 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEART-Bench: Do LLM Agents Exhibit Human-like Psychology?
May 28, 2026While LLM agents have demonstrated remarkable task-oriented abilities such as planning, reasoning, and action, few works have treated them as complete human personalities where emotional dimensions hold equal importance. In this paper, we introduce a novel benchmark to systematically assess whether LLM agents can simulate coherent, human-like psychology. Specifically, our benchmark constructs 11 diverse human characters grounded in orthogonal Big Five personality traits, with each profile deeply integrated with 1,000 structured autobiographical-style episodic memories distributed across theory-grounded developmental life stages. To rigorously evaluate the psychological manifestations of LLMs, we designed a curated suite of 64 decision-making scenarios, guided by the DIAMONDS taxonomy, a psychological framework that characterizes situations along eight dimensions: Duty, Intellect, Adversity, Mating, pOsitivity, Negativity, Deception, and Sociality. By subjecting agents to varying scenarios, the benchmark evaluates whether they can consolidate their innate personality traits and autobiographical memories to make behavioral decisions that are consistent with their specific psychological profiles. After systematic human validation and filtering, we obtained a benchmark consisting of 673 multiple-choice questions (MCQs). We believe this benchmark provides a principled and scalable testbed for studying human-like emotions, personality consistency, and value-consistent behavioural decision-making in LLM-based agents.
EntropyGS: An Efficient Entropy Coding on 3D Gaussian Splatting
Aug 13, 2025
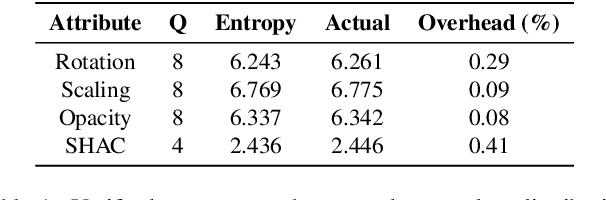
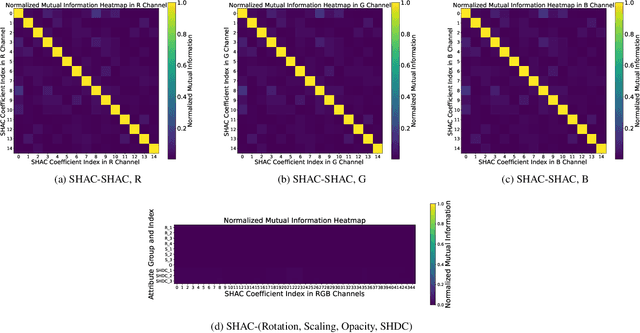
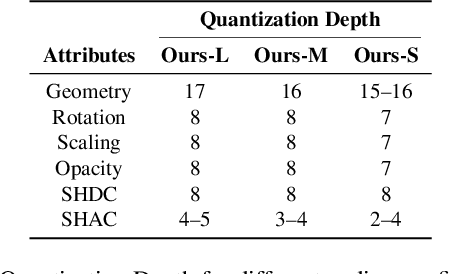
As an emerging novel view synthesis approach, 3D Gaussian Splatting (3DGS) demonstrates fast training/rendering with superior visual quality. The two tasks of 3DGS, Gaussian creation and view rendering, are typically separated over time or devices, and thus storage/transmission and finally compression of 3DGS Gaussians become necessary. We begin with a correlation and statistical analysis of 3DGS Gaussian attributes. An inspiring finding in this work reveals that spherical harmonic AC attributes precisely follow Laplace distributions, while mixtures of Gaussian distributions can approximate rotation, scaling, and opacity. Additionally, harmonic AC attributes manifest weak correlations with other attributes except for inherited correlations from a color space. A factorized and parameterized entropy coding method, EntropyGS, is hereinafter proposed. During encoding, distribution parameters of each Gaussian attribute are estimated to assist their entropy coding. The quantization for entropy coding is adaptively performed according to Gaussian attribute types. EntropyGS demonstrates about 30x rate reduction on benchmark datasets while maintaining similar rendering quality compared to input 3DGS data, with a fast encoding and decoding time.
