, we devise multiple global priors guided spatial-wise modulation blocks (GSMBs) with a few parameters for intermediate feature modulation, in which the modulation parameters are generated by the shared global priors and the spatial features map from the spatial pyramid convolution block (SPCB). With these elaborate designs, the GPGMNet can achieve higher visual quality with lower computational complexity. Extensive experiments demonstrate that our proposed GPGMNet is superior to the state-of-the-art methods. Specifically, our proposed model exceeds the state-of-the-art by 0.64 dB in PSNR, with 69$\%$ fewer parameters and 3.1$\times$ speedup. The code will be released soon.
Meta Spatio-Temporal Debiasing for Video Scene Graph Generation
Jul 30, 2022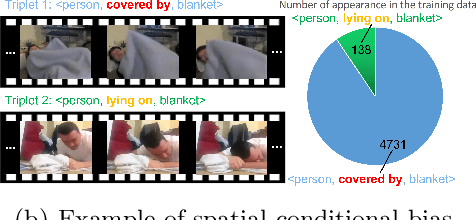
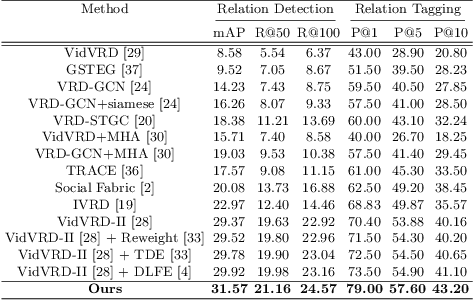
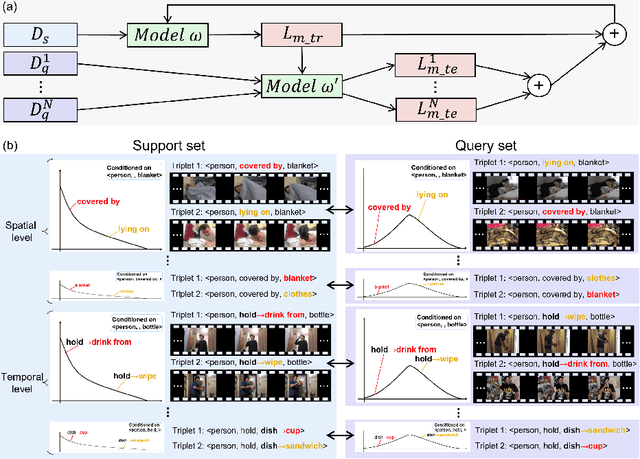

Video scene graph generation (VidSGG) aims to parse the video content into scene graphs, which involves modeling the spatio-temporal contextual information in the video. However, due to the long-tailed training data in datasets, the generalization performance of existing VidSGG models can be affected by the spatio-temporal conditional bias problem. In this work, from the perspective of meta-learning, we propose a novel Meta Video Scene Graph Generation (MVSGG) framework to address such a bias problem. Specifically, to handle various types of spatio-temporal conditional biases, our framework first constructs a support set and a group of query sets from the training data, where the data distribution of each query set is different from that of the support set w.r.t. a type of conditional bias. Then, by performing a novel meta training and testing process to optimize the model to obtain good testing performance on these query sets after training on the support set, our framework can effectively guide the model to learn to well generalize against biases. Extensive experiments demonstrate the efficacy of our proposed framework.
Linearization of a dual-parallel Mach-Zehnder modulator using optical carrier band processing
Jul 29, 2022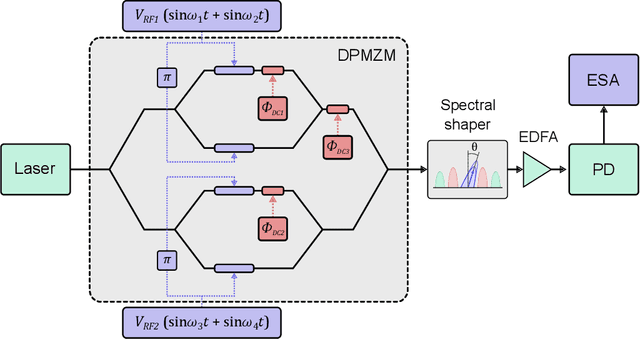
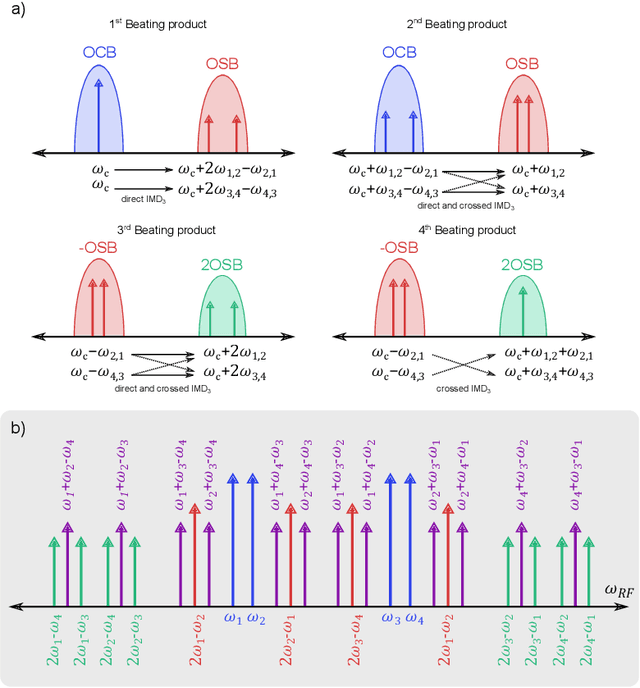
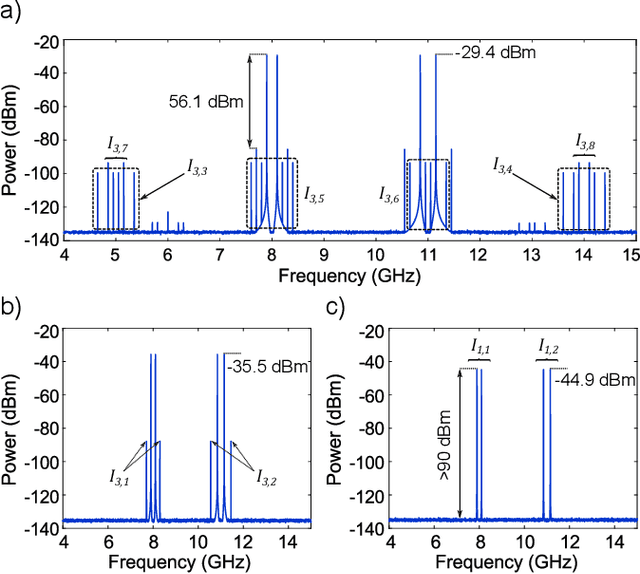
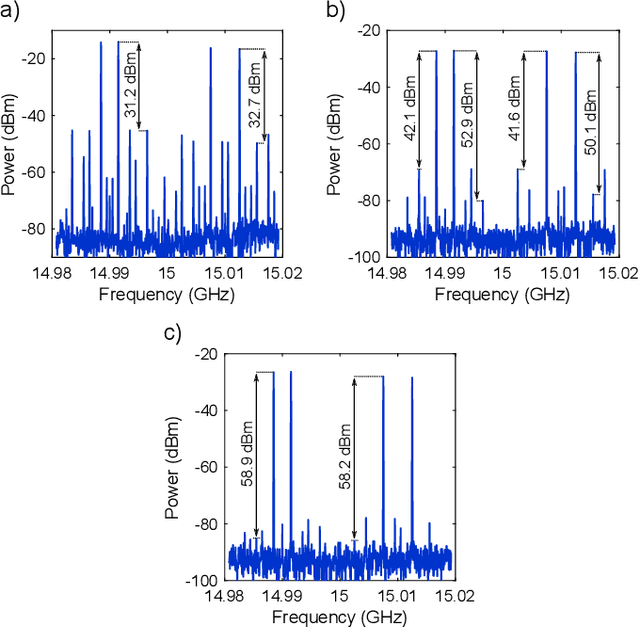
The linearization of a microwave photonic link based on a dual-parallel Mach-Zehnder modulator is theoretically described and experimentally demonstrated. Up to four different radio frequency tones are considered in the study, which allow us to provide a complete mathematical description of all third-order distortion terms that arise at the photodetector. Simulations show that a complete linearization is obtained by properly tuning the DC bias voltages and processing the optical carrier and. As a result, a suppression of 17 dBm is experimentally obtained for the third-order distortion terms, as well as a SDFR improvement of 3 dB. The proposed linearization method enables