Towards Reproducible Learning-based Compression
Oct 13, 2024



A deep learning system typically suffers from a lack of reproducibility that is partially rooted in hardware or software implementation details. The irreproducibility leads to skepticism in deep learning technologies and it can hinder them from being deployed in many applications. In this work, the irreproducibility issue is analyzed where deep learning is employed in compression systems while the encoding and decoding may be run on devices from different manufacturers. The decoding process can even crash due to a single bit difference, e.g., in a learning-based entropy coder. For a given deep learning-based module with limited resources for protection, we first suggest that reproducibility can only be assured when the mismatches are bounded. Then a safeguarding mechanism is proposed to tackle the challenges. The proposed method may be applied for different levels of protection either at the reconstruction level or at a selected decoding level. Furthermore, the overhead introduced for the protection can be scaled down accordingly when the error bound is being suppressed. Experiments demonstrate the effectiveness of the proposed approach for learning-based compression systems, e.g., in image compression and point cloud compression.
PIVOT-Net: Heterogeneous Point-Voxel-Tree-based Framework for Point Cloud Compression
Feb 11, 2024



The universality of the point cloud format enables many 3D applications, making the compression of point clouds a critical phase in practice. Sampled as discrete 3D points, a point cloud approximates 2D surface(s) embedded in 3D with a finite bit-depth. However, the point distribution of a practical point cloud changes drastically as its bit-depth increases, requiring different methodologies for effective consumption/analysis. In this regard, a heterogeneous point cloud compression (PCC) framework is proposed. We unify typical point cloud representations -- point-based, voxel-based, and tree-based representations -- and their associated backbones under a learning-based framework to compress an input point cloud at different bit-depth levels. Having recognized the importance of voxel-domain processing, we augment the framework with a proposed context-aware upsampling for decoding and an enhanced voxel transformer for feature aggregation. Extensive experimentation demonstrates the state-of-the-art performance of our proposal on a wide range of point clouds.
WrappingNet: Mesh Autoencoder via Deep Sphere Deformation
Aug 29, 2023



There have been recent efforts to learn more meaningful representations via fixed length codewords from mesh data, since a mesh serves as a complete model of underlying 3D shape compared to a point cloud. However, the mesh connectivity presents new difficulties when constructing a deep learning pipeline for meshes. Previous mesh unsupervised learning approaches typically assume category-specific templates, e.g., human face/body templates. It restricts the learned latent codes to only be meaningful for objects in a specific category, so the learned latent spaces are unable to be used across different types of objects. In this work, we present WrappingNet, the first mesh autoencoder enabling general mesh unsupervised learning over heterogeneous objects. It introduces a novel base graph in the bottleneck dedicated to representing mesh connectivity, which is shown to facilitate learning a shared latent space representing object shape. The superiority of WrappingNet mesh learning is further demonstrated via improved reconstruction quality and competitive classification compared to point cloud learning, as well as latent interpolation between meshes of different categories.
GRASP-Net: Geometric Residual Analysis and Synthesis for Point Cloud Compression
Sep 09, 2022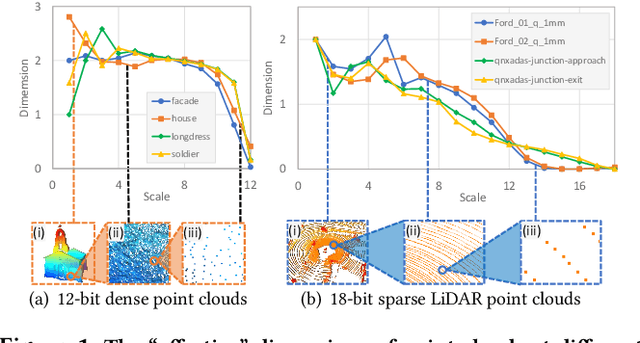

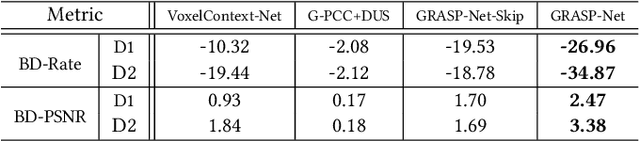
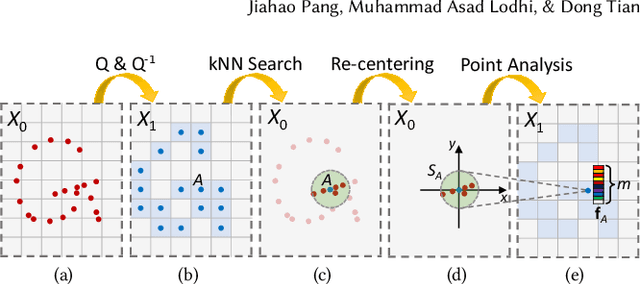
Point cloud compression (PCC) is a key enabler for various 3-D applications, owing to the universality of the point cloud format. Ideally, 3D point clouds endeavor to depict object/scene surfaces that are continuous. Practically, as a set of discrete samples, point clouds are locally disconnected and sparsely distributed. This sparse nature is hindering the discovery of local correlation among points for compression. Motivated by an analysis with fractal dimension, we propose a heterogeneous approach with deep learning for lossy point cloud geometry compression. On top of a base layer compressing a coarse representation of the input, an enhancement layer is designed to cope with the challenging geometric residual/details. Specifically, a point-based network is applied to convert the erratic local details to latent features residing on the coarse point cloud. Then a sparse convolutional neural network operating on the coarse point cloud is launched. It utilizes the continuity/smoothness of the coarse geometry to compress the latent features as an enhancement bit-stream that greatly benefits the reconstruction quality. When this bit-stream is unavailable, e.g., due to packet loss, we support a skip mode with the same architecture which generates geometric details from the coarse point cloud directly. Experimentation on both dense and sparse point clouds demonstrate the state-of-the-art compression performance achieved by our proposal. Our code is available at https://github.com/InterDigitalInc/GRASP-Net.