the simultaneous modulation of four different signals without the need of additional radio frequency components, which is desirable to its implementation in integrated optics and makes it suitable for several applications in microwave photonics.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022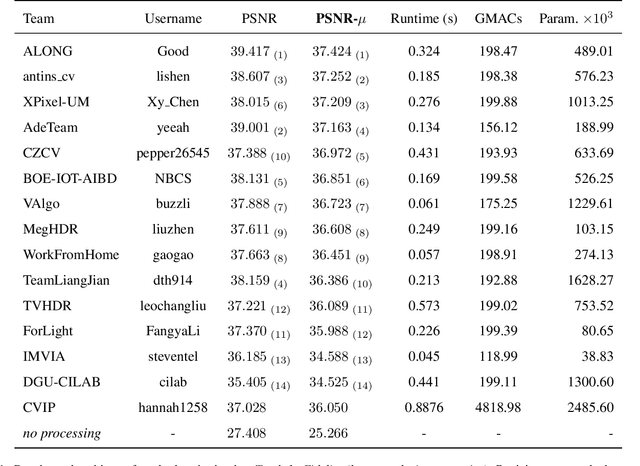
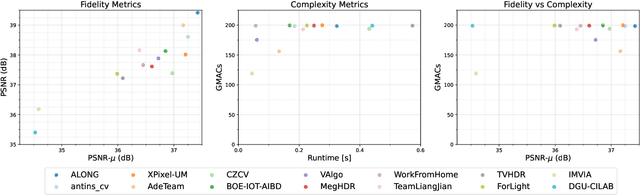
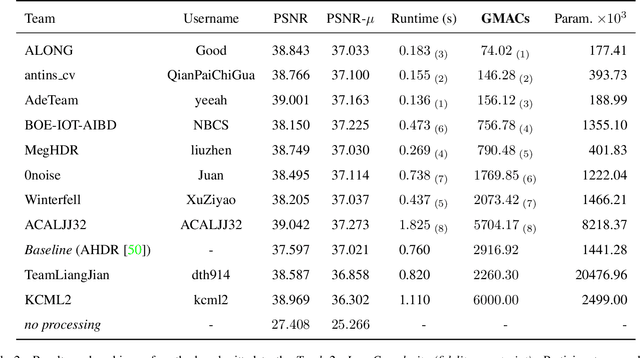
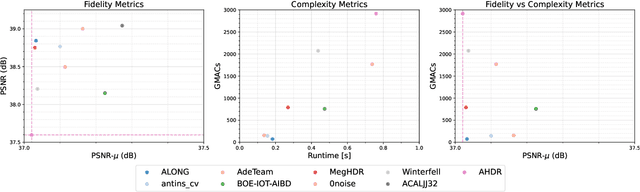
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Transcoded Video Restoration by Temporal Spatial Auxiliary Network
Dec 15, 2021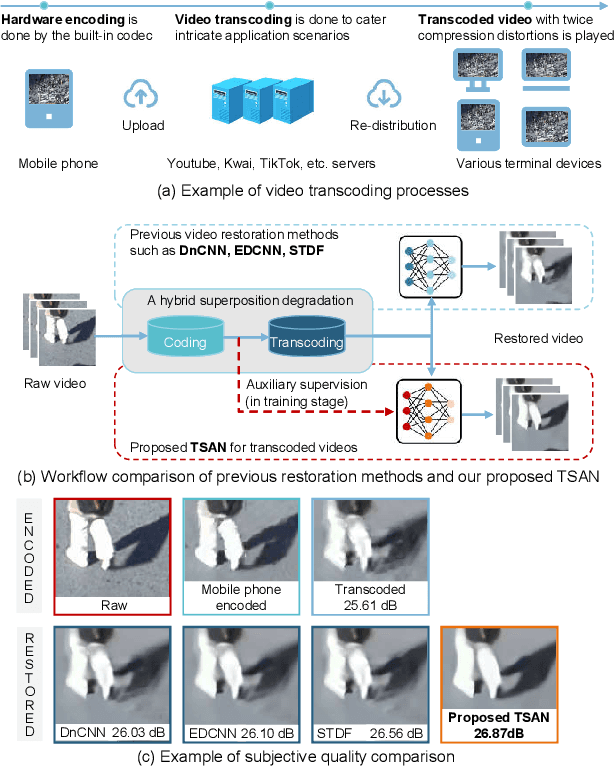
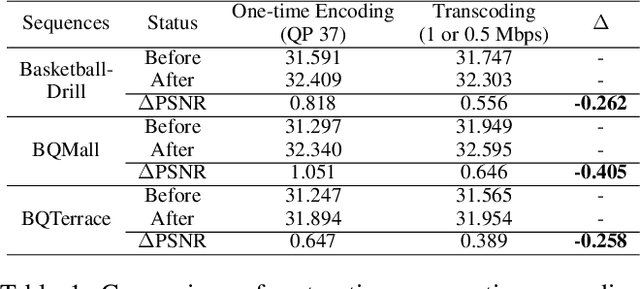
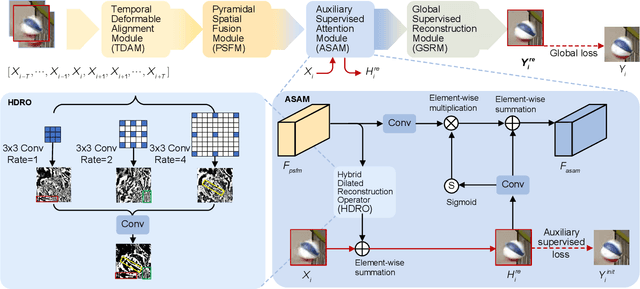

In most video platforms, such as Youtube, and TikTok, the played videos usually have undergone multiple video encodings such as hardware encoding by recording devices, software encoding by video editing apps, and single/multiple video transcoding by video application servers. Previous works in compressed video restoration typically assume the compression artifacts are caused by one-time encoding. Thus, the derived solution usually does not work very well in practice. In this paper, we propose a new method, temporal spatial auxiliary network (TSAN), for transcoded video restoration. Our method considers the unique traits between video encoding and transcoding, and we consider the initial shallow encoded videos as the intermediate labels to assist the network to conduct self-supervised attention training. In addition, we employ adjacent multi-frame information and propose the temporal deformable alignment and pyramidal spatial fusion for transcoded video restoration. The experimental results demonstrate that the performance of the proposed method is superior to that of the previous techniques. The code is available at https://github.com/icecherylXuli/TSAN.
Statistical Perspectives on Reliability of Artificial Intelligence Systems
Nov 09, 2021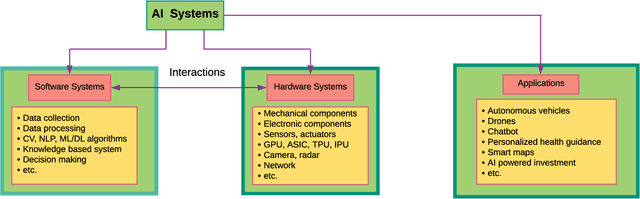
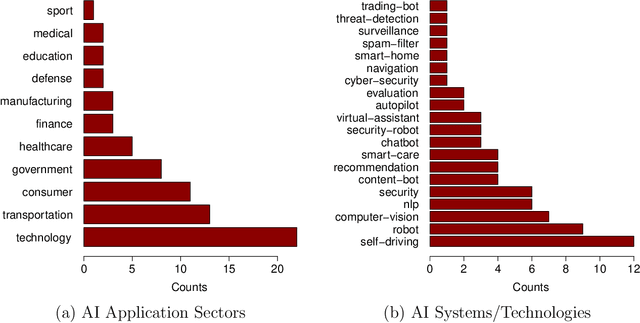
Artificial intelligence (AI) systems have become increasingly popular in many areas. Nevertheless, AI technologies are still in their developing stages, and many issues need to be addressed. Among those, the reliability of AI systems needs to be demonstrated so that the AI systems can be used with confidence by the general public. In this paper, we provide statistical perspectives on the reliability of AI systems. Different from other considerations, the reliability of AI systems focuses on the time dimension. That is, the system can perform its designed functionality for the intended period. We introduce a so-called SMART statistical framework for AI reliability research, which includes five components: Structure of the system, Metrics of reliability, Analysis of failure causes, Reliability assessment, and Test planning. We review traditional methods in reliability data analysis and software reliability, and discuss how those existing methods can be transformed for reliability modeling and assessment of AI systems. We also describe recent developments in modeling and analysis of AI reliability and outline statistical research challenges in this area, including out-of-distribution detection, the effect of the training set, adversarial attacks, model accuracy, and uncertainty quantification, and discuss how those topics can be related to AI reliability, with illustrative examples. Finally, we discuss data collection and test planning for AI reliability assessment and how to improve system designs for higher AI reliability. The paper closes with some concluding remarks.
Recent Advances of Continual Learning in Computer Vision: An Overview
Sep 24, 2021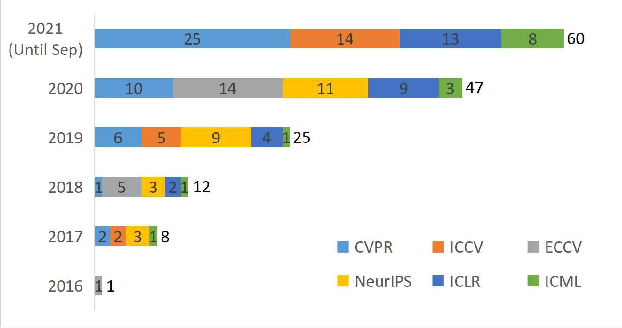

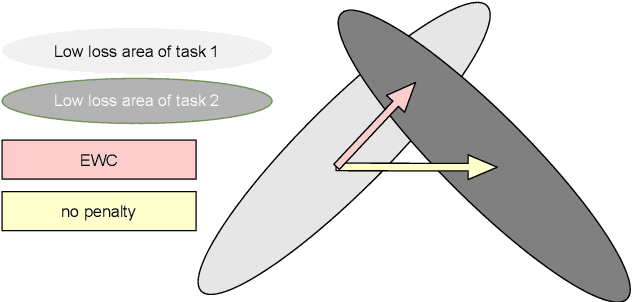
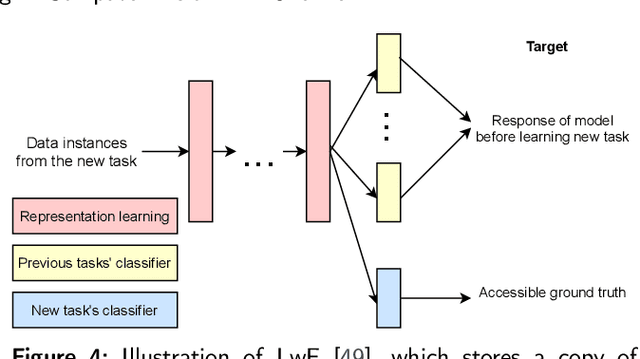
In contrast to batch learning where all training data is available at once, continual learning represents a family of methods that accumulate knowledge and learn continuously with data available in sequential order. Similar to the human learning process with the ability of learning, fusing, and accumulating new knowledge coming at different time steps, continual learning is considered to have high practical significance. Hence, continual learning has been studied in various artificial intelligence