Graph-Based Depth Denoising & Dequantization for Point Cloud Enhancement
Nov 09, 2021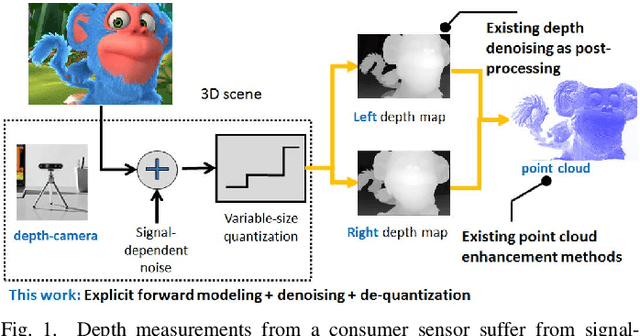
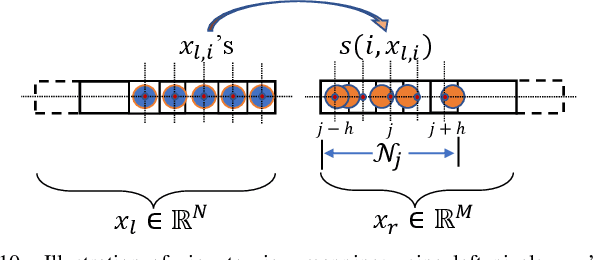
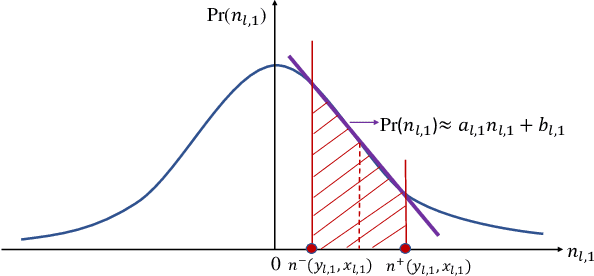
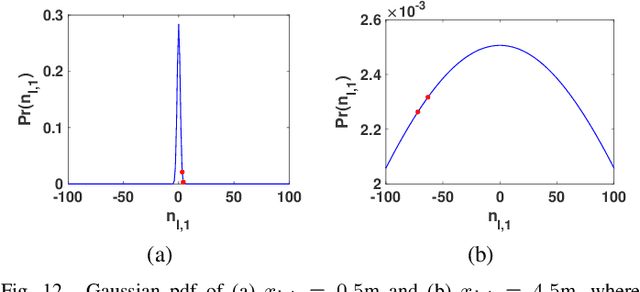
A 3D point cloud is typically constructed from depth measurements acquired by sensors at one or more viewpoints. The measurements suffer from both quantization and noise corruption. To improve quality, previous works denoise a point cloud \textit{a posteriori} after projecting the imperfect depth data onto 3D space. Instead, we enhance depth measurements directly on the sensed images \textit{a priori}, before synthesizing a 3D point cloud. By enhancing near the physical sensing process, we tailor our optimization to our depth formation model before subsequent processing steps that obscure measurement errors. Specifically, we model depth formation as a combined process of signal-dependent noise addition and non-uniform log-based quantization. The designed model is validated (with parameters fitted) using collected empirical data from an actual depth sensor. To enhance each pixel row in a depth image, we first encode intra-view similarities between available row pixels as edge weights via feature graph learning. We next establish inter-view similarities with another rectified depth image via viewpoint mapping and sparse linear interpolation. This leads to a maximum a posteriori (MAP) graph filtering objective that is convex and differentiable. We optimize the objective efficiently using accelerated gradient descent (AGD), where the optimal step size is approximated via Gershgorin circle theorem (GCT). Experiments show that our method significantly outperformed recent point cloud denoising schemes and state-of-the-art image denoising schemes, in two established point cloud quality metrics.