tasks. In this paper, we present a comprehensive review of the recent progress of continual learning in computer vision. In particular, the works are grouped by their representative techniques, including regularization, knowledge distillation, memory, generative replay, parameter isolation, and a combination of the above techniques. For each category of these techniques, both its characteristics and applications in computer vision are presented. At the end of this overview, several subareas, where continuous knowledge accumulation is potentially helpful while continual learning has not been well studied, are discussed.
The Multi-Modal Video Reasoning and Analyzing Competition
Aug 18, 2021



In this paper, we introduce the Multi-Modal Video Reasoning and Analyzing Competition (MMVRAC) workshop in conjunction with ICCV 2021. This competition is composed of four different tracks, namely, video question answering, skeleton-based action recognition, fisheye video-based action recognition, and person re-identification, which are based on two datasets: SUTD-TrafficQA and UAV-Human. We summarize the top-performing methods submitted by the participants in this competition and show their results achieved in the competition.
TrafficQA: A Question Answering Benchmark and an Efficient Network for Video Reasoning over Traffic Events
Mar 30, 2021

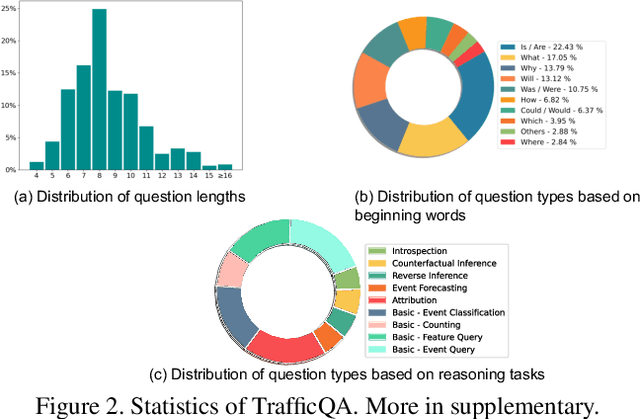
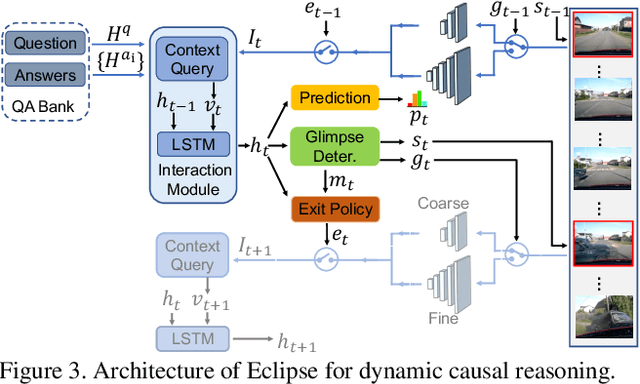
Traffic event cognition and reasoning in videos is an important task that has a wide range of applications in intelligent transportation, assisted driving, and autonomous vehicles. In this paper, we create a novel dataset, TrafficQA (Traffic Question Answering), which takes the form of video QA based on the collected 10,080 in-the-wild videos and annotated 62,535 QA pairs, for benchmarking the cognitive capability of causal inference and event understanding models in complex traffic scenarios. Specifically, we propose 6 challenging reasoning tasks corresponding to various traffic scenarios, so as to evaluate the reasoning capability over different kinds of complex yet practical traffic events. Moreover, we propose Eclipse, a novel Efficient glimpse network via dynamic inference, in order to achieve computation-efficient and reliable video reasoning. The experiments show that our method achieves superior performance while reducing the computation cost significantly. The project page: https://github.com/SUTDCV/SUTD-TrafficQA.
SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering
Feb 18, 2021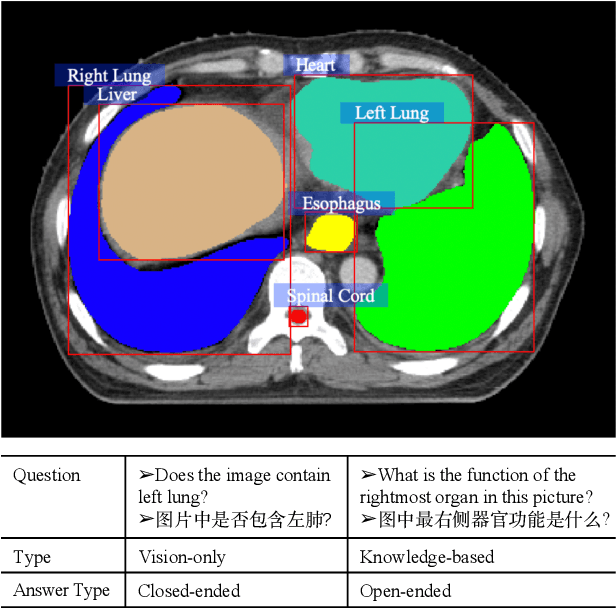

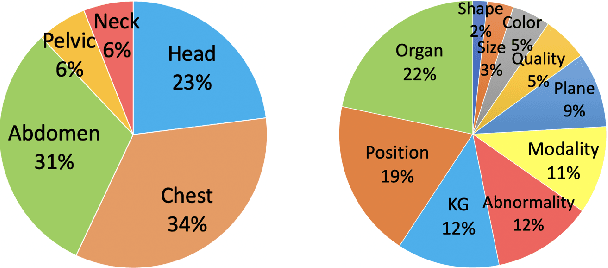
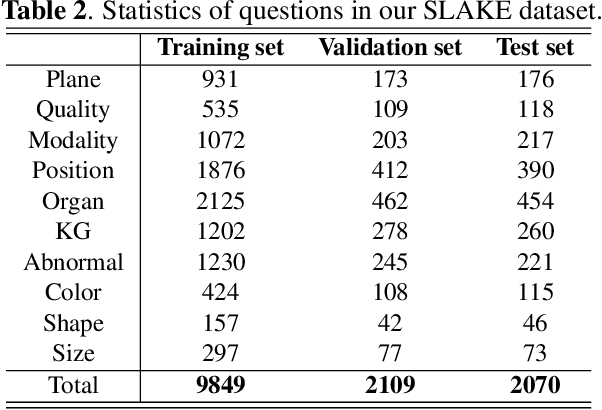
Medical visual question answering (Med-VQA) has tremendous potential in healthcare. However, the development of this technology is hindered by the lacking of publicly-available and high-quality labeled datasets for training and evaluation. In this paper, we present a large bilingual dataset, SLAKE, with comprehensive semantic labels annotated by experienced physicians and a new structural medical knowledge base for Med-VQA. Besides, SLAKE includes richer modalities and covers more human body parts than the currently available dataset. We show that SLAKE can be used to facilitate the development and evaluation of Med-VQA systems. The dataset can be downloaded from http://www.med-vqa.com/slake.