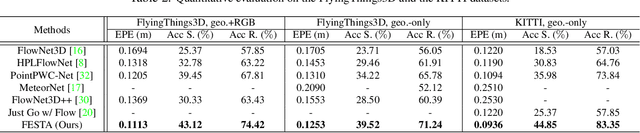
FESTA: Flow Estimation via Spatial-Temporal Attention for Scene Point Clouds
Apr 01, 2021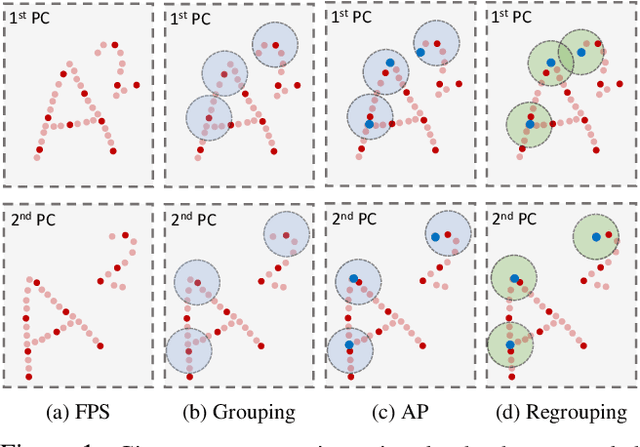
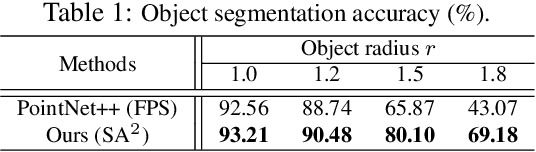
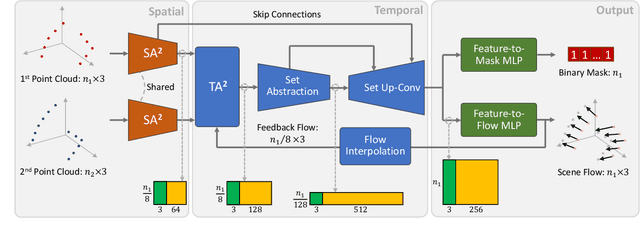
Scene flow depicts the dynamics of a 3D scene, which is critical for various applications such as autonomous driving, robot navigation, AR/VR, etc. Conventionally, scene flow is estimated from dense/regular RGB video frames. With the development of depth-sensing technologies, precise 3D measurements are available via point clouds which have sparked new research in 3D scene flow. Nevertheless, it remains challenging to extract scene flow from point clouds due to the sparsity and irregularity in typical point cloud sampling patterns. One major issue related to irregular sampling is identified as the randomness during point set abstraction/feature extraction -- an elementary process in many flow estimation scenarios. A novel Spatial Abstraction with Attention (SA^2) layer is accordingly proposed to alleviate the unstable abstraction problem. Moreover, a Temporal Abstraction with Attention (TA^2) layer is proposed to rectify attention in temporal domain, leading to benefits with motions scaled in a larger range. Extensive analysis and experiments verified the motivation and significant performance gains of our method, dubbed as Flow Estimation via Spatial-Temporal Attention (FESTA), when compared to several state-of-the-art benchmarks of scene flow estimation.
Graph Signal Processing for Geometric Data and Beyond: Theory and Applications
Aug 05, 2020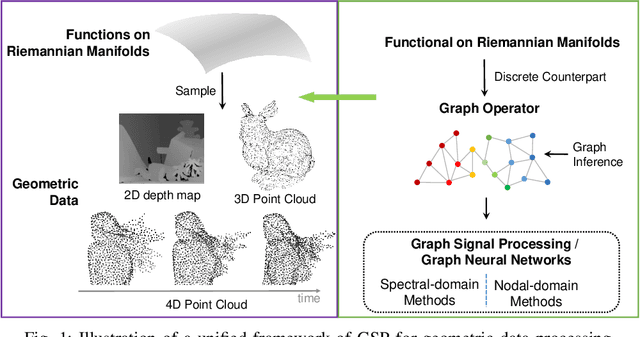
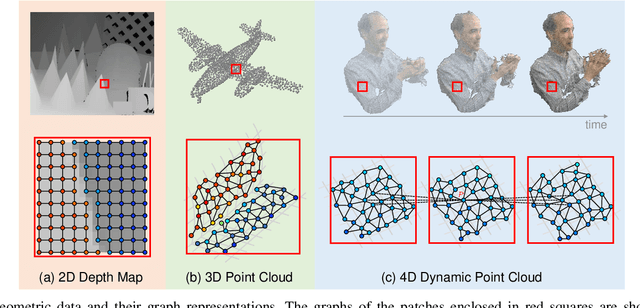


Geometric data acquired from real-world scenes, e.g., 2D depth images, 3D point clouds, and 4D dynamic point clouds, have found a wide range of applications including immersive telepresence, autonomous driving, surveillance, etc. Due to irregular sampling patterns of most geometric data, traditional image/video processing methodologies are limited, while Graph Signal Processing (GSP)---a fast-developing field in the signal processing community---enables processing signals that reside on irregular domains and plays a critical role in numerous applications of geometric data from low-level processing to high-level analysis. To further advance the research in this field, we provide the first timely and comprehensive overview of GSP methodologies for geometric data in a unified manner by bridging the connections between geometric data and graphs, among the various geometric data modalities, and with spectral/nodal graph filtering techniques. We also discuss the recently developed Graph Neural Networks (GNNs) and interpret the operation of these networks from the perspective of GSP. We conclude with a brief discussion of open problems and challenges.
TearingNet: Point Cloud Autoencoder to Learn Topology-Friendly Representations
Jun 17, 2020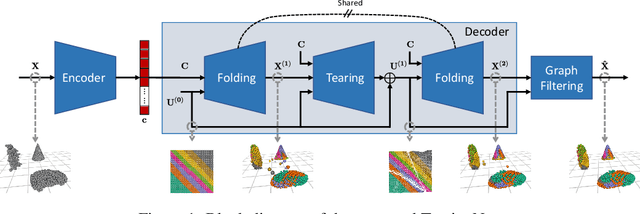

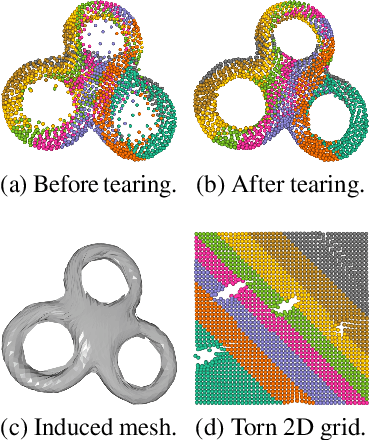
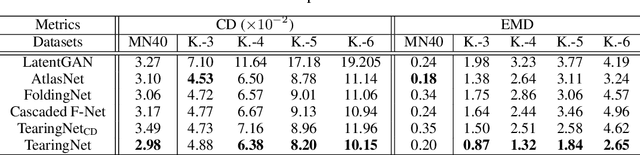
Topology matters. Despite the recent success of point cloud processing with geometric deep learning, it remains arduous to capture the complex topologies of point cloud data with a learning model. Given a point cloud dataset containing objects with various genera or scenes with multiple objects, we propose an autoencoder, TearingNet, which tackles the challenging task of representing the point clouds using a fixed-length descriptor. Unlike existing works to deform primitives of genus zero (e.g., a 2D square patch) to an object-level point cloud, we propose a function which tears the primitive during deformation, letting it emulate the topology of a target point cloud. From the torn primitive, we construct a locally-connected graph to further enforce the learned topology via filtering. Moreover, we analyze a widely existing problem which we call point-collapse when processing point clouds with diverse topologies. Correspondingly, we propose a subtractive sculpture strategy to train our TearingNet model. Experimentation finally shows the superiority of our proposal in terms of reconstructing more faithful point clouds as well as generating more topology-friendly representations than benchmarks.